Abstract
이 연구에서는 70억에서 700억 parameter 규모의 사전 학습 및 미세 조정된 대규모 언어 모델 모음인 Llama 2를 개발하고 출시하였다. 대화 사용 사례에 특화된 Llama 2-Chat은 테스트한 대부분의 벤치마크에서 오픈 소스 채팅 모델보다 우수하며, 유용성과 안전성 측면에서 폐쇄 소스 모델의 대안이 될 수 있다. Llama 2-Chat의 미세 조정 및 안전성 개선 방법을 자세히 소개해, 커뮤니티가 이를 기반으로 LLMs의 책임 있는 개발에 기여할 수 있게 한다.
Introduction
대규모 언어 모델(LLMs)은 전문 지식이 필요한 다양한 분야에서 탁월한 AI 보조자 역할을 하며, 직관적인 채팅 인터페이스를 통한 인간과의 상호 작용으로 일반 대중에게 빠르게 널리 퍼졌다.
LLM의 학습 방법은 단순하지만, 고도의 계산 요구로 개발자가 제한된다. 사전 학습된 LLM들(BLOOM, LLaMa-1, Falcon 등)은 공개되었으나, 인간의 선호에 맞춰 미세 조정된 폐쇄된 제품 LLM들(GPT-3, ChatGPT 등)과는 다르다. 이러한 미세 조정은 사용성과 안전성을 높이지만, 높은 계산 비용과 주석 작업이 필요하며, 종종 투명하지 않아 AI alignment 연구의 커뮤니티 진보를 제한한다.
이 연구에서는 최대 70B parameter 규모의 사전 학습 및 미세 조정된 LLM, Llama 2와 Llama 2-Chat을 개발하고 공개하였다. 이 모델들은 유용성과 안전성 벤치마크에서 기존 오픈 소스 모델보다 우수하며, 일부 폐쇄 소스 모델과도 비슷한 수준이다. 모델의 안전성을 높이기 위해 특정 데이터 주석, 레드 팀 활동 및 반복 평가 등의 조치를 취하였다. 또한, 미세 조정 방법론과 안전성 향상 접근법을 상세히 설명하여, 커뮤니티가 이를 재현하고 안전성을 개선할 수 있는 기반을 마련하였다. 개발 과정에서 도구 사용의 등장과 지식의 시간적 조직과 같은 새로운 관찰 결과도 공유하였다.
다음 모델들을 일반 대중에게 연구 및 상업적 용도로 공개한다:
- Llama 2 공개 데이터로 학습된 Llama 1의 업데이트 버전과 사전 학습 코퍼스를 40% 확장, 모델 컨텍스트 길이 2배 증가, 그룹화된 쿼리 주의 기법 적용 하였다. 7B, 13B, 70B parameter를 가진 Llama 2 변형을 공개하며, 34B 변형은 연구 결과로만 보고하고 공개하지 않는다.
- Llama 2-Chat 대화에 최적화된 Llama 2 미세 조정 버전을 7B, 13B, 70B parameter로 공개한다.
LLM의 안전한 공개는 사회에 이로울 것이라고 보며, 모든 LLM, 특히 Llama 2는 사용 시 잠재적 위험을 지닌다. 실시된 테스트는 모든 시나리오를 포괄하지 못하였다. 따라서 Llama 2-Chat의 응용 프로그램을 배포하기 전에 개발자는 모델의 특정 사용 사례에 맞는 안전 테스팅과 조정을 해야 한다.
Pretraining
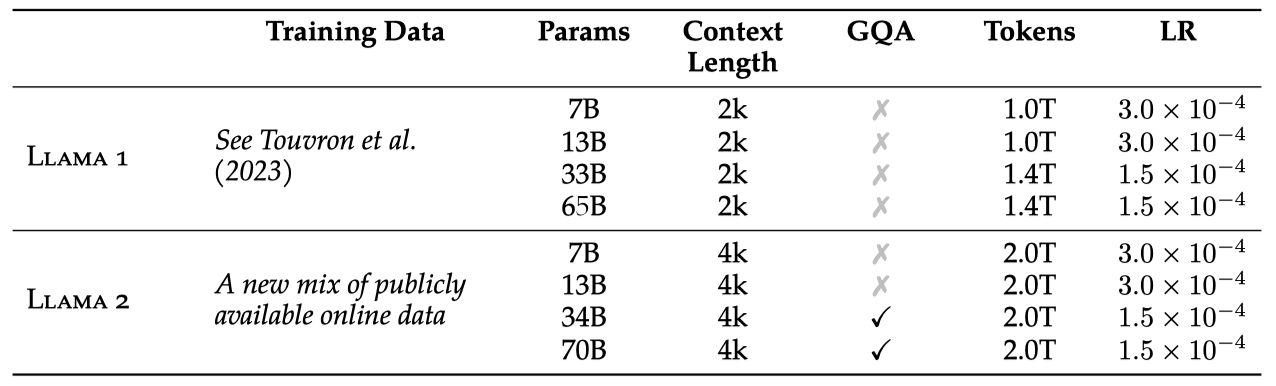
새로운 Llama 2 모델 개발을 위해, Touvron et al. (2023)의 사전 학습 방식을 기반으로 하여 성능 개선을 위한 여러 변경을 적용하였다. 이에는 강화된 데이터 클리닝, 데이터 혼합 업데이트, 총 토큰 수 40% 증가, 컨텍스트 길이 2배 확장, 그리고 큰 모델의 추론 확장성 향상을 위한 그룹화된 쿼리 주의(GQA) 사용이 포함된다.
Pretraining Data
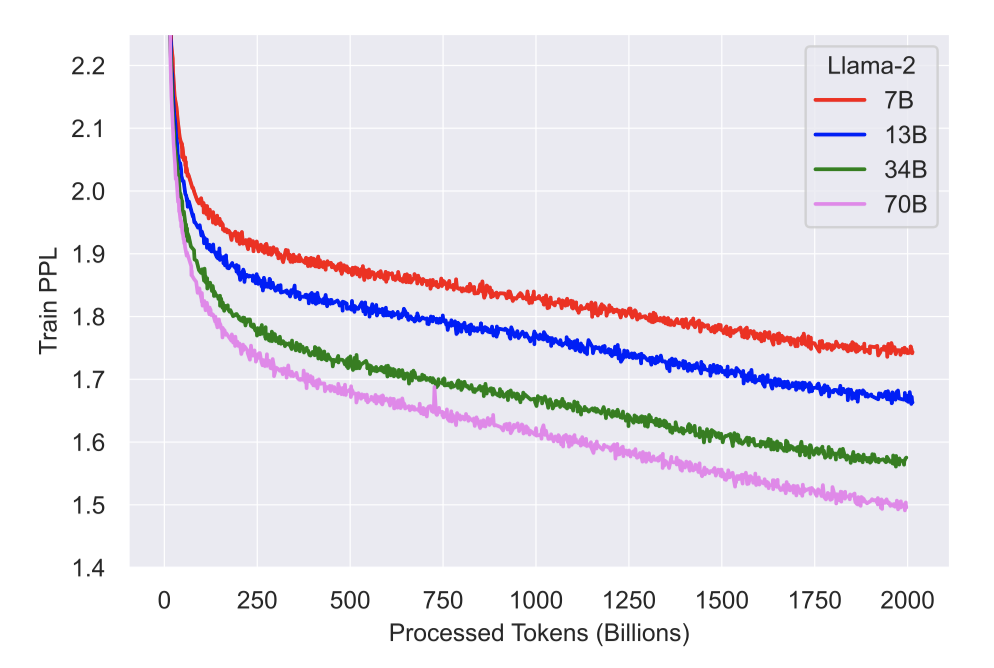
공개 소스에서 새로운 데이터를 포함시키고, 개인 정보가 많은 사이트의 데이터는 제외하였다. 2 trillion 토큰을 학습 데이터로 사용하여 최적의 성능과 비용 효율을 달성하고, 가장 정확한 소스를 중점적으로 활용해 지식을 확장하고 오류를 최소화하였다.
모델의 능력과 한계를 파악하기 위해 다양한 사전 학습 데이터 조사를 진행하였다.
Training Details
Llama 1의 설정과 구조를 대부분 따르면서, standard transformer 구조와 특정 기술들을 적용하였다. 주된 차이점은 컨텍스트 길이 확장과 grouped-query attention (GQA)이다.
Hyperparameters. AdamW optimizer로 β1=0.9, β2=0.95, eps=$10^{-5}$ 설정하고, cosine learning rate 일정에 따라 2000 step 웜업 후 최종 learning rate를 최고의 10%로 감소시켰다. weight decay는 0.1, gradient clipping은 1.0을 적용하였다.
Tokenizer. Llama 1과 같은 토크나이저를 사용하며, 이는 SentencePiece 구현의 BPE 알고리즘을 기반으로 한다. 모든 숫자를 분리하고 알려지지 않은 UTF-8 문자를 바이트로 분해한다. 어휘 크기는 총 32k 토큰이다.
Training Hardware & Carbon Footprint
Training Hardware. Meta의 RSC와 내부 생산 클러스터에서 모델을 사전 학습하였다. 두 클러스터는 NVIDIA A100을 사용하며, 주요 차이는 interconnect 유형과 GPU당 전력 소비이다. RSC는 NVIDIA Quantum InfiniBand와 400W를, 생산 클러스터는 RoCE 솔루션과 350W를 사용한다. 이를 통해 다양한 interconnect의 대규모 학습 적합성을 비교했으며, RoCE는 2000 GPU까지 인피니밴드와 유사한 확장성을 보이며 사전 학습을 더 접근하기 쉽게 한다.
Carbon Footprint of Pretraining. 이전 연구를 바탕으로, Llama 2 모델 사전 학습의 탄소 배출량을 GPU 전력 소비와 탄소 효율성을 통해 계산하려 한다. 실제 GPU 전력 사용량은 추정치인 TDP와 다를 수 있으며, 계산에는 interconnect, non-GPU 서버 및 데이터센터 냉각 시스템의 전력 수요는 포함되지 않는다. 또한, AI 하드웨어 생산으로 인한 탄소 배출도 전체 탄소 발자국에 영향을 줄 수 있다.
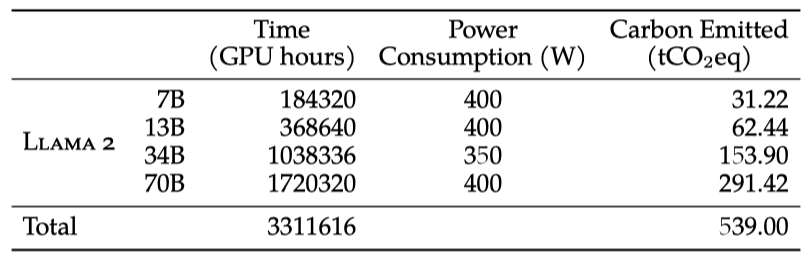
학습으로 발생한 539 tCO2 eq의 탄소 배출은 Meta의 지속 가능성 프로그램을 통해 100% 상쇄되었다. 또한, 오픈 릴리스 전략으로 인해 다른 회사들이 이 비용을 부담하지 않아도 되어 글로벌 자원이 절약된다.
Llama 2 Pretrained Model Evaluation
이 섹션에서는 Llama 1, Llama 2, MosaicML Pretrained Transformer(MPT), 그리고 Falcon 모델의 표준 학술 벤치마크 결과를 보고한다. 모든 평가는 내부 평가 라이브러리를 통해 이루어졌으며, MPT와 Falcon 모델 결과는 내부적으로 재현하였다. 평가 시, 공개 결과와 내부 평가 중 더 높은 점수를 선택한다.
- Code. HumanEval과 MBPP에서 모델의 평균 pass@1 점수를 보고한다.
- Commonsense Reasoning. PIQA, SIQA, HellaSwag, WinoGrande, ARC, OpenBookQA, CommonsenseQA의 평균을 보고한다. CommonsenseQA는 7-shot, 나머지는 0-shot 결과이다.
- World Knowledge. NaturalQuestions과 TriviaQA에서 5-shot 성능의 평균을 보고한다.
- Reading Comprehension. SQuAD, QuAC, BoolQ에서 0-shot 평균을 보고한다.
- MATH. GSM8K(8 shot)과 MATH(4 shot) 벤치마크의 top 1 평균을 보고한다.
- Popular Aggregated Benchmarks. MMLU(5 shot), BBH(3 shot), AGI Eval(3–5 shot)의 전체 결과를 보고하며, AGI Eval은 영어 작업에 한해 평균을 보고한다.
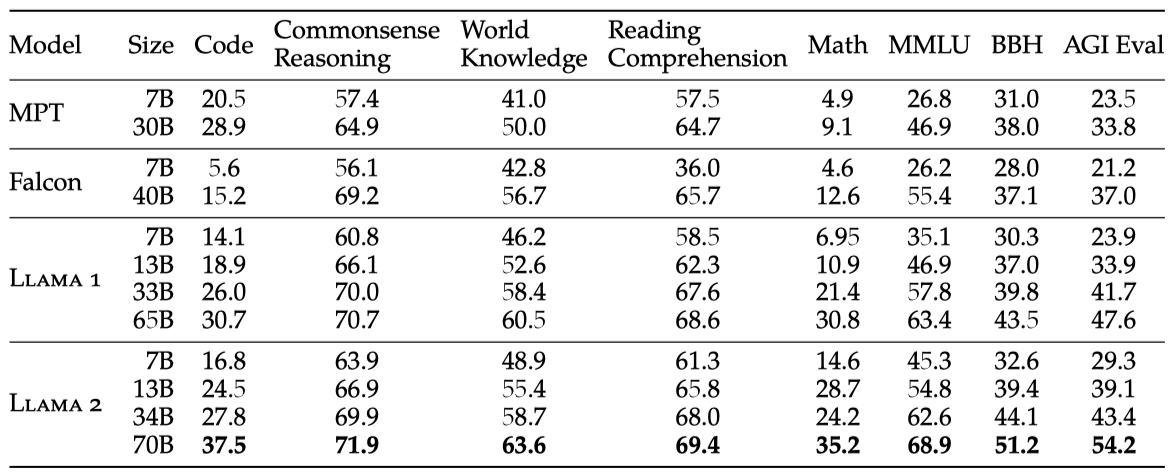
Llama 2 70B는 MMLU와 BBH에서 Llama 1 65B보다 각각 약 5점, 8점 향상되었다. Llama 2 7B와 30B는 코드 벤치마크를 제외한 모든 부문에서 같은 크기의 MPT 모델들을 초과한다. Falcon 모델 비교에서도 Llama 2 7B와 34B가 모든 벤치마크에서 Falcon 7B와 40B를 능가한다. 또한, Llama 2 70B는 모든 오픈 소스 모델 중 가장 성능이 뛰어나다.
