Abstract
Mistral 7B는 7B parameter를 갖춘 언어 모델로, 모든 벤치마크에서 Llama 2를 초월하고 추론, 수학, 코드 생성에서 Llama 1을 능가한다. 이 모델은 빠른 추론을 위한 GQA와 효율적인 시퀀스 처리를 위한 SWA를 특징으로 하며, 사람과 자동화된 평가에서 Llama 2 채팅 모델보다 우수한 Mistral 7B - Instruct 버전도 제공한다. Apache 2.0 라이센스로 공개된다.
Introduction
자연어 처리(NLP) 분야에서 모델 크기를 늘리며 성능을 향상시키는 추세에도 불구하고, 실제 배포에는 컴퓨팅 비용과 추론 지연의 장애가 있다. 이런 상황에서 고성능과 효율성을 겸비한 Mistral 7B 모델은 신중한 설계를 통해 높은 성능을 유지하며, 이전 모델들을 능가하고 특히 수학 및 코드 생성에서 우수한 결과를 보여주었다.
Mistral 7B는 grouped-query attention(GQA)와 sliding window attention(SWA)을 통해 추론 속도를 가속화하고 메모리 요구 사항을 줄이며, 더 긴 시퀀스 처리를 효율화하여 LLM의 한계를 완화한다. 이 기술들은 Mistral 7B의 성능과 효율성을 향상시키는 데 기여한다.
Mistral 7B는 Apache 2.0 라이선스로 출시되었으며, AWS, GCP, Azure 같은 클라우드 플랫폼이나 로컬에서 쉽게 배포할 수 있는 참조 구현을 포함한다. vLLM 추론 서버와 SkyPilot 2 사용 및 Hugging Face 3와의 간소화된 통합을 지원한다. 또한, 다양한 작업에 쉽게 미세 조정할 수 있도록 설계되었고, Llama 2 13B - Chat 모델보다 우수한 성능을 보이는 채팅 모델을 통해 그 적응성과 성능을 입증한다.
Mistral 7B는 높은 성능과 대규모 언어 모델의 효율성을 균형 있게 달성하였다. 이를 통해, 커뮤니티가 실제 응용 프로그램에 적합한 경제적이고 효율적인 고성능 언어 모델을 개발할 수 있도록 지원한다.
Architectural details
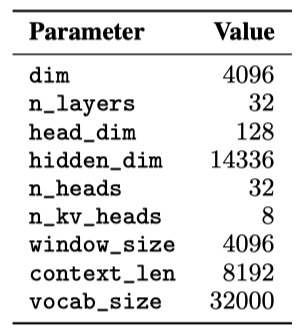
Mistral 7B는 transformer 아키텍처를 기반으로 한다.
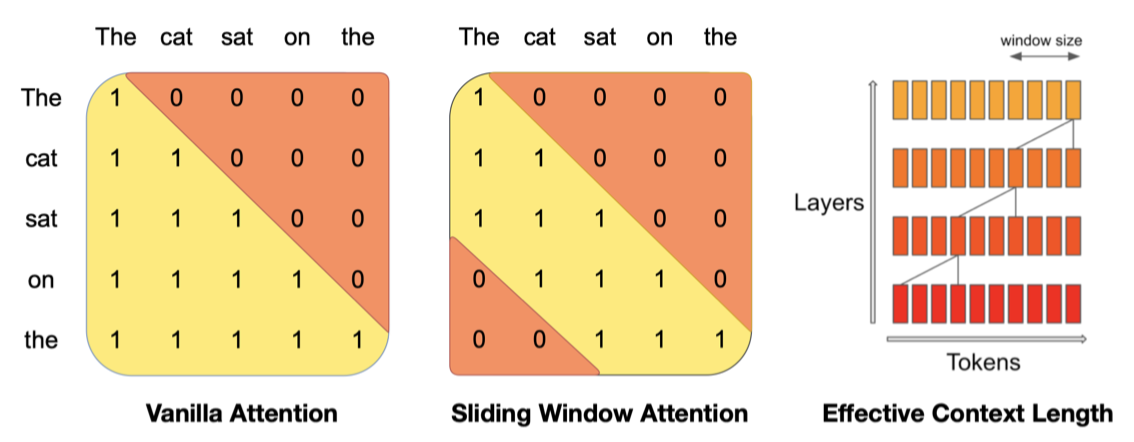
Sliding Window Attention. SWA는 transformer의 layer를 활용해 윈도우 크기 $W$를 초과하는 정보를 처리한다. 이 방식으로, 숨겨진 상태 $h_i$는 최대 $W × k$ 토큰 거리까지의 정보에 접근할 수 있으며, 마지막 layer에서는 약 131K 토큰까지 주목할 수 있다. 실제로, FlashAttention과 xFormers의 개선을 통해 기존 주의 메커니즘 대비 2배 빠른 속도를 달성한다.

