Abstract
이 논문은 언어 모델의 zero-shot 학습 능력을 향상시키는 방법을 연구한다. “instruction tuning” 이라는 방법을 통해 미처 볼 수 없었던 작업에서의 zero-shot 성능을 크게 향상시킬 수 있음을 보여준다.
137B 개의 parameter를 가진 사전 학습된 언어 모델을 60개 이상의 NLP 데이터셋에 대한 instruction tuning을 통해, 이 모델인 FLAN은 보이지 않는 작업 유형에서 월등한 성능을 보여준다. FLAN은 여러 데이터셋에서 zero-shot GPT-3를 능가하고, 몇몇 작업에서는 few-shot GPT-3를 크게 앞선다.
Introduction
대규모 언어 모델은 few-shot 학습을 잘 수행하지만, zero-shot 학습에서는 성공적이지 못하며, 이는 사전 학습 데이터와 비슷하지 않은 프롬프트에서 모델이 작업을 수행하기 어렵기 때문일 수 있다.
이 논문에서는 대규모 언어 모델의 zero-shot 성능을 향상시키는 방법을 연구한다. 60개 이상의 NLP 데이터셋을 자연어 지시문으로 표현하여 137B parameter의 언어 모델을 미세 조정하는 방식을 사용한다. 이 결과 생성된 모델을 FLAN(Finetuned Language Net)이라고 한다.
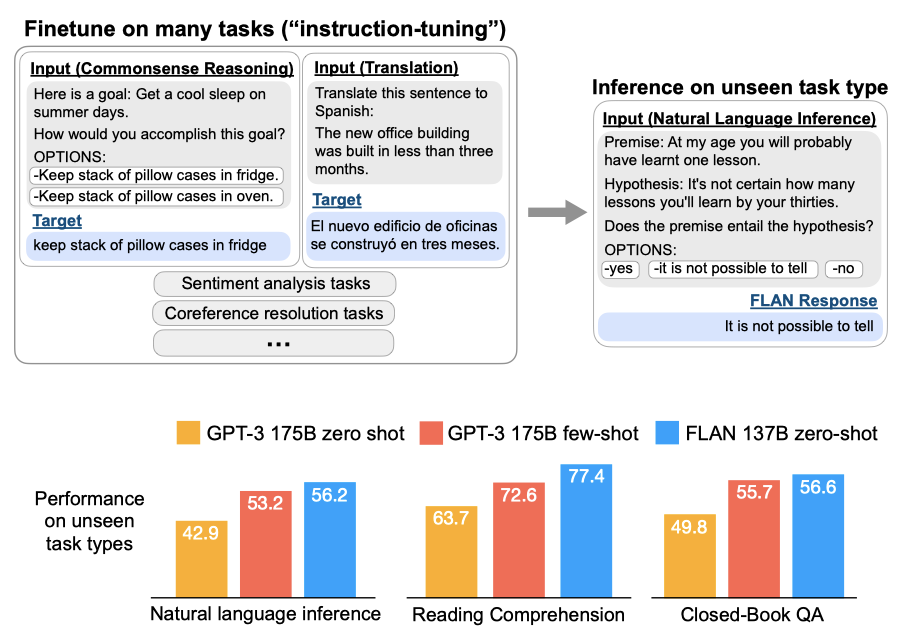
NLP 데이터셋을 작업 유형별로 그룹화하여 FLAN의 zero-shot 성능을 평가한다. 특정 작업(예: 자연어 추론)을 평가하기 위해 해당 작업을 제외한 다른 모든 작업에서 FLAN을 조정하고, 그 후에 zero-shot 자연어 추론 성능을 평가한다.
FLAN은 기본 137B-parameter 모델의 zero-shot 성능을 크게 향상시키며, 25개의 데이터셋 중 20개에서 GPT-3의 zero-shot을 능가한다. 또한 특정 작업에서는 GPT-3의 few-shot 성능까지 능가한다. instruction tuning에서 작업 클러스터 수를 늘리는 것이 성능을 향상시키며, 충분한 모델 규모에서만 instruction tuning의 이점이 나타난다.