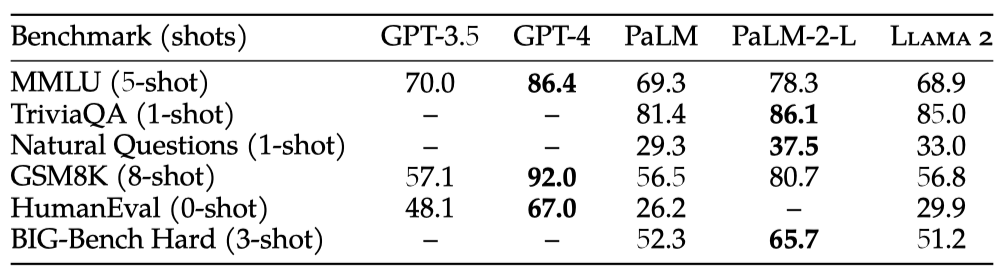
Llama 2 70B는 비공개 소스 모델과 비교하여 MMLU와 GSM8K에서 GPT-3.5와 유사하나 코딩 벤치마크에서는 격차가 있다. 대부분의 벤치마크에서 PaLM(540B)과 비슷하거나 더 나은 성능을 보이지만, GPT-4 및 PaLM-2-L과는 여전히 큰 성능 차이가 있다.
Fine-tuning
Llama 2-Chat은 몇 달 간의 연구와 instruction tuning, RLHF 등의 조정 기술 적용을 통해 개발되었으며, 이 과정에는 많은 계산 및 주석 리소스가 필요하였다.
이 섹션에서는 supervised fine-tuning, reward modeling, RLHF를 통한 실험과 발견, 그리고 대화 흐름 제어를 위한 새로운 기술인 Ghost Attention(GAtt)에 대해 설명한다.
Supervised Fine-Tuning (SFT)
Getting Started. 부트스트랩을 위해, 공개된 지시 조정 데이터(Chung et al., 2022)로 SFT 단계를 시작했으며, 이는 Touvron et al. (2023)에서도 활용된 방법이다.

Quality Is All You Need. 제3자 SFT 데이터의 다양성과 품질 부족을 발견한 후, 고품질 SFT 데이터 수천 개를 집중적으로 수집하였다. 제3자 데이터셋의 수백만 예시 대신, 적은 양의 고품질 벤더 기반 데이터를 사용해 결과가 크게 개선되었다. 이는 제한된 양의 깨끗한 지시 조정 데이터로도 높은 품질을 달성할 수 있다는 Zhou et al. (2023)의 발견과 유사하다. 총 27,540개의 고품질 SFT 주석을 수집한 뒤 주석 작업을 중단했으며, 메타 사용자 데이터는 사용하지 않았다.
다양한 주석 플랫폼과 벤더 사용 결과, 모델 성능에 큰 차이가 있음을 확인하였다. 이는 벤더를 통한 주석 수집 시 데이터 검증의 중요성을 나타낸다. 180개 예시를 통한 데이터 품질 검증에서, SFT 모델의 출력이 인간 주석자의 데이터와 경쟁력이 있음을 발견했으며, 이는 RLHF를 위한 선호도 기반 주석에 더 많은 노력을 할애할 수 있음을 시사한다.
Fine-Tuning Details. supervised 미세조정을 위해, initial learning rate $2 × 10^{-5}$, weight decay 0.1, batch size 64, sequence length 4096 토큰의 cosine learning rate 일정을 적용한다.
미세 조정 과정에서, 프롬프트와 답변을 연결하고 특수 토큰으로 구분한다. 사용자 프롬프트의 손실을 제거하고 답변 토큰에만 backpropagate를 적용하여, 모델을 2 epoch 동안 미세 조정한다.
Reinforcement Learning with Human Feedback (RLHF)
RLHF는 언어 모델을 더욱 인간의 선호와 지시에 맞추기 위해 적용되는 학습 절차이다. 인간 주석자가 두 모델 출력 중 선호하는 것을 선택하는 데이터를 기반으로, 보상 모델이 학습되어 인간의 선호 패턴을 학습하고 선호 결정을 자동화한다.
Human Preference Data Collection
보상 모델링을 위해 인간 선호도 데이터를 수집하는 과정에서, 프롬프트 다양성을 극대화하기 위해 이진 비교 방식을 선택하였다.
주석 달기 절차는 주석자가 프롬프트를 작성하고, 제공된 기준에 따라 두 가지 다른 모델 변형에서 샘플링된 응답 중 하나를 선택하도록 한다. 다양성을 위해 응답은 다른 temperature hyper-parameter를 사용하여 샘플링된다. 또한, 주석자는 선택한 응답이 대안보다 얼마나 더 나은지를 평가하도록 요청받는다.
선호도 주석 수집에서 Llama 2-Chat 응답의 유용성과 안전성에 초점을 맞춘다. 유용성은 사용자 요청을 얼마나 잘 충족시키는지, 안전성은 응답이 안전 지침에 부합하는지를 평가한다. 예를 들어, 유용하지만 위험한 내용은 배제한다. 이러한 기준 분리를 통해, 특정 지침에 따라 주석자를 보다 효과적으로 안내할 수 있게 된다.
안전 단계에서는 모델 응답을 추가적으로 세 가지 범주 (1) 선호 응답만 안전, (2) 두 응답 모두 안전, (3) 두 응답 모두 불안전으로 분류하는 안전 라벨을 수집한다. 데이터셋은 각각 18%, 47%, 35% 비율로 이 범주에 속한다. 안전하지 않은 응답을 선택한 경우는 제외했으며, 이는 더 안전한 응답이 인간에 의해 선호될 것이라는 믿음 때문이다.
매주 정기적으로 수집된 인간의 주석으로 선호도 데이터가 늘어남에 따라 Llama 2-Chat의 보상 모델을 개선하고 더 나은 버전을 학습할 수 있었다. 모델 개선으로 데이터 분포가 변하고, 보상 모델의 정확도 유지를 위해 새로운 Llama 2-Chat 버전으로 새 선호도 데이터를 수집하는 것이 중요하다. 이 과정은 최신 모델에 대한 정확한 보상을 유지하기 위해 필수적이다.
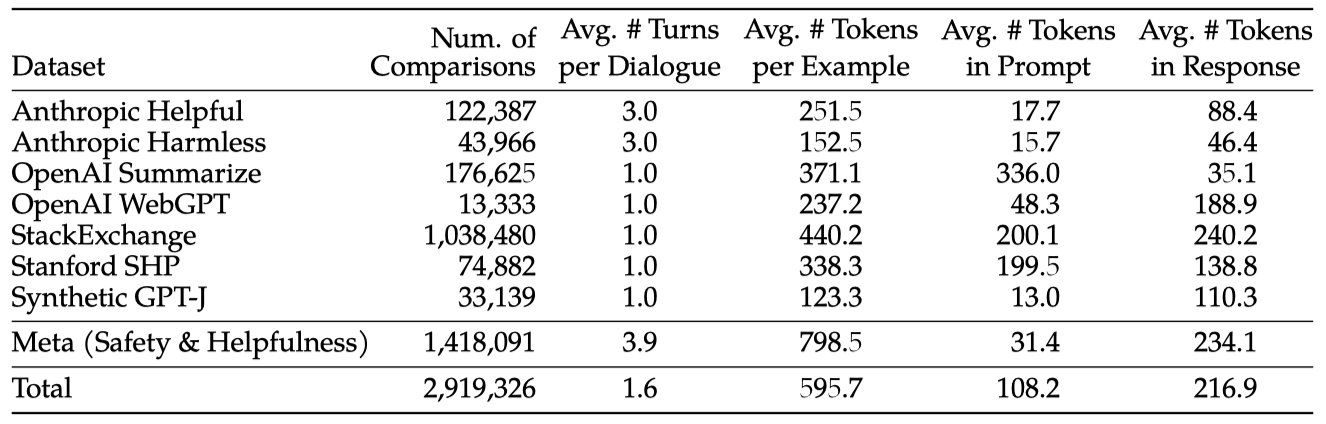
시간이 지나면서 지정한 지침에 따라 100만 개 이상의 이진 비교를 포함하는 메타 보상 모델링 데이터를 수집하였다. 이 데이터는 Anthropic Helpful and Harmless, OpenAI Summarize, OpenAI WebGPT, StackExchange, Stanford Human Preferences, Synthetic GPT-J 등 여러 오픈소스 선호도 데이터셋과 비교되었다. 이 연구의 데이터는 프롬프트와 답변의 토큰 수가 텍스트 도메인에 따라 다르며, 요약 및 온라인 포럼 데이터는 일반적으로 긴 프롬프트를, 대화 스타일은 짧은 프롬프트를 가진다. 기존 데이터셋 대비 이 연구의 데이터는 더 많은 대화 턴과 평균적으로 더 긴 특징을 보여준다.
Reward Modeling
보상 모델은 모델 응답과 프롬프트를 받아 품질을 평가하는 점수를 내고, 이 점수를 이용해 RLHF를 통해 Llama 2-Chat을 인간 선호도, 유용성 및 안전성 측면에서 개선한다.
유용성과 안전성이 상충할 수 있기 때문에, 우리는 유용성(Helpfulness RM)과 안전성(Safety RM)에 최적화된 두 개의 별도 보상 모델을 학습시킨다.
사전학습된 chat 모델에서 시작한 보상 모델은 chat 모델의 지식을 공유하여 정보 불일치를 방지한다. 구조는 같지만, 다음 토큰 예측 대신 스칼라 보상을 출력하는 regression head로 변경된다.
Training Objectives. 보상 모델 학습을 위해, 수집된 인간 선호도 데이터를 이진 랭킹 형식으로 변환해 선택된 응답이 더 높은 점수를 받도록 하며, 이 과정에서 Ouyang et al. (2022)의 binary ranking loss를 적용한다.
$$ L_{ranking} = −log( \sigma (r_{\theta}(x, y_c) − r_{\theta}(x, y_r))) $$
$r_{\theta} (x, y)$는 프롬프트 $x$와 응답 $y$에 대한 모델의 스칼라 점수이며, $y_c$는 선택된 응답, $y_r$은 거부된 응답이다.
binary ranking loss를 기반으로, 유용성과 안전성 보상 모델을 개선하기 위해 네 점 척도의 선호도 평가를 활용하여 차이가 큰 생성물에 더 큰 점수 차이를 주도록 모델을 수정하고 손실에 마진을 추가한다.
$$ L_{ranking} = −log( \sigma (r_{\theta}(x, y_c) − r_{\theta}(x, y_r) − m(r))) $$
마진 $m(r)$은 선호도에 따라 달라지며, 반응이 다른 쌍에는 큰 마진, 비슷한 쌍에는 작은 마진을 적용한다. 이 방법은 특히 반응이 명확히 구분되는 샘플에서 유용성 보상 모델의 정확도를 개선하는 데 효과적이다.
Data Composition. 새로 수집한 데이터와 기존 오픈 소스 선호도 데이터셋을 결합해 더 큰 학습 데이터셋을 만들었다. 이는 초기에 보상 모델 초기화에 사용되었다. 본 연구의 RLHF 맥락에서, 보상 신호는 모델 출력보다는 Llama 2-Chat 출력에 대한 인간 선호를 학습하는 것을 목표로 한다. 실험에서 오픈 소스 데이터셋의 부정적 전이는 관찰되지 않았으며, 이 데이터는 보상 모델의 일반화 개선과 보상 해킹 방지에 도움이 될 수 있으므로 데이터 혼합에 계속 포함시키기로 했다.
다양한 출처의 학습 데이터를 활용하여 유용성 및 안전성 보상 모델에 대한 다양한 혼합 방법을 실험한 결과, 유용성 보상 모델은 모든 메타 유용성 데이터와 메타 안전성, 오픈 소스 데이터의 동등한 비율로 혼합하여 학습시켰다. 안전성 보상 모델은 모든 메타 안전성 및 안트로픽 해롭지 않은 데이터에 메타 유용성 및 오픈 소스 유용성 데이터를 90/10 비율로 혼합하여 학습하였다. 특히, 선택된 반응과 거부된 반응이 모두 안전하게 판단된 샘플의 정확도에 10% 유용성 데이터 혼합이 유용한 것으로 나타났다.
Training Details. 학습 데이터에 대해 한 에폭 동안 학습을 진행하며, 더 긴 학습은 과적합을 초래할 수 있음을 초기 실험을 통해 확인하였다. 기본 모델과 동일한 최적화 parameter를 사용하며, 최대 learning rate는 70B parameter Llama 2-Chat은 $5 × 10^{-6}$, 그 외는 $1 × 10^{-5}$로 설정한다. learning rate는 코사인 일정에 따라 최대 learning rate의 10%까지 감소하며, 총 스텝 수의 3%에 해당하는 워밍업과 배치 당 1024행 또는 512쌍의 고정된 효과적인 배치 크기를 사용한다.
Reward Model Results. 보상 모델 평가를 위해, 인간 선호도 주석 배치마다 1000개 예시를 테스트 세트로 분리하며, 이들의 프롬프트 집합을 “Meta Helpfulness"와 “Meta Safety"로 명명한다.