Rolling Buffer Cache. 고정된 주의 범위 사용으로 롤링 버퍼 캐시를 통해 캐시 크기를 제한할 수 있다. 캐시는 $W$ 크기로 고정되어 있으며, 시간 단계 $i$의 키와 값은 캐시의 $i mod W$ 위치에 저장된다. 위치 $i$가 $W$를 초과하면 캐시 내 과거 값이 덮어쓰여지고 캐시 크기가 더이상 증가하지 않는다. 32k 토큰 시퀀스에서 이 방법은 모델 품질에 영향을 미치지 않고 캐시 메모리 사용을 8배 줄인다.
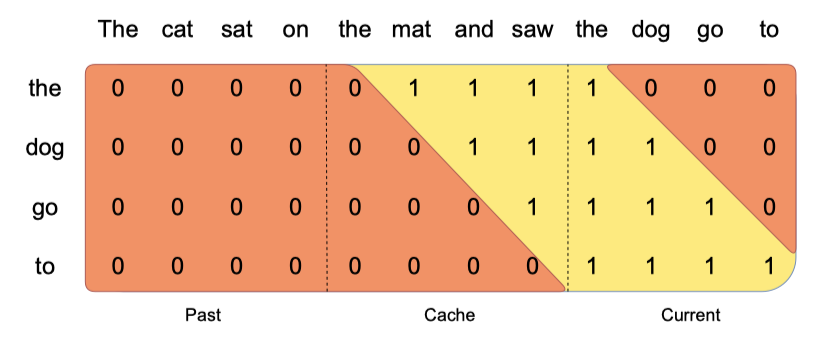
Pre-fill and Chunking. 시퀀스 생성 시 각 토큰은 이전 토큰에 의존하여 예측되어야 한다. 프롬프트가 미리 알려져 있기 때문에, $(k, v)$ 캐시를 프롬프트로 사전 채울 수 있다. 큰 프롬프트는 작은 조각으로 나누어 캐시에 사전 채움이 가능하며, 이 때 창 크기를 조각 크기로 설정할 수 있다. 각 조각마다 캐시와 조각 모두에 대한 주의 계산이 필요하다.
Results
Mistral 7B와 Llama를 비교하기 위해, 공정한 비교를 위해 자체 평가 파이프라인으로 모든 벤치마크를 재실행하며, 다양한 분류된 작업에서 성능을 측정한다.
- Commonsense Reasoning (0-shot): Hellaswag, Winogrande, PIQA, SIQA, OpenbookQA, ARC-Easy, ARC-Challenge, CommonsenseQA
- World Knowledge (5-shot): NaturalQuestions, TriviaQA
- Reading Comprehension (0-shot): BoolQ, QuAC
- Math: GSM8K (8-shot) with maj@8, MATH (4-shot) with maj@4
- Code: Humaneval (0-shot), MBPP (3-shot)
- Popular aggregated results: MMLU (5-shot), BBH (3-shot), AGI Eval (3-5-shot, English multiple-choice questions only)


Mistral 7B는 모든 지표에서 Llama 2 13B를 초과하고 대부분의 벤치마크에서 Llama 1 34B를 앞서며, 특히 코드, 수학, 추론 분야에서 우수한 성능을 보여준다.