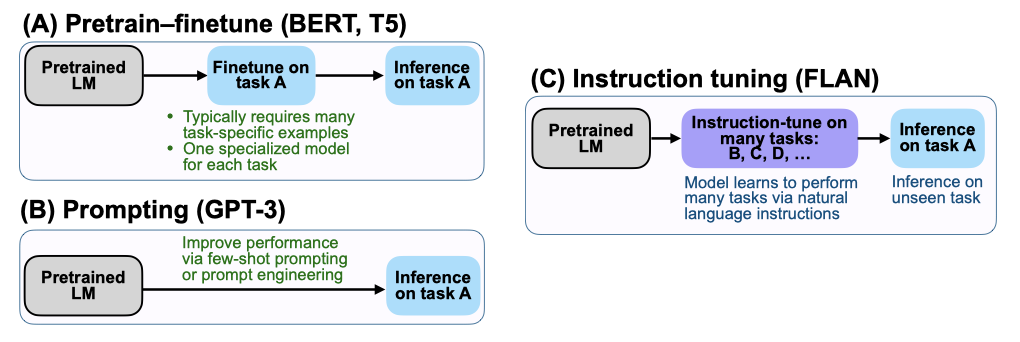
instruction tuning은 언어 모델이 추론 시 텍스트 상호작용에 더 잘 응답하도록 미세조정을 통한 지도학습을 사용하는 간단한 방법이다. 이 방법은 언어 모델이 지시문만을 통해 작업을 수행하는 능력을 보여준다.
FLAN: Instruction Tuning Improves Zero-Shot Learning
instruction tuning의 목표는 언어 모델이 NLP 지시문에 더 잘 응답하도록 향상시키는 것이다. 지시문을 통해 설명된 작업을 수행하도록 언어 모델을 교육함으로써, 보이지 않는 작업에 대해서도 지시문을 따를 수 있게 한다. 작업 유형별로 데이터셋을 그룹화하고, 남은 클러스터에서 instruction tuning을 하면서 볼 수 없는 작업의 성능을 평가한다.
Tasks & Templates
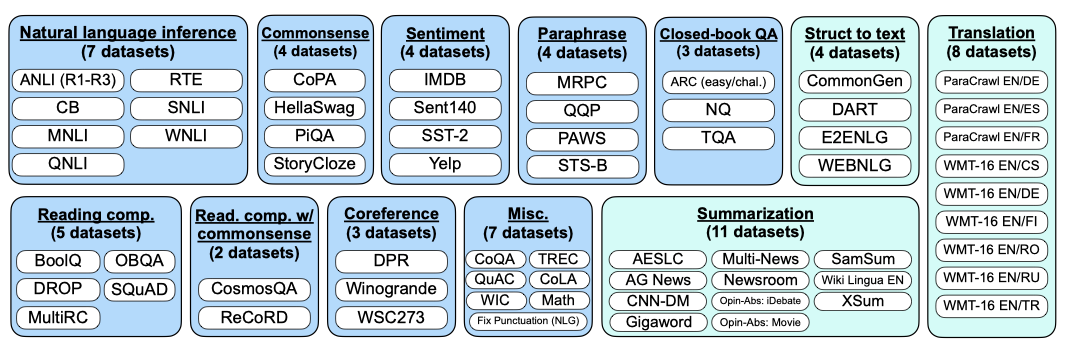
기존의 연구 데이터셋을 지시문 형식으로 변환하여, 자원 집약적인 새로운 데이터셋 생성을 피한다. Tensorflow Datasets에서 공개적으로 이용 가능한 62개의 텍스트 데이터셋을 하나의 혼합물로 집계하며, 이 데이터셋들은 12개의 작업 클러스터 중 하나로 분류된다.
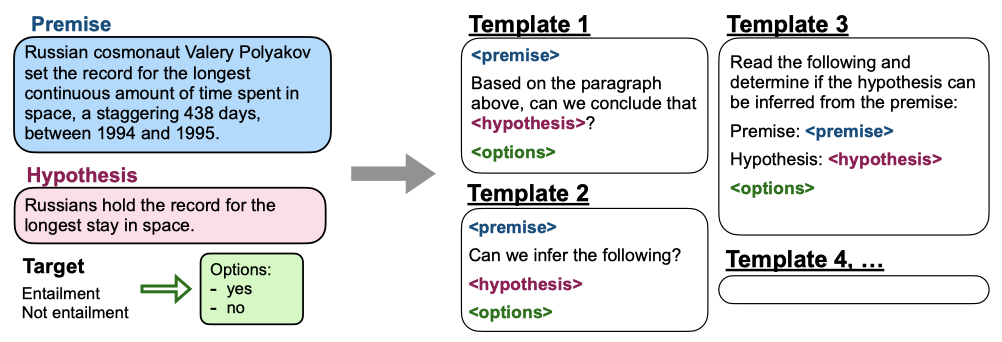
각 데이터셋에 대해, 작업을 설명하는 10개의 고유한 자연어 지시문 템플릿을 작성하며, 다양성을 높이기 위해 일부 템플릿은 원래의 작업을 뒤집는 방식으로 구성된다. 이후 모든 데이터셋의 혼합물에서 사전 학습된 언어 모델을 instruction tuning하며, 각 데이터셋의 예제는 해당 데이터셋에 대한 무작위로 선택된 지시 템플릿으로 형식화된다.