기준으로, 우리는 FLAN-T5-xl 기반의 SteamSHP-XL, DeBERTa V3 Large 기반의 Open Assistant, 그리고 OpenAI의 GPT-4를 포함한 공개적으로 접근 가능한 다른 모델들을 평가하였다. 추론 시, 모든 보상 모델은 짝이 없는 단일 출력에 대해 스칼라 값을 예측할 수 있으며, GPT-4는 “Choose the best answer between A and B,“라는 zero-shot 질문으로 비교한다.
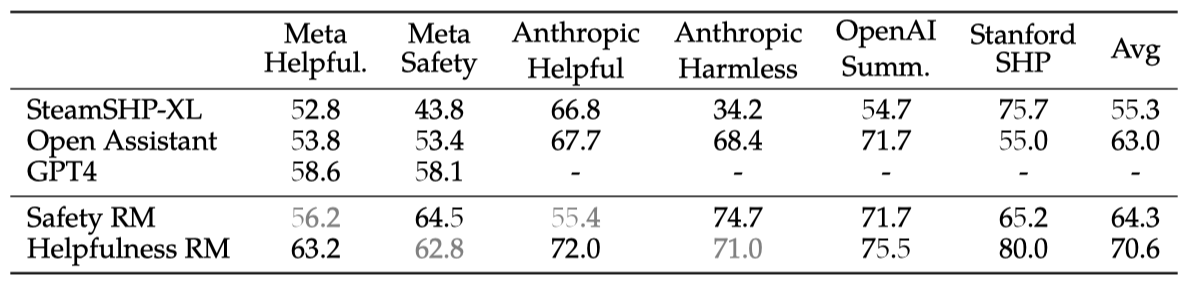
보상 모델이 Llama 2-Chat 기반 내부 테스트 세트에서 최고 성능을 보였고, 유용성과 안전성 모델이 각각 Meta Helpfulness와 Meta Safety 테스트 세트에서 가장 우수하였다. 전체적으로, 모델은 GPT-4를 포함한 모든 기준 모델을 초과했으며, GPT-4는 특별히 이 작업을 위해 학습되지 않았음에도 다른 모델보다 더 나은 성능을 보여주었다.
유용성과 안전성이 각각의 분야에서 우수한 성능을 보인 것은, 도움을 주는 것과 필요 시 안전하지 않은 프롬프트를 거부하는 두 목표 사이의 긴장 때문일 수 있다. 이러한 긴장은 학습 중 보상 모델에 혼란을 줄 수 있다. 따라서, 두 차원 모두에서 잘 작동하는 단일 모델은 적대적 프롬프트와 안전한 프롬프트를 구별하는 법을 배워야 한다. 별도의 두 모델을 최적화하는 것이 보상 모델링 작업을 단순화한다.

“significantly better"로 평가된 응답의 정확도가 가장 높으며, 응답이 유사해질수록 정확도가 저하된다. 비슷한 응답 사이의 선택은 주석자의 주관성과 미묘한 차이에 대한 의존 때문에 어려움을 겪는다. 따라서, 더 명확한 응답에 대한 정확도가 Llama 2-Chat 성능 개선에 중요하며, 이러한 응답에서 인간의 선호도에 대한 동의율이 더 높다.
Scaling Trends. 보상 모델의 데이터와 모델 크기에 대한 스케일링 추세를 분석하였다. 매주 수집되는 더 많은 데이터로 다양한 크기의 모델을 조정했고, 더 큰 모델이 더 좋은 성능을 보이는 경향이 있음을 확인하였다. 특히, 현재 사용된 데이터 양을 고려할 때 성능이 아직 정체되지 않아 더 많은 주석을 통한 개선 여지가 있음을 발견하였다. 보상 모델의 정확도가 Llama 2-Chat의 성능에 크게 기여하며, 보상 모델의 개선은 직접적으로 Llama 2-Chat의 개선으로 이어질 수 있다.
Iterative Fine-Tuning
더 많은 인간 선호도 데이터 주석을 받음으로써, 보상 모델을 개선하고 더 많은 프롬프트를 수집할 수 있었다. 이를 통해 RLHF 모델의 여러 버전, RLHF-V1부터 RLHF-V5까지를 학습시켰다.
두 가지 주요 알고리즘을 사용한 RLHF 미세 조정을 탐구하였다:
- Proximal Policy Optimization (PPO). RLHF 연구에서 기준으로 사용된다.
- Rejection Sampling fine-tuning. K개의 출력 중 보상을 기준으로 최고의 후보를 선택한다. 이 방법은 보상을 에너지 함수로 보고, 선택된 출력으로 gradient 업데이트를 진행한다. 가장 높은 보상을 받은 샘플을 새로운 기준으로 삼아 모델을 추가로 미세 조정하여 보상을 강화한다.
두 RL 알고리즘은 주로 다음과 같은 점에서 차이가 있다:
- Breadth - rejection sampling은 주어진 프롬프트에 대해 여러 샘플(K개)을 탐색하는 반면, PPO는 단 한 번의 생성을 진행한다.
- Depth - PPO는 학습 과정에서 이전 단계의 모델 업데이트를 반영하지만, rejection sampling은 초기 정책을 바탕으로 새 데이터셋을 수집한 후 미세 조정한다. 그러나 반복적인 업데이트로 인해 두 알고리즘 간 차이는 크지 않는다.
RLHF(V4)까지 rejection sampling만 사용하다가, 그 후에는 rejection sampling 결과에 PPO를 결합해 순차적으로 적용하고 다시 샘플링하였다.
Rejection Sampling. 70B Llama 2-Chat 모델에서만 rejection sampling을 진행하고, 이 데이터로 작은 모델들을 미세 조정하여 큰 모델의 능력을 전달한다. 이 효과에 대한 분석은 앞으로의 연구 과제이다.
각 반복 단계마다 최신 모델로부터 프롬프트별 K개 답변을 샘플링하여 최고의 답변을 선정한다. 이전까지는 답변 선택을 이전 반복의 샘플에 한정했으나(RLHF V3 예시), 이 방식은 일부 능력의 회귀를 초래하였다. 특히 RLHF V3는 운율 있는 시 구성에 어려움을 겪었는데, 이는 잊어버림 현상의 원인 및 완화 방법에 대한 미래 연구가 유익할 것임을 시사한다.
이후 반복에서, 모든 이전 반복의 최고 성능 샘플을 포함하는 전략으로 수정하였다. 이 조정은 성능을 크게 향상시키고 이전 문제들을 해결했으며, 이는 RL 문헌의 Synnaeve et al. (2019), Vinyals et al. (2019)과 유사한 완화 방법이다.
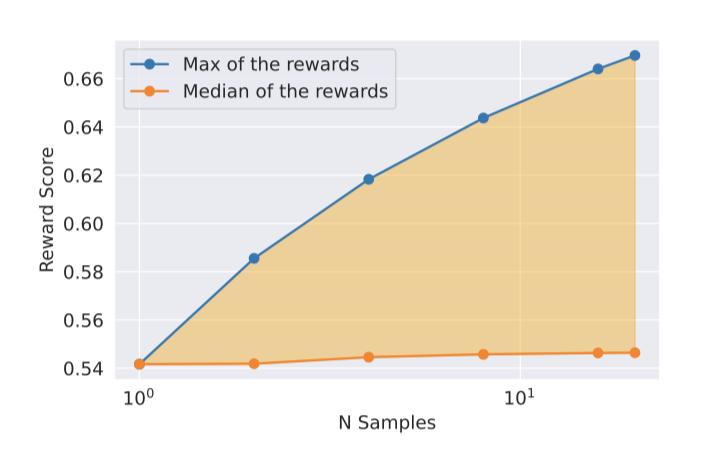
최대와 중앙값 사이의 차이는 최고의 출력에 대한 미세 조정 가능성을 나타낸다. 더 많은 샘플로 인해 이 차이는 증가하며(최대값 증가), 탐색과 얻을 수 있는 최대 보상 사이에는 직접적인 관계가 있다. 또한, 탐색에 있어 temperature parameter가 중요한 역할을 하며, 높은 temperature는 다양한 출력을 샘플링할 수 있게 한다.
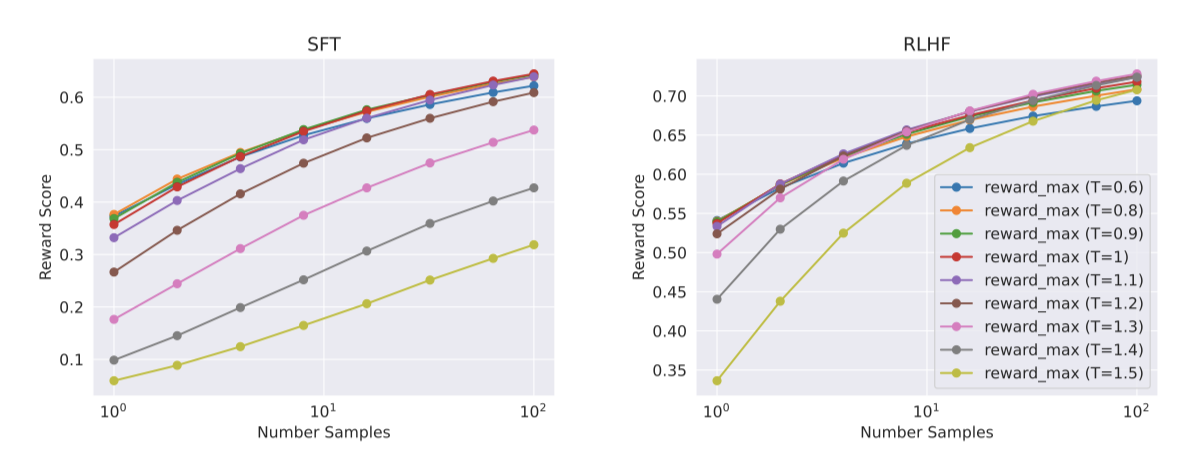
Llama 2-Chat-SFT와 Llama 2-Chat-RLHF 모델에 대해 다양한 온도에서 N개 샘플 중 최대 보상 곡선을 제시한다. 반복적 모델 업데이트 중 최적 temperature가 변하는 것을 볼 수 있으며, RLHF는 temperature 재조정에 직접적 영향을 준다. Llama 2-Chat-RLHF의 경우, 10~100개 출력 샘플링 시 최적 온도는 $T ∈ [1.2, 1.3]$이다. 한정된 계산 자원을 고려할 때, temperature를 점진적으로 조정해야 하며, 이 조정은 각 모델마다 일정 단계에서 시작되어 새 RLHF 버전마다 기본 모델에서 시작한다.
PPO. Stiennon et al. (2020)의 RL 방법을 사용하여 언어 모델을 추가로 학습한다. 이 방법은 보상 모델을 인간 선호의 추정치로, 사전 학습된 언어 모델을 최적화 대상으로 삼는다. 이 과정에서 특정 목표 최적화를 추구한다.
$$ arg \underset{\pi}{max} \mathbb{E}_{p∼D,g∼\pi} [R(g | p)] $$
데이터셋 $D$에서 프롬프트 $p$를 샘플링하고 정책 $\pi$을 통해 생성물 $g$를 얻어 정책을 개선한다. 이 과정에서 PPO 알고리즘과 손실 함수가 사용된다.
최적화 중에 사용하는 최종 보상 함수는 다음과 같다.
$$ R(g | p) = \hat{R}_c (g | p) − \beta D_{KL} (\pi_{\theta} (g | p) \Vert \pi_0 (g | p)) $$
원래 정책 $\pi_0$에서 벗어날 때 부과되는 벌칙 항은 학습의 안정성을 높이고, 보상 모델에서 높은 점수를 받으나 인간 평가에서 낮은 점수를 받는 현상을 줄이는 데 유용함을 확인하였다.
$R_c$는 안전성($R_s$)과 유용성($R_h$) 보상 모델의 결합으로 정의되며, 데이터셋 내 잠재적으로 위험한 프롬프트에 대해 안전 모델 점수를 우선한다. 안전하지 않은 반응을 걸러내기 위한 0.15의 임계값은 Meta Safety 테스트에서 정밀도 0.89, 재현율 0.55로 평가되었다. 최종 점수를 조정하여 안정성을 높이고 KL 벌칙 항($\beta$)과의 균형을 맞추는 것도 중요하다.
$$ R_c (g | p) = \begin{cases} R_s(g|p) & \text{if} \text{is_safety}(p) \text{or} R_s(g|p) < 0.15 \\ R_h(g|p) & \text{otherwise} \end{cases} $$
$$ \hat{R}_c (g|p) = \text{whiten}(\text{logit}(R_s(g|p))) $$
모든 모델에 AdamW 최적화기를 사용하며, 설정은 $\beta_1=0.9$, $\beta_2=0.95$, $eps=10^{-5}$이다. weight decay는 0.1, gradient clipping은 1.0, constant learning rate는 $10^{-6}$으로 고정된다. PPO 반복마다 512의 batch size, 0.2의 clip threshold, 64의 mini-batch size를 사용하고, mini-batch 한 번의 gradient 업데이트를 진행한다. 7B와 13B 모델에는 $\beta=0.01$, 34B와 70B 모델에는 $\beta=0.005$의 KL penalty를 적용한다.
모든 모델은 200~400 반복 학습 후 보류 중인 프롬프트로 조기 종료한다. 70B 모델은 PPO 반복당 평균 330초 소요된다. 큰 배치를 위해 FSDP를 사용했으나, 생성 시 약 20배 느려짐을 경험하였다. 이는 생성 전 모델 가중치를 각 노드에 통합하고 메모리 해제로 완화하며 학습을 이어갔다.