Size and Efficiency. Llama 2 시리즈와 비교하여 Mistral 7B의 비용-성능 효율성을 평가하기 위해 동등한 모델 크기를 계산하였다. 결과적으로, Mistral 7B는 추론과 STEM 영역에서 자신의 크기보다 3배 이상 큰 Llama 2 모델과 유사한 성능을 보였으나, 지식 벤치마크에서는 제한된 parameter 수로 인해 1.9x 낮은 압축율을 달성하였다.
Evaluation Differences. 일부 벤치마크에서, 우리 평가 방식과 Llama 2 논문에서의 방식은 차이가 있다: 1) MBPP는 검증된 부분집합 사용, 2) TriviaQA는 위키피디아 컨텍스트 미제공.
Instruction Finetuning
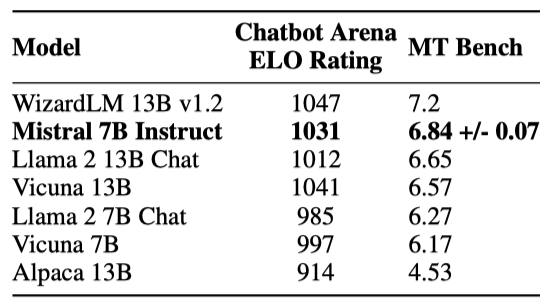
Mistral 7B 모델의 일반화 능력을 평가하기 위해, Hugging Face 저장소의 공개 지시 데이터셋을 사용하여 미세 조정을 진행하였다. 이 과정에서 독점 데이터나 특별 학습 기법은 사용되지 않았다. Mistral 7B - Instruct 모델은 기본 모델을 쉽게 미세 조정하여 좋은 성능을 달성할 수 있음을 보여주며, 모든 7B 모델을 능가하고 13B - Chat 모델과 비슷한 수준의 성능을 제시한다. 독립적인 인간 평가는 https://llmboxing.com/leaderboard에서 진행되었다.
이 평가에서 참가자들은 두 모델의 익명 응답 중 선호하는 것을 선택했고, 2023년 10월 6일까지 Mistral 7B의 응답이 5020회, Llama 2 13B의 응답이 4143회 선호되었다.
Adding guardrails for front-facing applications
AI 생성에 가드레일 적용은 사용자 상호작용 애플리케이션에서 중요하다. 이 섹션은 시스템 프롬프팅을 통해 모델에 출력 제약을 선택적으로 적용하는 방법과 Mistral 7B의 세밀한 콘텐츠 모더레이션 능력을 소개하여 애플리케이션의 고품질 콘텐츠 강제에 유용함을 강조한다.
System prompt to enforce guardrails

Always assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity.
모델이 지정된 가드레일 내에서 답변을 생성하도록 하는 시스템 프롬프트를 도입했으며, 이는 Llama 2와 유사한 작업이다. 이 프롬프트 사용을 통해 사용자는 모델 유틸리티와 가드레일 집행 사이의 파레토 최전선에서 움직일 수 있다.
안전성 평가를 위해 175개의 위험 프롬프트를 사용하며, 권장 시스템 프롬프트로 모델은 모든 해로운 질문에 대해 답변을 거부한다.

시스템 프롬프트 활성화 상태에서 ‘리눅스 프로세스 종료 방법’에 대한 Mistral 7B와 Llama 2의 반응을 볼 수 있다. Mistral 7B는 정답을 제공하고, Llama 2는 답변을 거부한다. 시스템 프롬프트 비활성화 시 두 모델 모두 이 질문에 정확히 답한다.
Content moderation with self-reflection
Mistral 7B - Instruct는 테러리즘, 아동 학대, 증오 콘텐츠, 부적합한 조언 등을 포함한 범주로 사용자 프롬프트나 답변을 정확히 분류할 수 있는 콘텐츠 모더레이터로 활용될 수 있다.
Mistral 7B의 자기 반성 기능을 평가하기 위해, 적대적 및 표준 프롬프트로 구성된 데이터셋을 사용하여 자기 반성 프롬프트를 설계하였다. 결과적으로, 수용 가능한 프롬프트를 긍정으로 보았을 때 99.4%의 정밀도와 95.6%의 재현율을 기록하였다.
사용 사례는 댓글 관리부터 브랜드 모니터링까지 다양하며, 최종 사용자는 필요에 따라 필터링할 카테고리를 선택할 수 있다.
Conclusion
Mistral 7B 연구는 언어 모델이 기존 생각보다 많은 지식을 압축할 수 있다고 밝혔다. 이는 모델 능력, 학습 비용, 추론 비용을 포함한 3차원 문제로, 최소한의 모델로 최적의 성능을 달성하기 위한 추가 탐색이 필요함을 시사한다.