Evaluation Splits
FLAN이 instruction tuning에서 본적 없는 작업에 대해 어떻게 수행하는지를 알고자 한다. 본적 없는 작업을 정의하기 위해, instruction tuning 중에 보지 않은 작업 클러스터에 속한 모든 데이터셋을 본적 없는 것으로 간주한다. 따라서, 특정 작업 클러스터에서 zero-shot FLAN을 평가하려면, 각각 다른 작업 클러스터를 보류한 모델을 instruction tuning합니다.
Classification With Options
작업의 출력 공간은 클래스 중 하나(classification) 또는 자유 텍스트(generation)이 된다. FLAN은 decoder만 있는 언어 모델의 지시 조정 버전이므로, 생성 작업에 대한 추가 수정 없이도 자유 텍스트로 자연스럽게 응답한다.
분류 작업에서는 “예"와 “아니오"와 같은 두 가지 출력만 고려하는 순위 분류 방법을 사용하였다. 하지만 이 방법은 답변의 확률 분포가 원치 않는 방식으로 나타날 수 있다. 따라서, 분류 작업의 끝에 OPTIONS 토큰과 해당 작업의 출력 클래스 목록을 추가하여 모델이 분류 작업에 응답할 때 원하는 선택지를 인식하게 한다.
Training Details
Model architecture and pretraining. 137B parameter의 LaMDA-PT라는 decoder-only transformer 언어 모델을 사용한다. 이 모델은 웹 문서, 대화 데이터, 위키백과 등을 통해 사전 학습되었고, SentencePiece 라이브러리를 사용해 32k 어휘로 토큰화되었다. 사전 학습 데이터의 약 10%는 비영어이다. LaMDA-PT는 언어 모델 사전 학습만을 가지고 있다.
Instruction tuning procedure. FLAN은 LaMDA-PT의 instruction tuning 버전이다. 모든 데이터셋을 혼합하여 무작위로 샘플링하며, 데이터셋 당 최대 30k의 학습 예제를 사용한다. 모델은 30k의 그래디언트 단계 동안 미세조정되며, 입력 시퀀스와 목표 시퀀스의 길이는 각각 1024와 256입니다. 이 튜닝 과정은 TPUv3에서 약 60시간이 소요된다.
Results
FLAN은 다양한 작업들에서 평가되며, 이는 natural language inference, reading comprehension, closed-book QA, translation, commonsense reasoning, coreference resolution, struct-to-text 등을 포함한다. 각 작업 클러스터는 다른 체크포인트를 사용하며, 각 데이터셋의 성능은 모든 템플릿에 대한 평균 성능으로 평가된다. 또한, 개발 세트의 성능이 가장 좋은 템플릿을 사용하여 테스트 세트의 성능도 측정한다.
LaMDA-PT의 zero-shot과 few-shot 결과를 GPT-3의 프롬프트와 동일하게 보고한다. 이는 instruction tuning이 얼마나 효과적인지 직접적으로 보여주는 기준선이다. 결과적으로, instruction tuning은 대부분의 데이터셋에서 LaMDA-PT의 성능을 크게 향상시켰다.