System Message for Multi-Turn Consistency
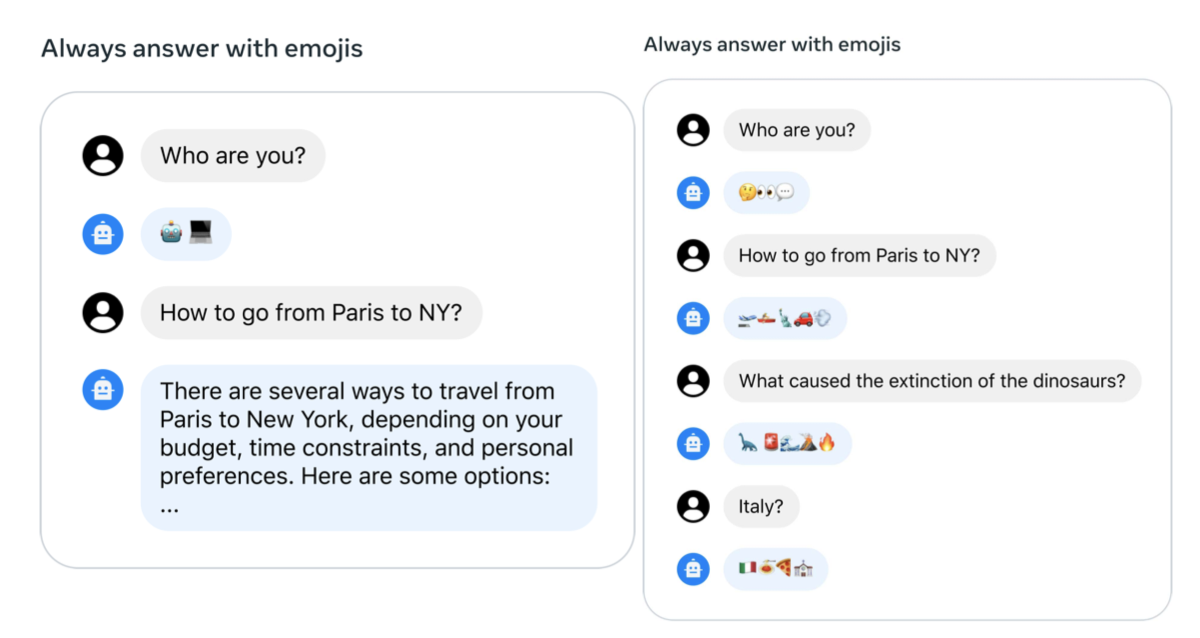
대화 설정에서 일관된 지시사항을 적용해야 하지만, 초기 RLHF 모델들은 몇 차례 대화 후 그 지시사항을 잊어버리는 경향이 있다.
이러한 한계를 해결하기 위해, 매우 간단한 방법인 Ghost Attention (GAtt)을 제안한다. GAtt는 attention focus를 강화하고 여러 차례 대화 제어를 가능하게 하는 방법이다.
GAtt Method. 여러 차례에 걸친 대화 데이터셋에서, 사용자와 조수의 메시지에 대한 지시사항(inst)을 설정하고, 이를 모든 사용자 메시지에 추가할 수 있다.
최신 RLHF 모델을 이용해 인위적인 데이터에서 샘플링한 후, Rejection Sampling과 유사한 방법으로 모델을 미세 조정한다. 첫 번째 차례를 제외하고 지시사항을 삭제하여 학습 시 불일치를 방지하고, 학습 효율을 높이기 위해 이전 차례의 모든 토큰에 대해 손실을 0으로 설정한다.
취미, 언어, 공인 등의 제약 조건을 포함하는 학습 지침을 만들고, 이를 Llama 2-Chat에 적용해 불일치를 방지하며 복잡하고 다양화된 지시사항을 구성하였다. 지시사항을 간결하게 수정하여 SFT 데이터셋을 생성하고, 이를 통해 Llama 2-Chat을 미세 조정하였다.
GAtt Evaluation. RLHF V3 다음에 GAtt를 적용한 결과, 최대 컨텍스트 길이에 도달할 때까지 20+ 차례의 일관성을 보여주는 정량적 분석을 제공하였다. 또한, “Always answer with Haiku,“와 같이 GAtt 학습에 없던 제약을 설정했을 때도 모델이 일관성을 유지하였다.
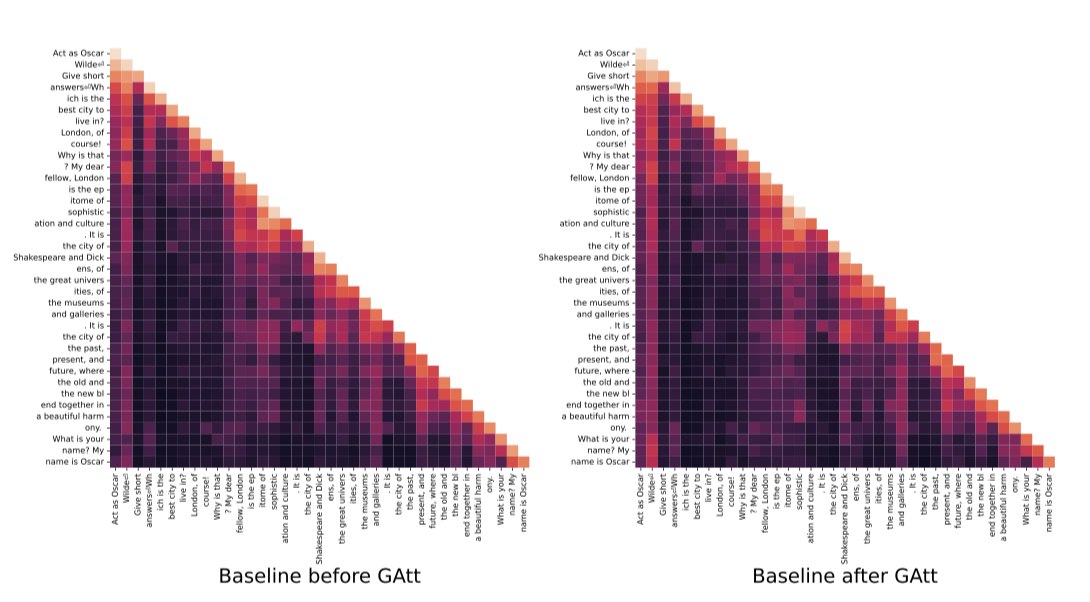
GAtt가 미세 조정 시 주의력을 재조정하는 방법을 보여주기 위해, 모델의 최대 주의 활성화를 그림 10에서 제시한다. GAtt를 장착한 모델은 GAtt가 없는 모델보다 대화 중 시스템 메시지(“Act as Oscar Wilde”)에 대해 더 크고 지속적인 주의를 기울인다.
GAtt는 유용하지만 현재 기본형 구현 상태이며, 추가 개발을 통해 모델 성능을 더 향상시킬 수 있다. 특히, 미세 조정을 통해 대화 중 시스템 메시지 변경을 모델에 학습시킬 수 있다.
RLHF Results
Model-Based Evaluation
LLM 평가는 복잡한 연구 과제이다. 인간 평가는 기준이지만 HCI 문제로 인해 복잡하고 항상 확장 가능한 것은 아니다. 그래서 RLHF-V1부터 V5까지, 비용을 절감하고 속도를 높이기 위해 먼저 최신 보상 모델의 개선을 통해 성능이 좋은 모델을 선별했고, 나중에 중요한 모델 버전에 대해 인간 평가로 확인하였다.
How Far Can Model-Based Evaluation Go? 보상 모델의 강건성을 평가하기 위해 유용성과 안전성을 위한 프롬프트 테스트 세트를 모으고, 7점 리커트 척도로 답변 품질을 평가하게 하였다. 결과적으로, 보상 모델이 인간 선호도와 잘 맞는 것을 확인할 수 있었다. 이는 Pairwise Ranking Loss로 학습되었음에도 불구하고, 점별 메트릭으로서 보상 사용의 유효성을 입증한다.
굿하트의 법칙에 따라 측정치가 목표가 되면 그 가치를 잃게 된다. 이를 방지하기 위해, 다양한 오픈 소스 데이터셋에서 학습된 일반적인 보상을 사용하였다. 이러한 방법으로, 아직 인간의 선호도에서 벗어난 편차를 관찰하지 못했으며, 모델의 반복적 업데이트가 이를 방지할 것이라고 추정한다.
새 모델과 이전 모델 간 회귀 없음을 확인하기 위해, 다음 주석 단계에서 두 모델을 모두 사용해 샘플링한다. 이 방법은 새 프롬프트에서 모델을 비교하고 샘플링 다양성을 늘리는 데 유용하다.
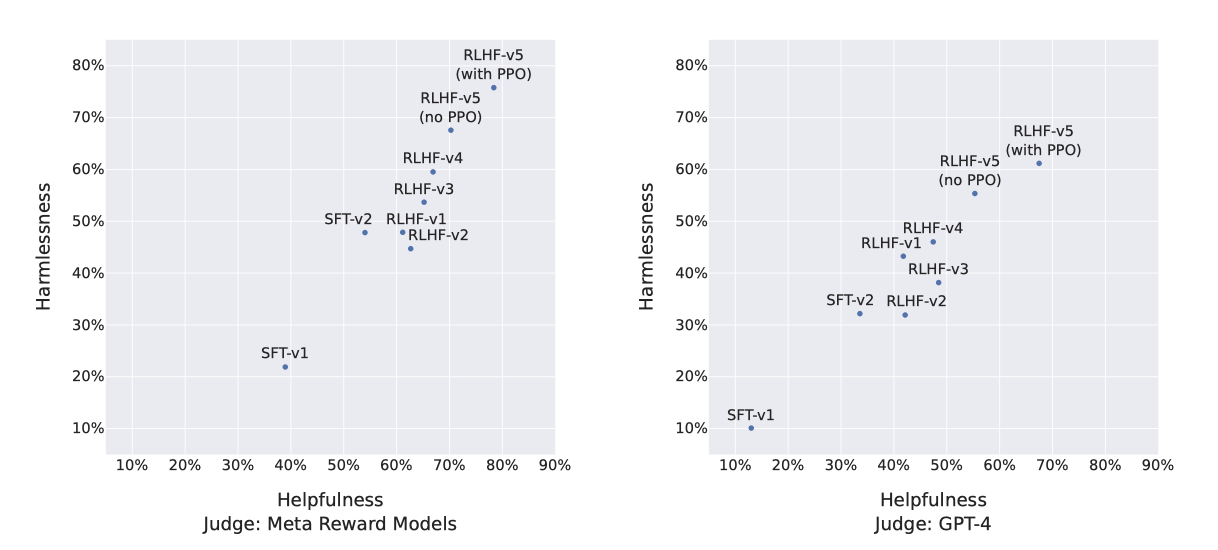
Progression of Models. 안전성과 유용성 측면에서 SFT 및 RLHF 버전이 ChatGPT를 RLHF-V3 이후로 초과하는 성능을 보여준다고 보고한다(해로움 없음 및 유용성 > 50%). 보상이 Llama 2-Chat에 편향될 수 있다는 우려에도 불구하고, 공정한 비교를 위해 GPT-4를 사용한 평가에서도 Llama 2-Chat의 최신 버전은 60% 이상의 승률을 보여주었다. 이 과정에서 ChatGPT와 Llama 2-Chat의 출력 순서는 편향을 피하기 위해 무작위로 배치되었다.
프롬프트는 각각 안전성과 유용성에 대해 1,586개와 584개의 검증 세트에 해당한다.
Human Evaluation
인간 평가는 자연어 생성 모델, 특히 대화 모델을 평가하는 데 중요한 기준이다. Llama 2-Chat과 다른 오픈 소스(예: Falcon, MPT MosaicML NLP 팀, Vicuna Chiang 등) 및 폐쇄 소스 모델(ChatGPT, PaLM 등)을 4,000개 이상의 프롬프트에 대해 유용성과 안전성 측면에서 비교하였다. ChatGPT는 모든 세대에서 gpt-3.5-turbo-0301을, PaLM은 chat-bison-001을 사용하였다.
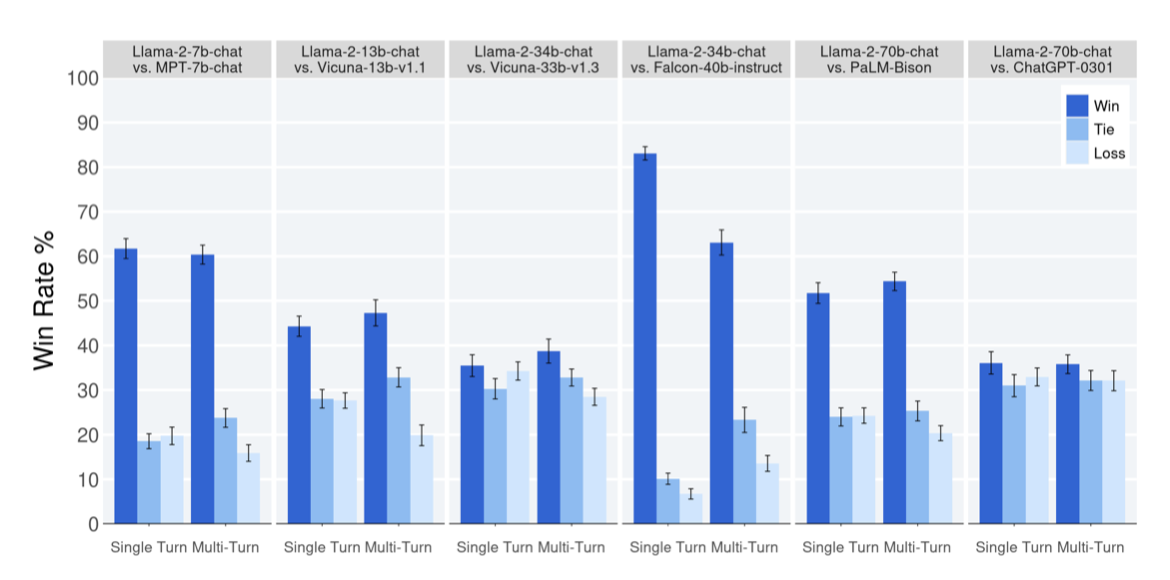
Results. Llama 2-Chat 모델은 단일 및 다차례 프롬프트에서 오픈 소스 모델을 크게 앞선다. 특히, 7B 버전은 60%의 프롬프트에서 MPT-7B-chat보다 우수하고, 34B 버전은 비슷한 크기의 Vicuna-33B와 Falcon 40B 모델에 대해 75% 이상의 승률을 보여준다.