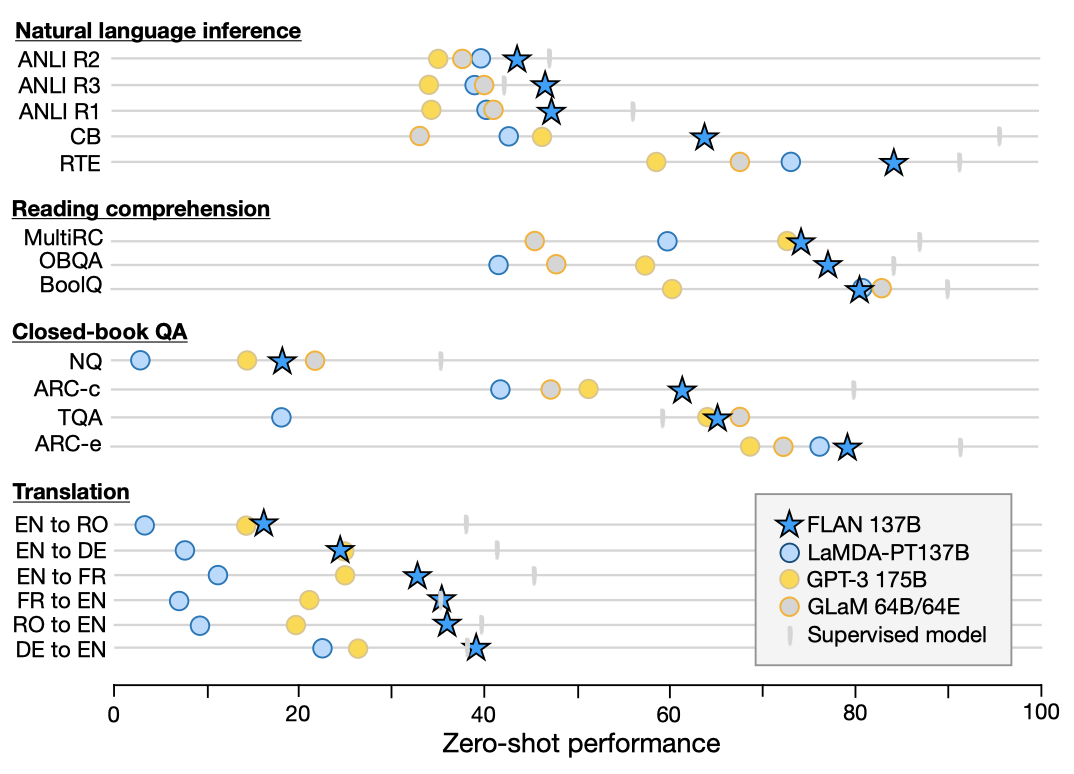
zero-shot FLAN은 25개 데이터셋 중 20개에서 GPT-3 175B를 능가하며, 19개 데이터셋 중 13개에서는 GLaM 64B/64E를 능가한다.
instruction tuning은 NLI, QA, translation, struct-to-text 등의 과제에 효과적이며, 언어 모델링으로 직접 구성된 과제에서는 효과적이지 않다.
Natural language inference (NLI). 5개의 NLI 데이터셋에서, FLAN은 모든 기준 모델을 크게 능가했습니다. FLAN은 NLI를 “Does mean that ?“라는 더 자연스러운 질문으로 표현하여 훨씬 높은 성능을 보여주었다.
Reading comprehension. FLAN은 MultiRC와 OBQA에서 기준 모델을 능가하였다. 또한, BoolQ에서는 GPT-3를 크게 능가하였다.
Closed-book QA. FLAN은 모든 네 개의 데이터셋에서 GPT-3를 능가하였다. ARC-e와 ARC-c에서는 GLaM보다 더 좋은 성능을 보였지만, NQ와 TQA에서는 약간 낮은 성능을 보였다.
Translation. FLAN은 GPT-3 논문에서 평가된 세 개의 데이터셋인 프랑스어-영어, 독일어-영어, 루마니아어-영어에 대한 기계 번역 성능을 평가하였다. FLAN은 모든 평가에서 zero-shot GPT-3를 능가했지만, 대부분의 경우 few-shot GPT-3보다 성능이 떨어졌다. FLAN은 영어로 번역하는 데 강한 결과를 보였지만, 영어에서 다른 언어로 번역하는 것은 상대적으로 약했다.
Additional tasks. instruction tuning은 많은 언어 모델링 과제의 성능을 향상시키지 못하는 한계가 있다. 7개의 상식 추론 및 공통 참조 해결 과제 중 FLAN은 3개 과제에서만 LaMDA-PT를 능가하였다. 하지만, zero-shot FLAN은 일반적으로 zero-shot LaMDA-PT를 능가하며, few-shot LaMDA-PT와 비슷하거나 더 나은 성능을 보여주었다.
Ablation Studies & Further Analysis
Number Of Instruction Turning Clusters
이 연구에서는 instruction tuning이 어떻게 모델의 zero-shot 성능을 향상시키는지를 중점으로 살펴보았다. 첫 번째 축소 실험에서는 instruction tuning에 사용된 클러스터와 과제의 수가 성능에 어떻게 영향을 미치는지를 검토하였다. 이때 NLI, closed-book QA, commonsense reasoning을 평가 클러스터로 보류하고, 나머지 클러스터를 instruction tuning에 사용하였다.