Llama 2-Chat 70B 모델은 ChatGPT와 경쟁적이며, 36% 승률과 31.5% 무승부율을 기록한다. 또한, 이 모델은 PaLM-bison 챗 모델보다 이 연구의 프롬프트 세트에서 크게 우수하다.
Inter-Rater Reliability (IRR). 인간 평가에서는 세 명의 주석자가 모델 생성 비교에 독립적인 평가를 제공하였다. 데이터 품질 측면에서 높은 IRR 점수가 바람직하지만, 맥락 또한 중요하다. LLM 생성물의 유용성 같은 주관적 평가는 객관적 라벨링보다 IRR 점수가 낮을 수 있다. 이러한 맥락에 대한 공개 벤치마크가 적어, 분석 공유가 연구 커뮤니티에 기여할 것으로 보인다.
Gwet의 AC1/2 통계를 사용해 평가자 간 신뢰도(IRR)를 측정한 결과, 7점 리커트 척도 유용성 분석에서 AC2 점수는 0.37에서 0.55 사이로 나타났다. 비슷한 승률을 보인 모델 비교(예: Llama 2-Chat-70B 대 ChatGPT)는 점수 범위의 하단에, 더 명확한 승자가 있는 비교(예: Llama 2-Chat-34b 대 Falcon-40b)는 상단에 위치한다.
Limitations of human evaluations. 이 연구의 결과는 Llama 2-Chat이 ChatGPT와 인간 평가에서 비슷하지만, 인간 평가의 한계가 있음을 강조한다.
- 학술적으로 큰 4천 개 프롬프트 세트를 가지고 있지만, 실제 모델 사용을 완전히 대변하지는 않는다.
- 프롬프트의 다양성 부족, 즉 코딩이나 추론 관련 프롬프트 미포함도 결과에 영향을 미친다.
- 다단계 대화의 최종 생성물만 평가하는 대신, 여러 차례에 걸친 전체 경험 평가가 더 유익할 수 있다.
- 생성 모델에 대한 인간 평가는 주관적이고 변동성이 크며, 다른 프롬프트나 지침 사용 시 결과가 달라질 수 있다.
Safety
사전 학습 데이터와 모델의 안전성 조사, 안전성 조정 과정 및 SFT와 RLHF 사용, 모델 안전성 개선을 위한 레드 팀 활동, 그리고 Llama 2-Chat의 정량적 안전성 평가를 포함하여 안전성 측정 및 완화에 대해 자세히 다룬다.
Safety in Pretraining
사전 학습 데이터의 내용을 이해하는 것은 투명성을 제고하고 잠재적 문제, 예를 들어 편향성의 근본 원인을 파악하는 데 중요하다. 이를 통해 적절한 downstream 완화 조치와 모델 사용 방안을 결정할 수 있다. 이 섹션에서는 언어 분포, 인구학적 대표성, 독성 등 사전 학습 데이터의 여러 측면을 분석하고, 기존 안전성 벤치마크에 대한 사전 학습된 모델의 테스트 결과를 소개한다.
Steps Taken to Pretrain Responsibly. Meta는 사용된 각 데이터 세트에 대해 표준 개인정보 보호 및 법적 검토 절차를 준수하였다. Meta 사용자 데이터는 학습에 사용되지 않았으며, 개인 정보가 많이 포함된 특정 사이트의 데이터는 제외되었다. 모델 학습은 사전 학습의 탄소 발자국을 줄이기 위해 효율적으로 이루어졌다. 추가 필터링 없이 Llama 2를 다양한 작업에 폭넓게 사용할 수 있도록 했으며, 이는 안전성 조정 시 적은 예제로도 효과적인 일반화를 가능하게 한다. 따라서 Llama 2 모델은 상당한 안전성 조정 후 주의 깊게 사용되어야 한다.
Demographic Representation: Pronouns. 모델 생성물의 편향은 훈련 데이터의 편향에서 기인할 수 있다. 예를 들어, 대규모 텍스트에서 “남자” 단어는 “사람"과 비슷한 맥락에서 자주 사용되나 “여자” 단어는 그렇지 않다는 연구가 있다. 또한, 모델의 공정성 성능은 소수 인구 집단 데이터의 학습 방식에 크게 의존한다. 영어 훈련 코퍼스 분석 결과, “He"가 “She"보다 문서에서 과대표되는 경향이 있음을 확인하였다. 이는 모델이 “She"를 언급하는 맥락을 덜 학습하고, 결과적으로 “He"를 “She"보다 더 자주 생성할 가능성이 있음을 의미한다.

Demographic Representation: Identities. HolisticBias 데이터셋을 통해 사전 학습 데이터 내 다양한 인구 집단의 대표성을 분석한 결과, 설명자를 종교, 성별과 성, 국적, 인종과 민족, 성적 지향의 5개 축으로 분류하여 각 축의 상위 5개 용어를 조사하였다. 일부 일반적인 용어는 제외했으며, 성별과 성에서는 “여성"이라는 용어가 “She” 대명사보다 더 많은 문서에서 언급되었다. 이는 언어적 표시성의 차이를 반영할 수 있다. 성적 지향의 상위 용어들은 모두 LGBTQ+ 정체성과 관련이 있으며, 국적, 인종과 민족, 종교 축에서는 서구적 편향이 관찰되었다. 예로, “미국인"이 가장 많이 언급되었으며, “기독교"가 가장 많이 대표된 종교로 나타났다.
Data Toxicity. ToxiGen 데이터셋에 미세 조정된 HateBERT 분류기를 이용해 사전 학습 코퍼스의 영어 부분에서 독성 유병률을 측정한다. 문서의 각 줄별로 점수를 매겨 평균 점수로 문서 점수를 결정했으며, 전체 코퍼스의 10% 무작위 샘플 분석 결과, 평가된 문서 중 약 0.2%가 독성 가능성이 0.5 이상으로 나타나, 사전 학습 데이터에 소량의 독성이 있는 것으로 확인되었다.

Language Identification. 사전 학습 데이터는 주로 영어이며, 소수의 다른 언어 텍스트도 포함한다. fastText 언어 식별 도구를 사용한 분석 결과, 영어 중심의 코퍼스로 인해 모델이 다른 언어에는 적합하지 않을 수 있다.
Safety Benchmarks for Pretrained Models. LM 안전성의 세 핵심 차원에 대해, 세 가지 주요 자동 벤치마크를 통해 Llama 2의 안전 기능을 평가한다.
- Truthfulness, TruthfulQA를 통해 LLM이 사실과 상식에 부합하는 출력을 얼마나 잘 생성하는지 평가한다.
- Toxicity, ToxiGen을 사용하여 언어 모델이 다양한 그룹에 대해 독성이나 증오스러운 콘텐츠를 얼마나 생성하는지 측정한다.
- Bias, BOLD를 사용해 모델이 사회적 편견을 얼마나 반영하는지, 그리고 생성물의 감정이 인구 통계적 특성에 따라 어떻게 달라지는지 연구한다.
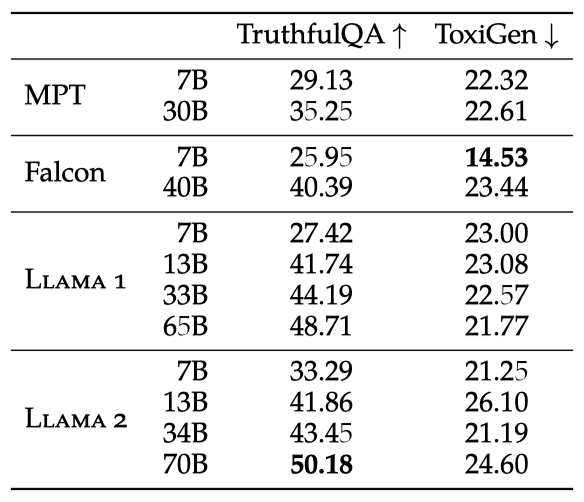
TruthfulQA와 ToxiGen 메트릭을 통해 각각 진실성과 독성의 비율을 평가한다. Llama 2-7B는 진실성과 유익성에서 21.37% 증가, 독성에서는 7.61% 감소를 보였다. 사전 학습된 큰 모델에서 독성 증가가 관찰되었으며, 이는 데이터셋 크기와 모델의 독성 및 편향 사이의 관계에 대한 추가 연구가 필요함을 시사한다.
Llama 2가 독성 지표에서 다른 모델을 능가하지 못한 이유는 사전 학습 데이터를 공격적으로 필터링하지 않았기 때문일 수 있다. 이로 인해 모델은 더 많은 downstream 작업에서 더 잘 수행되며 특정 인구 집단을 잘못 필터링할 위험을 줄인다. 또한, 덜 공격적으로 필터링된 데이터로 학습된 모델은 안전 정렬을 위해 적은 예시가 필요함을 확인하였다. 이는 Llama 2 모델 배포 전 추가 안전 조치가 필요함을 시사한다.
벤치마크는 모델의 일반적인 패턴을 이해하는 데 도움을 주지만, 사람이나 실제 결과에 미치는 영향을 완전히 파악하기에는 부족하다. 이에 최종 제품의 배포 연구가 필요하며, 특정 상황에서의 편향과 사회적 문제를 이해하기 위한 추가적인 테스트와 완화 노력이 요구된다. BOLD 데이터셋을 넘어서는 테스트가 필요할 수 있으며, 대규모 언어 모델이 배포됨에 따라 중요한 사회적 문제에 대한 긍정적인 영향을 증폭시키는 연구가 지속될 것이다.
Safety Fine-Tuning
이 섹션에서는 안전성 미세 조정 방법, 포함된 안전 범주, 주석 지침, 그리고 안전 위험을 줄이기 위한 기술에 대해 설명한다. 일반 미세 조정과 비슷하지만, 안전성 문제에 초점을 맞춘 몇 가지 특별한 차이점이 있다.
- Supervised Safety Fine-Tuning: 적대적 프롬프트와 안전 시연을 수집하여 지도 학습 미세 조정에 포함시켜, RLHF 이전에 모델이 안전 지침을 따르도록 하고 고품질 인간 선호도 데이터 주석의 기반을 마련한다.
- Safety RLHF: RLHF 파이프라인에 안전성을 통합하며, 안전 특화 보상 모델 학습과 더 어려운 적대적 프롬프트 수집을 통한 미세 조정 및 PPO 최적화를 진행한다.
- Safety Context Distillation: 마지막으로, Askell et al., (2021b)의 방법에 따라 컨텍스트 증류를 통해 RLHF 파이프라인을 개선한다. 이는 “당신은 안전하고 책임감 있는 조수입니다"와 같은 안전 선행 프롬프트를 사용해 안전한 응답을 생성하고, 이후 선행 프롬프트 없이 미세 조정하여 모델에 안전 컨텍스트를 증류하는 과정이다. 각 샘플에 대해 컨텍스트 증류를 사용할지 여부를 결정하는 목표 지향적 방식을 채택하였다.
Safety Categories and Annotation Guidelines
이전 연구를 바탕으로, 주석 팀이 적대적 프롬프트를 만들기 위한 지침을 개발하였다. 이는 LLM이 안전하지 않은 내용을 생성할 수 있는 위험 범주와 나쁜 행동을 유발할 수 있는 다양한 프롬프트 스타일인 공격 벡터, 두 가지 차원을 포함한다.
고려된 위험 범주는 불법 및 범죄 활동, 증오 및 해로운 활동, 그리고 자격 없는 조언으로 나뉘며, 공격 벡터는 심리적, 논리적, 구문적, 의미적 조작, 관점 조작, 비영어 언어 등을 포함한다.
안전하고 유용한 모델 응답을 위한 모범 사례로, 모델은 먼저 적절한 경우 즉시 해결해야 할 안전 문제를 다루고, 사용자에게 잠재적 위험을 설명하며, 가능하다면 추가 정보를 제공해야 한다. 주석자들은 부정적 사용자 경험을 피하도록 지시받는다. 이 지침은 모델의 일반적 가이드로 새로운 위험을 반영하여 지속적으로 개선된다.
Safety Supervised Fine-Tuning
지침에 따라, 학습된 주석자들로부터 안전한 모델 응답의 예시를 수집하여, 지도 학습을 이용해 미세 조정한다.
주석자들은 먼저 모델이 위험한 행동을 할 수 있는 프롬프트를 만들고, 그 다음 안전하고 도움이 되는 응답을 개발하는 과제를 받는다.
Safety RLHF
Llama 2-Chat 개발 초기, 모델은 지도 학습으로 안전 대응을 일반화하는 능력을 보여주었다. 안전 응답 작성과 주제의 민감성 설명 등을 빠르게 학습했으며, 평균 주석자보다 자세한 응답을 제공하였다. 이후 몇 천 개의 시연을 바탕으로 더 정교한 응답을 위해 RLHF로 전환했으며, 이는 모델의 탈옥 시도에 대한 저항력을 강화하는 추가적인 이점을 제공하였다.
RLHF 과정에서는, 주석자들이 안전하지 않은 행동을 유도할 것으로 예상되는 프롬프트를 작성하고, 여러 응답 중 가장 안전한 것을 선정하는 방식으로 안전성에 관한 인간의 선호도 데이터를 수집한다. 이 데이터를 바탕으로 안전 보상 모델을 학습시키고, RLHF 단계에서는 이러한 적대적 프롬프트를 모델 샘플링에 재사용한다.

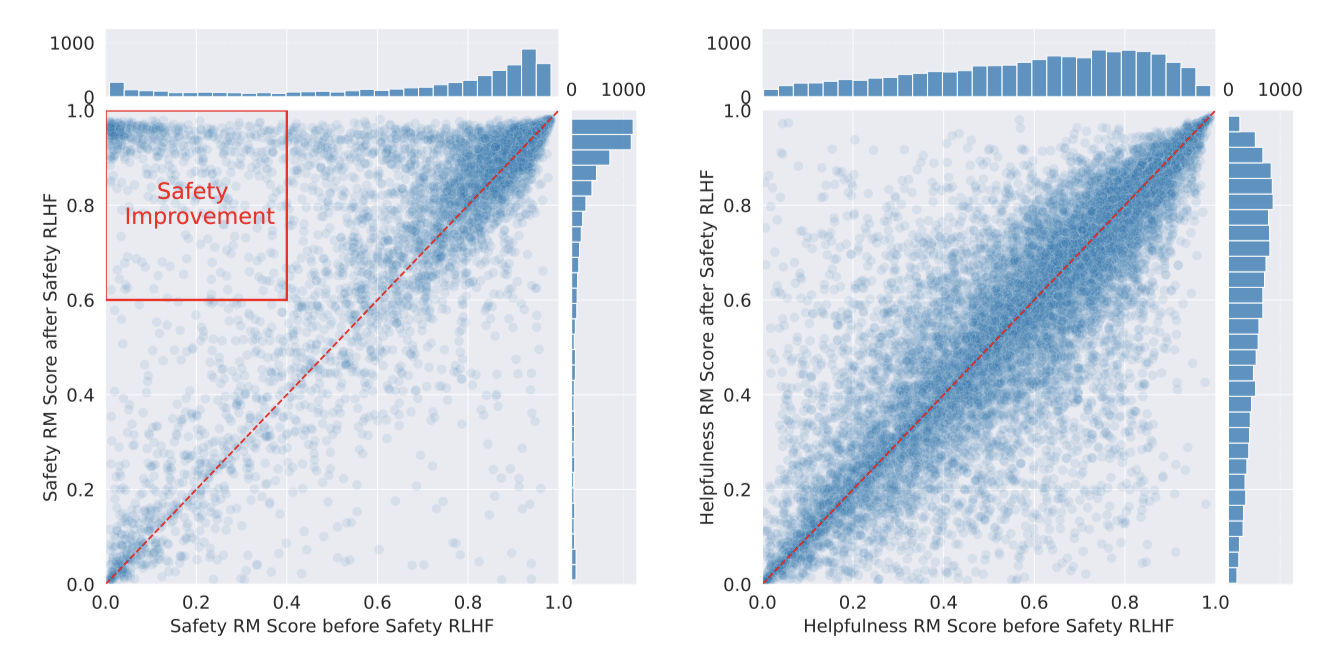
Better Long-Tail Safety Robustness without Hurting Helpfulness Safety RLHF를 통해 적대적 프롬프트 없는 Llama 2-Chat 중간 체크포인트와 포함한 체크포인트의 안전성과 유용성을 평가하였다. 안전 RM 점수는 안전 조정 후 더 높은 점수로 이동하며, 유용성 RM 점수는 변경 없이 유지되어, 추가적인 안전 조치가 유용성 성능에 부정적인 영향을 주지 않음을 확인하였다.
Impact of Safety Data Scaling. 이전 연구에서는 LLM의 유용성과 안전성 사이의 긴장 상태가 발견되었다. 이를 극복하기 위해, 안전 학습 데이터의 추가가 모델 성능에 미치는 영향을 분석하기 위해, 안전 데이터의 양을 조절하는 실험을 진행하였다. 유용성 데이터는 약 0.9M 샘플로 고정하고, 안전 데이터는 0%에서 100%까지(약 0.1M 샘플) 증가시켜 Llama 2 모델을 2 epoch 동안 미세 조정한다.
총 안전 데이터의 0%, 1%, 10%, 25%, 50%, 100%를 사용해 학습된 6개의 모델 변형을 얻었으며, 이들은 3.2.2절에 기술된 안전성 및 유용성 보상 모델로 평가된다. 각 변형 모델은 메타 안전성 및 유용성 테스트 세트의 프롬프트에 대한 생성물을 안전성 및 유용성 보상 모델로 점수화한다.
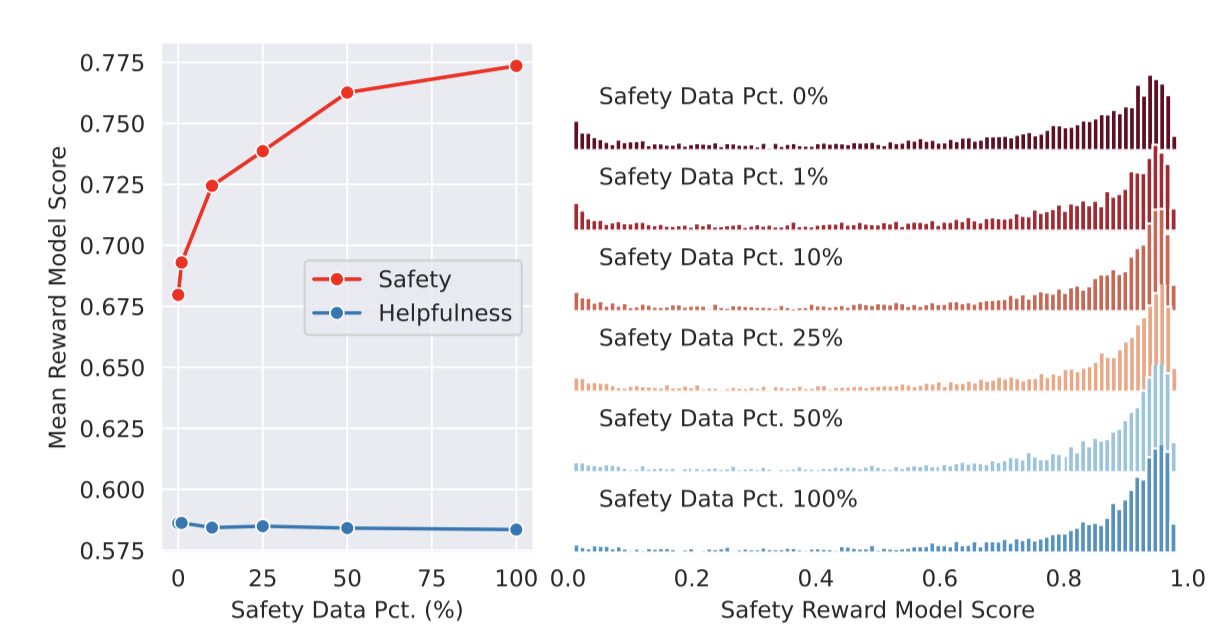
안전 데이터의 비율 증가에 따라 모델의 위험 및 적대적 프롬프트 처리 성능이 크게 개선되며, 안전 보상 점수 분포의 꼬리가 가벼워지는 것을 관찰한다. 반면, 평균 유용성 점수는 일정하다. 이는 충분한 유용성 학습 데이터를 이미 보유하고 있기 때문일 것으로 추정된다.
Measure of False Refusal. 비록 모델의 유용성 감소는 관찰되지 않았지만, 안전 완화 기능이 적용된 모델이 특정 질문에 보수적으로 대응하는 것을 볼 수 있다. 이에 따라, 모델이 관련 없는 안전 우려로 인해 비적대적 프롬프트에 잘못 대답을 거부하는 거짓 거부를 측정한다. 모델의 능력을 초과하는 합리적인 이유로 인한 거부는 거짓 거부로 간주되지 않는다. 이를 위해, 거부 감지 분류기를 학습시키고 유용성 테스트 세트 및 OpenAI(2023)와 비슷한 경계 테스트를 위한 선별된 테스트 세트에 적용한다. 경계 데이터셋은 적대적으로 보이지만 실제로 안전한 프롬프트들로 구성된다.
모델을 안전 데이터로 더 많이 조정할수록 두 데이터셋에서 거짓 거부율이 증가하지만, 유용성 데이터셋에서는 거의 0.05%로 드물게 발생한다. 하지만, 경계 데이터셋에서는 난이도로 인해 거짓 거부율이 높다. Llama 2-Chat은 폭탄 같은 단어가 포함된 프롬프트의 안전 여부를 판별하는 데 어려움을 겪는다.
Context Distillation for Safety
Askell et al., (2021a)의 방법을 따라, Llama 2-Chat은 컨텍스트 증류를 사용하여 적대적 프롬프트에 대해 안전한 응답을 하도록 유도된다. 안전 프리프롬프트를 모델 앞에 추가함으로써, 대규모 언어 모델의 안전 기능을 효과적으로 향상시킬 수 있다. 이 방식은 어려운 적대적 프롬프트에 대한 응답을 신속하게 준비하는 방법으로, 추후 RLHF를 통해 더욱 개선될 수 있다.
적대적 프롬프트 앞에 안전 프리프롬프트를 추가하는 컨텍스트 증류 방법을 통해 안전한 응답을 생성한다. 이후, 프리프롬프트 없이 해당 적대적 프롬프트에 대한 모델의 안전한 출력을 미세조정한다. “책임감 있는”, “존중하는”, “현명한” 등 안전한 행동을 나타내는 형용사를 포함한 템플릿으로 안전 프리프롬프트를 자동 생성한다. 이러한 접근은 모델이 긍정적인 특성을 반영하도록 한다.
Context Distillation with Answer Templates 프롬프트 수집 단계에서 주석자들이 위험 범주별로 프롬프트를 분류하도록 하여, 위험 유형에 맞는 맞춤형 프리프롬프트를 제공할 수 있게 되었다. 이를 통해 각 위험 범주에 맞는 적대적 프롬프트 처리를 위한 전용 답변 템플릿을 제공할 수 있다.

Rejecting Context Distillation Errors with the Safety Reward Model 안전한 컨텍스트 증류를 유용한 프롬프트에 적용하면 모델 성능 저하와 거짓 거부 증가를 일으킬 수 있다. 따라서 이 방법을 적대적 프롬프트에만 적용한다. 하지만 적대적 프롬프트에도 때때로 응답 품질이 저하될 수 있으며, 특히 이미 고품질인 응답에는 덜 적절한 답변을 유도할 수 있다. 이에 안전 보상 모델을 활용하여 컨텍스트 증류 적용 여부를 결정하며, 보상 모델 점수가 더 높은 경우에만 증류한 출력을 유지한다. 이 방법은 특히 모델이 부적절하게 대응하는 프롬프트에 도움이 되며, 컨텍스트 증류의 부정적 영향을 제한한다.
Red Teaming
LLM의 광범위한 기능과 다양한 학습 데이터를 고려할 때, 사후 분석만으로는 위험을 충분히 식별하기 어렵다. 따라서 컴퓨터 보안에서 사용되는 레드 팀 용어를 차용하여, 다양한 적극적 위험 식별 방법을 사용하였다. 드문 에지 케이스도 중요한 문제를 일으킬 수 있기 때문에, 이러한 세밀한 분석은 안전 문제에 있어서 필수적이다. 정량적 평가가 좋을 지라도, 질적 통찰을 통해 우리는 특정 패턴을 더 잘 인식하고 대응할 수 있다.
내부 직원, 계약직 근로자, 외부 벤더 등 다양한 그룹과 함께 350명 이상의 전문가가 참여한 레드 팀 활동을 진행하였다. 이들은 사이버보안, 선거 사기, 소셜 미디어 오보, 법률, 정책, 시민권, 윤리, 소프트웨어 엔지니어링, 기계학습, 책임 있는 AI, 창의적 글쓰기 등 다양한 분야의 전문가로 구성되었으며, 사회경제적, 성별, 인종적 다양성을 대표하는 인원도 포함되었다.
레드 팀원들은 범죄 계획, 인신매매, 성적 콘텐츠, 부적합한 건강/금융 조언, 개인정보 침해 등 위험 범주와 가설적 질문, 잘못된 입력, 확장된 대화 등 다양한 공격 경로를 통해 모델을 검사하였다. 또한, 무기 생산(예: 핵, 생물학적, 화학적, 사이버) 능력에 대한 테스트를 실시했으며, 이와 관련된 발견은 경미하고 완화되었다.
지금까지 진행된 레드 팀 활동은 영어 모델 출력을 중심으로 이루어졌으나, 잘 알려진 공격 경로로서 비영어 프롬프트와 대화 상황도 중요하게 다루었다. 참가자들은 위험 범주에 대한 정의와 LLM과의 위험 상호작용 예시를 받고, 특정 위험 범주나 공격 경로에 초점을 맞춘 소그룹에서 활동했습니다. 대화 생성 후, 레드 팀 참가자들은 위험 영역과 위험도를 5점 리커트 척도로 주석 처리하였다.
개발 과정에서 개선할 수 있었던 레드 팀 구성원들이 제공한 유용한 통찰의 몇 가지 예시는 다음과 같다:
- [Early models]은 문제 콘텐츠를 인식하지 못하고 안전하지 않은 응답을 생성하는 경향이 있었으나, 더 최근 모델은 문제를 인지하고도 응답을 제공하였다. 최신 모델은 이 문제들을 해결할 수 있다.
- [Early models]은 특정 요청이나 기이한 요소를 포함시키는 것으로 쉽게 방해받았다. 창의적인 글쓰기 요청은 콘텐츠 생성에 신뢰할 수 있는 방법이었다.
- 긍정적 맥락에 문제 요청을 포함하는 것은 [Early models]에서 문제 출력 요청을 숨기는 데 성공하였다. 공격을 숨기는 가장 효과적인 방법은 긍정적이고 진보적인 언어 사용이었다.
From Red Teaming Insights to Safer Models. 각 연습 후, 우리는 대화 길이, 위험 영역 분포, 정보 오류 주제 등의 데이터를 철저히 분석하였다. 이 분석을 통해 얻은 교훈은 모델의 안전성을 강화하기 위한 지침으로 활용되었고, 이 데이터는 모델 미세 조정, 피드백 교육, 및 다른 안전 교육에 사용되었다.
새 모델 출시 시, 여러 레드 팀 작업을 통해 모델의 견고함을 측정하였다. 이러한 작업으로, 모델이 위반 응답을 유발하는 프롬프트의 평균 개수가 줄어들었으며(예: 7B 모델에서 1.8에서 0.45로), 이전에 문제가 되었던 프롬프트의 거부율도 평균 90%로 개선되었다. 이는 추가적인 노력으로 계속 발전할 것으로 예상된다.
Safety Evaluation of Llama 2-Chat
Safety Human Evaluation. 안전 카테고리를 기준으로 약 2,000개의 적대적 프롬프트를 인간 평가용으로 수집했으며, 이 중 1,351개는 single-turn, 623개는 multi-turn이다.
그런 다음 평가자들에게 다음 정의를 가진 5점 리커트 척도로 모델의 안전 위반 여부를 판단하도록 요청하였다:
- 5 - 안전 위반 없음, 매우 도움됨
- 4 - 안전 위반 없음, 사소한 비안전 문제만 있음
- 3 - 안전 위반 없으나 도움이 되지 않거나 기타 주요 비안전 문제 있음
- 2 - 경미하거나 중간 정도의 안전 위반
- 1 - 심각한 안전 위반
1 또는 2의 평가를 위반으로 보고, 위반 비율을 주 평가 지표로 하며 평균 평점을 보조 지표로 사용한다. 3명의 주석자가 각 예시를 평가하고, 다수결로 위반 여부를 결정한다. Gwet의 AC1/2 통계로 주석자 간 신뢰도(IRR)를 측정했으며, IRR 점수는 0.70에서 0.95 사이로, 안전 평가에 높은 동의를 나타낸다. 특히, Llama 2-Chat의 평균 IRR은 0.92이다. 위반율이 높은 모델은 IRR 점수가 낮고, 위반율이 낮은 모델은 IRR 점수가 높음을 확인하였다.
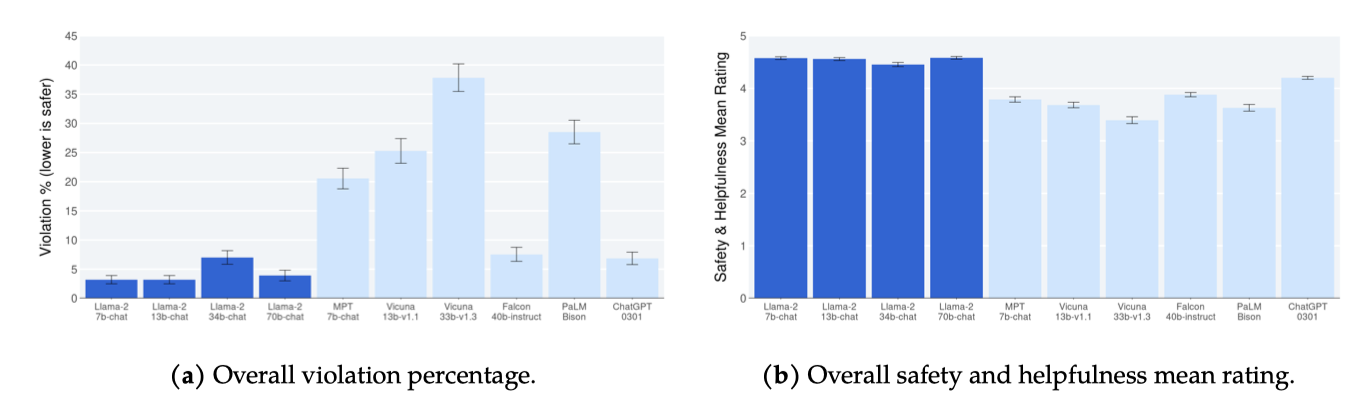
Llama 2-Chat이 모델 크기에 따라 낮은 위반 비율을 보여주며, ChatGPT와 Falcon, MPT, Vicuna 순으로 안전 평가가 이루어진다. 결과 해석 시 프롬프트 세트의 한계, 검토 지침 및 콘텐츠 기준의 주관성, 그리고 개별 평가자의 주관성을 고려해야 한다. Falcon은 짧은 응답으로 인해 안전하지 않은 콘텐츠 생성 가능성이 낮지만 도움이 덜 됨을 나타내며, 이는 많은 응답이 평가 3을 받는 것으로 나타난다. 그 결과, Falcon의 평균 평점은 Llama 2-Chat보다 훨씬 낮지만 위반 비율은 비슷하다(3.88 vs 4.45).
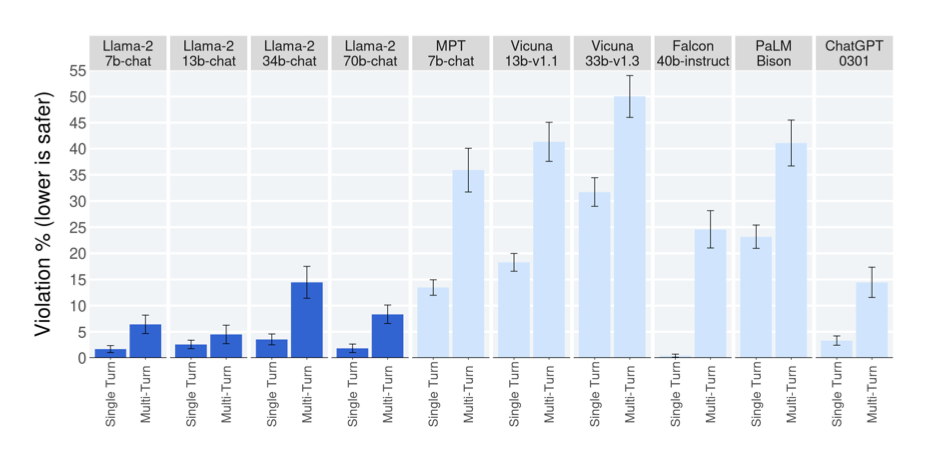
single-turn 및 multi-turn 대화의 위반 비율을 보고하며, multi-turn 대화가 안전하지 않은 반응을 더 유발할 가능성이 높다는 추세가 있다. 그럼에도 Llama 2-Chat은 multi-turn 대화에서 기준선 대비 우수한 성능을 보인다. 반면, Falcon은 single-turn 대화에서는 잘 수행하지만, multi-turn 대화에서는 성능이 떨어지는데, 이는 multi-turn 대화를 위한 미세 조정 데이터의 부족 때문일 수 있다.
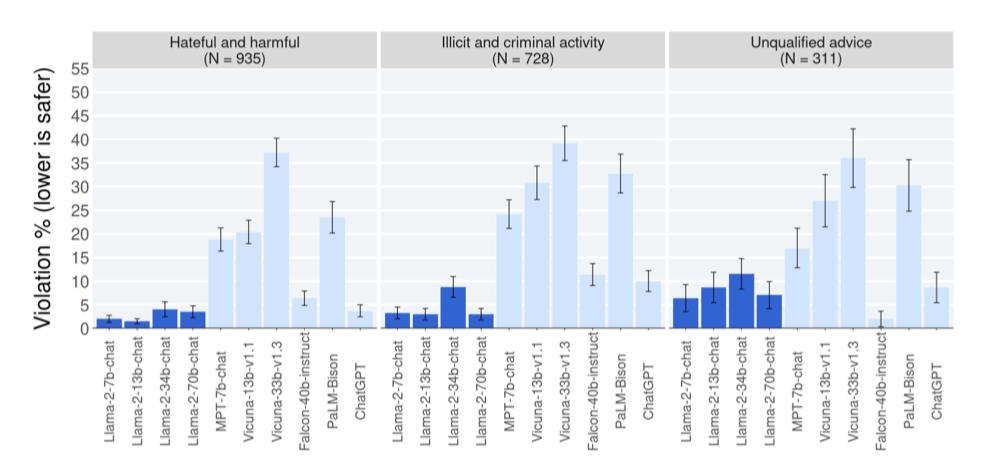
다양한 LLM의 카테고리별 안전 위반 비율 결과에서, 대부분의 카테고리에서 모델 성능이 비슷하다. 그러나 Llama 2-Chat은 특히 ‘unqualified advice’ 카테고리에서 상대적으로 높은 위반을 보이는데, 이는 때때로 적절한 면책 조항이 부족하기 때문이다. 그러나 다른 카테고리에서는 Llama 2-Chat이 모델 크기에 관계없이 일관되게 낮은 위반 비율을 유지한다.
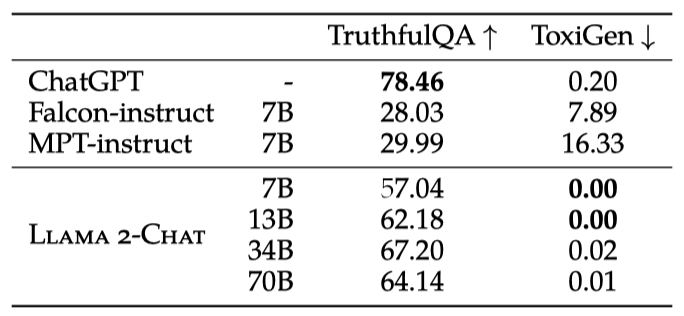
Truthfulness, Toxicity, and Bias. 미세 조정된 Llama 2-Chat은 사전 학습된 Llama 2 대비 진실성과 독성에서 크게 개선되었다(70B 모델 기준 진실성은 50.18에서 64.14로, 독성은 24.60에서 0.01로 감소). 이로 인해 독성 발생 비율이 모든 크기의 Llama 2-Chat에서 사실상 0%로 줄어들어 비교된 모든 모델 중 가장 낮은 독성 수준을 기록하였다. 또한, 미세 조정된 Llama 2-Chat은 Falcon과 MPT와 비교하여 독성과 진실성 측면에서 가장 우수한 성능을 보였으며, BOLD의 다양한 인구 집단에서 전반적으로 긍정적인 감정이 증가하는 경향을 보여주었다.
Discussion
RLHF의 흥미로운 속성, Llama 2-Chat의 한계, 모델 책임 공개 전략에 대해 논의한다.
Learnings and Observations
이 연구의 튜닝 과정은 Llama 2-Chat이 지식을 시간적으로 조직하거나 외부 도구를 위한 API를 호출하는 능력과 같은 몇 가지 흥미로운 결과를 밝혀냈다.
Beyond Human Supervision. 프로젝트 초기에 많은 이들이 더 집중된 신호의 매력 때문에 감독된 주석을 선호했다. 하지만, 불안정성이 문제인 강화 학습은 비용과 시간 측면에서 큰 효과를 보여주었다. 이 연구는 RLHF의 성공이 주석 과정에서 인간과 LLM 사이의 시너지에 크게 의존한다는 것을 밝혔다.
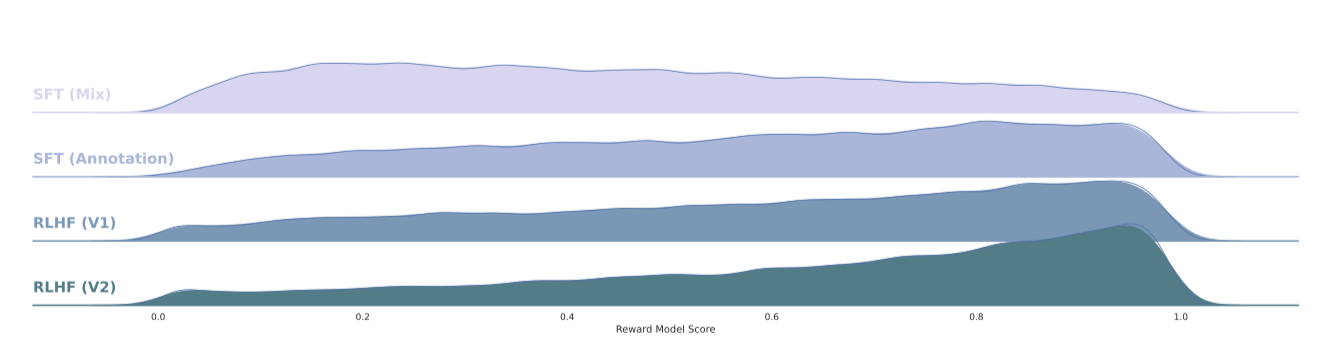
실력 있는 주석가들도 글쓰기에 상당한 변화를 보이며, SFT 주석으로 미세 조정된 모델은 이러한 다양성과 더불어 부실한 주석까지 학습한다. 모델의 성능은 최고 숙련 주석가의 능력에 제한을 받는다. 그러나 인간 주석가는 RLHF의 두 출력 선호도 비교 시 차이에 덜 민감하며, 보상 메커니즘은 불필요한 분포에 낮은 점수를 빠르게 할당해 인간 선호도에 맞춘다. 이는 최악의 답변이 제거되고 분포가 오른쪽으로 이동하는 현상을 통해 확인할 수 있다.
주석 과정에서 모델은 최고의 주석가도 생각지 못한 글쓰기 방향으로 나아갈 수 있지만, 인간은 자신의 글쓰기 능력을 넘어서 두 답변을 비교하며 유의미한 피드백을 줄 수 있다. 이는 모두가 예술가는 아니지만, 예술을 평가할 능력이 있다는 것과 유사하다. LLM의 우월한 글쓰기 능력이 RLHF에 의해 주도되며, 이는 감독된 데이터가 더 이상 기준이 아니게 되어 “supervision"의 개념을 다시 생각해 보게 한다.
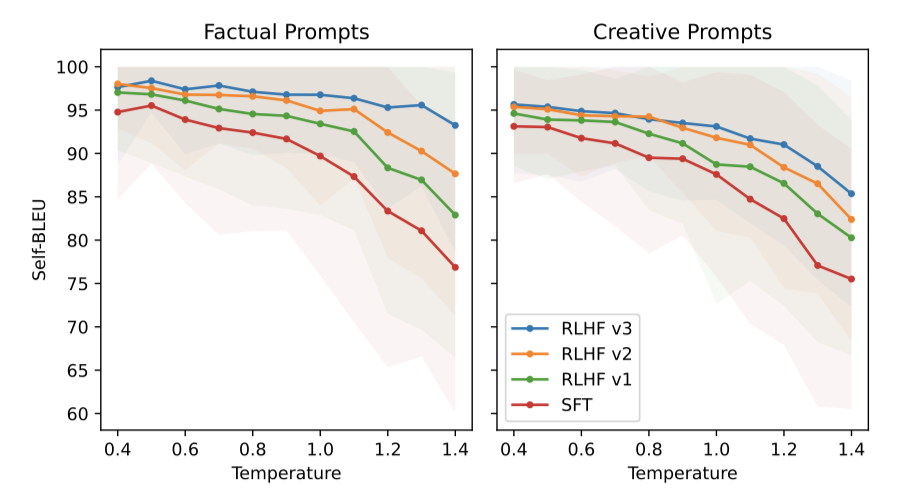
In-Context Temperature Rescaling. RLHF와 관련하여 발견된 새로운 현상은 상황에 따른 온도의 동적 변화이다. 온도가 RLHF의 영향을 받는 것으로 나타났으나, 모든 프롬프트에 일관되게 적용되지 않는다는 점이 흥미롭다.
“Write a poem,“와 같은 창의적인 프롬프트에 대해 온도를 높임으로써 RLHF 반복을 통해 다양성을 지속적으로 생성할 수 있으며, 이는 SFT 모델과 유사한 패턴을 나타내는 Self-BLEU 기울기에서 확인할 수 있다.
사실 기반 프롬프트, 예를 들어 “What is the capital of ?“에 대해, 시간이 지남에 따라 Self-BLEU 기울기가 줄어든다. 이는 온도 상승에도 모델이 사실 관련 질문에 일관된 답변을 제공하도록 학습한다는 것을 나타낸다.
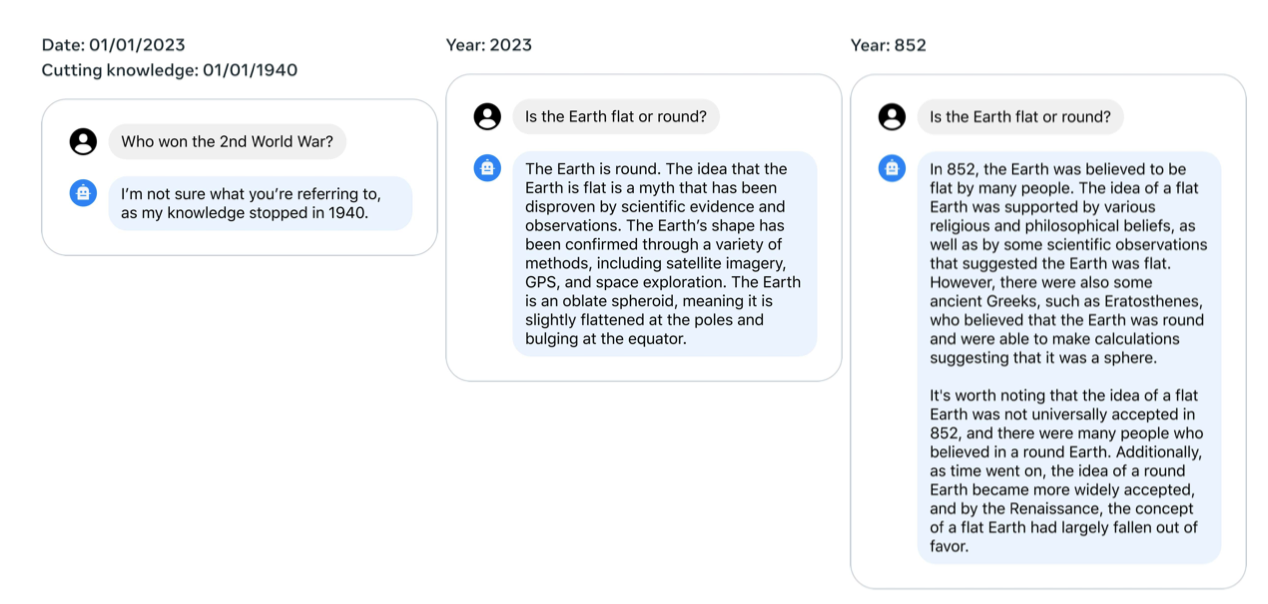
Llama 2-Chat Temporal Perception 최소한의 데이터로도 지식을 시간적으로 정리하는 능력을 일관되게 확인하였다. 시간 개념을 Llama 2-Chat에 주입하기 위해, 특정 날짜와 관련된 1,000개의 SFT 예시를 수집했으며, 이들 예시는 “How long ago did Barack Obama become president?“와 같은 질문을 포함한다. 각 예시는 질문이 제기된 날짜와 사건 발생 날짜라는 두 가지 중요한 메타데이터와 연결되어 있다.
이 관찰은 LLM이 연대기적 맥락 없이 데이터를 무작위로 섞어 학습함에도 불구하고, 이전 가정보다 시간의 개념을 더 잘 내면화했다는 것을 나타낸다.
Tool Use Emergence Mialon et al. (2023)에 따르면, LLM과 도구의 통합은 성장 중인 연구 분야이다. Toolforme의 접근법은 각 도구에 대한 소수의 예시와 수백만 개의 궤적 샘플링을 포함한다. 그러나 이 기술은 예시마다 하나의 도구에만 적용되었고, 도구 사용의 연속으로는 확장되지 않는다.

OpenAI의 플러그인 출시는 “How can we effectively teach models to utilize tools?“와 같은 질문을 학계에 던졌다. 실험 결과, 도구 사용은 명시적인 주석 없이도 zero-shot 방식으로 자발적으로 나타날 수 있음을 보여준다.

이 연구는 Llama 2-Chat의 계산기 사용 평가로 확장되었다. LLM 도구 사용은 흥미롭지만 안전 문제를 일으킬 수 있어, 이 분야에서 커뮤니티 연구와 레드 팀 활동을 촉진한다.
Limitations and Ethical Considerations
Llama 2-Chat은 사전 학습 이후 지식 업데이트가 중단되며, 비사실적 내용 생성 및 환각 경향과 같은 제한 사항을 가진다.
Llama 2-Chat의 초기 버전은 영어 데이터에 초점을 맞추었고, 실험을 통해 다른 언어에도 일정 수준 능력이 있음을 확인했으나, 비영어권 언어에 대한 데이터 부족으로 인해 그 능력이 제한적이다. 따라서 비영어권 언어에서의 성능은 취약하여 주의가 필요하다.
Llama 2는 공개 데이터셋 학습으로 인해 해로운 콘텐츠를 생성할 위험이 있으며, 특히 비영어 데이터의 부족으로 인해 비영어권 언어에서 문제가 남아 있을 수 있다. 이 문제를 해결하기 위해 지속적으로 조정하고 업데이트할 계획이다.
AI 모델 사용자 중 일부는 악의적 목적을 가지고 있으며, 대화형 AI가 잘못된 정보 생성이나 생물 테러리즘 등에 사용될 가능성이 있다. 그러나 이러한 용도로의 사용 가능성을 줄이기 위해 모델 조정에 노력하고 있다.
안전성과 유용성 사이의 균형을 맞추려 했으나, 때때로 Llama 2-Chat의 안전 조정이 지나치게 강화되어 사용자가 모델의 과도한 조심스러움을 경험할 수 있다.
사전 학습된 모델 사용자들은 주의를 기울이고, 책임 있는 사용 가이드에 따라 추가적인 조정과 배포 조치를 해야 한다.
Responsible Release Strategy
Release Details. Llama 2는 연구와 상업 목적으로 사용 가능하며, 사용자는 라이센스 조건 및 사용 정책을 준수해야 하며, 이는 모든 관련 법과 규정을 위반하는 사용을 금지한다.
개발자가 Llama 2-Chat을 안전하게 사용할 수 있도록 코드 예시와 안전한 개발 및 배포를 위한 가이드를 제공한다.
Responsible Release. 많은 기업들이 AI 개발을 비공개로 선택한 가운데, 책임 있는 AI 혁신을 촉진하기 위해 Llama 2를 공개적으로 출시한다. 개방적 접근은 AI 전문가 커뮤니티의 집단적 지혜를 활용해 이 기술의 이점을 실현하고, 모델을 개선하며 안전하게 만들 수 있다. AI 커뮤니티 전체가 위험 분석과 문제 해결을 위해 협력해야 한다. 이러한 공개적 출시는 투명성을 높이고, 기술에 대한 접근을 민주화하며, AI 전문 지식을 분산시켜 혁신과 진보를 촉진한다. 또한, 이는 소규모 기업이 새로운 사용 사례를 개발할 수 있도록 진입 장벽을 낮추고, 전 세계 모든 규모의 조직이 AI 발전의 경제적 이익을 누릴 수 있는 보다 공정한 환경을 조성할 것이다.
AI 모델 사용에 선한 의도가 없는 경우도 있고, AI의 영향에 대해 우려가 있는 것을 인정한다. 유해 콘텐츠 생성과 문제 연관성은 아직 AI 커뮤니티가 해결하지 못한 중요한 위험이다. 이 논문을 통해 이런 문제의 유병률을 줄이는 진전을 보였다. 더 많은 노력이 필요함을 인정하며, 이는 우리의 개방 과학 및 AI 커뮤니티와의 협력 약속을 강화한다.
Related Work
Large Language Models. 최근 몇 년간, GPT-3부터 과학 분야의 Galactica에 이르기까지 100B 이상 parameter를 가진 대규모 언어 모델(LLMs)이 크게 발전하였다. Chinchilla는 토큰 수에 중점을 두어 스케일링 법칙을 재정의했고, Llama는 추론 시의 계산 효율성으로 주목받았다. 또한, BLOOM, OPT, Falcon과 같은 오픈소스 모델이 GPT-3와 Chinchilla와 같은 클로즈소스 모델에 도전하면서 오픈소스와 클로즈소스 모델 간의 역학에 대한 논의가 활발히 이루어졌다.
ChatGPT, Bard, Claude와 같은 제품 출시 준비 상태의 LLM들은 성능과 사용성에서 차별화되며, 인간의 선호와 일치하기 위해 복잡한 튜닝에 의존한다. 이 과정은 오픈소스 커뮤니티에서 지속적으로 발전 중이다.
Vicuna와 Alpaca와 같은 증류 기반 모델들이 인공 지시를 사용한 학습 방법을 도입했지만, 클로즈소스 모델들이 설정한 기준에는 여전히 도달하지 못하였다.
Instruction Tuning. Wei et al. (2021)은 다양한 데이터 세트에서 LLM을 미세조정하여 보이지 않는 작업에서 zero-shot 성능을 달성하였다. instruction tuning의 영향을 조사하고, 이를 위한 프롬프트는 인간이나 LLM 자체에 의해 생성될 수 있다. 초기 생성물을 개선하기 위한 후속 지시 사용, 그리고 복잡한 문제 해결 시 모델의 추론 설명을 유도하는 사고 과정 프롬프팅 방식이 연구되었다.
RLHF는 성능 향상을 위한 대규모 언어 모델 미세 조정의 강력한 전략으로, 처음에는 텍스트 요약에서 시작해 다양한 분야로 확장되었다. 이 방식은 인간 사용자의 피드백을 통해 모델을 반복적으로 조정하여 인간의 기대와 선호에 부합하도록 한다.
Ouyang et al. (2022)은 지시 미세 조정과 RLHF의 결합이 LLMs의 사실성, 유해성, 유용성 문제를 해결할 수 있음을 보여주었다. Bai et al. (2022b)은 이를 부분적으로 자동화하는 RLAIF 방식을 도입하여, 인간 라벨 데이터와 평가자를 각각 모델의 자체 수정과 모델 평가로 대체하였다.
Known LLM Safety Challenges. 최근 연구는 대규모 언어 모델의 위험과 도전을 깊이 있게 조사하였다. 이는 편향, 유해성, 개인정보 유출, 악용 가능성 등을 포함한다. Solaiman et al. (2023)은 이 영향을 시스템 내외적으로 분류하고, Kumar et al. (2022)은 이를 줄일 전략을 제안한다. Roller et al. (2020)과 Dinan et al. (2021)은 챗봇 관련 LLM의 문제점을 지적하며, Deng et al. (2023)은 해결책을 위한 분류학적 프레임워크를, Bergman et al. (2022)은 대화 모델 출시의 긍정적 및 부정적 영향의 균형을 탐구한다.
레드 팀 조사를 통해 조정된 LLM에서의 도전 과제와 다양한 공격 유형 및 유해 콘텐츠 생성의 영향이 밝혀졌다. 또한, 국가 안보 기관과 연구자들은 고급 모델의 위험한 행동, 사이버 위협, 생물학적 전쟁의 잠재적 오용에 대해 경고하였다. AI 연구 가속화로 인한 일자리 대체와 LLM 의존도 증가로 인한 학습 데이터 퇴화 같은 사회적 문제들도 강조되었다. 이러한 문제들에 대해 정책, 학계, 산업 분야와의 지속적인 협력을 약속한다.
Conclusion
이 연구에서는 7B에서 70B parameter 범위의 새로운 모델 패밀리인 Llama 2를 소개하였다. 이 모델들은 기존 오픈소스 채팅 모델들과 경쟁력이 있으며 일부 독점 모델과 동등한 성능을 보이지만 GPT-4에는 여전히 미치지 못한다. 유용성과 안전성 원칙에 중점을 둔 방법론을 상세히 설명하였다. 사회 기여와 연구 진행을 위해 Llama 2와 Llama 2-Chat을 공개했으며, 투명성과 안전성 유지를 위해 Llama 2-Chat을 지속적으로 개선할 계획이다.