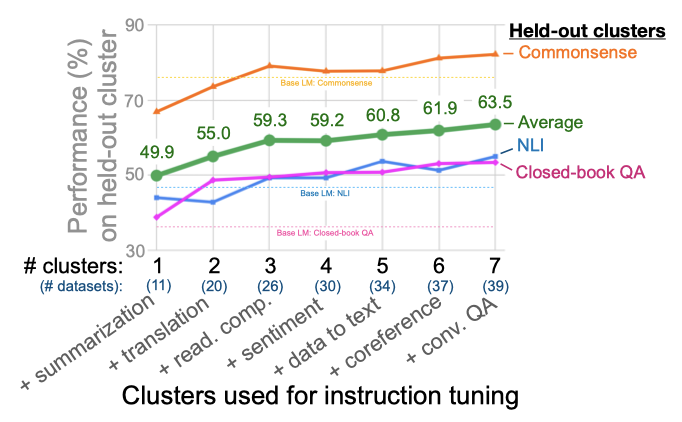
instruction tuning에 추가 클러스터와 과제를 추가하면, 보류된 세 개의 클러스터에서의 평균 성능이 향상됨을 확인했다. 테스트한 일곱 개의 클러스터에서 성능이 포화되지 않아 보이므로, instruction tuning에 더 많은 클러스터가 추가되면 성능이 더욱 향상될 수 있을 것으로 보인다. 하지만, 감정 분석 클러스터에서는 최소한의 추가 가치만을 볼 수 있었다.
Scaling Laws
언어 모델의 zero-shot과 few-shot 능력이 더 큰 모델에 대해 크게 향상된다는 연구 결과를 바탕으로, instruction tuning의 이점이 모델 규모에 어떻게 영향을 받는지를 살펴보았다. 모델 규모를 422M, 2B, 8B, 68B, 137B로 설정하고 instruction tuning의 효과를 평가하였다.
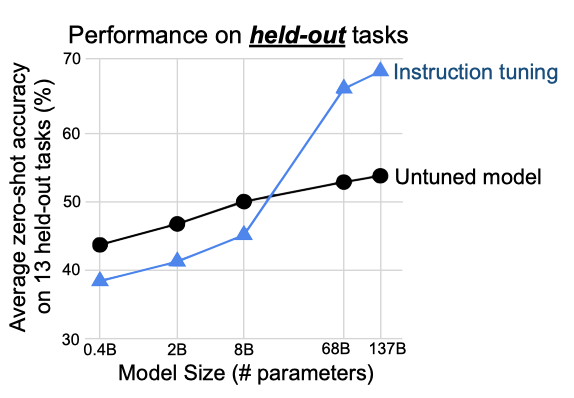
100B parameter 규모의 두 모델에서는 instruction tuning이 보류된 과제에서의 성능을 크게 향상시켰다. 그러나, 8B 및 더 작은 모델에서는 instruction tuning이 보류된 과제에서의 성능을 저하시켰다. 이는 작은 규모의 모델에서 instruction tuning 중 사용되는 과제를 학습하는 것이 모델의 전체 용량을 차지하게 되어, 새로운 과제에서 성능이 떨어지게 만들 수 있기 때문일 수 있다.
Role Of Instructions
마지막 ablation study에서는 미세 조정 중 지시문의 역할을 살펴보았다. 지시문 없이 모델이 어떻게 수행하는지 살펴보기 위해, 지시문이 없는 두 가지 미세 조정 설정을 고려하였다. 하나는 템플릿이 없는 설정으로, 모델에게 입력과 출력만이 주어지는 것이고, 다른 하나는 데이터셋 이름 설정으로, 각 입력이 과제와 데이터셋의 이름으로 시작된다.
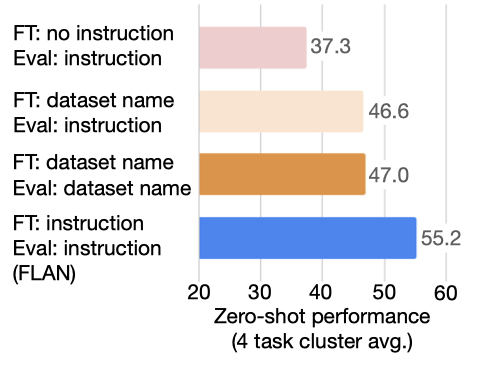
자연스러운 지시문을 사용한 FLAN의 미세 조정 절차와 두 가지 ablation study을 비교하였다. 이 두 ablation study는 각각 템플릿이 없는 설정과 데이터셋 이름만을 사용한다. 결과에서 두 축소 설정 모두 FLAN보다 훨씬 나쁜 성능을 보여, 보이지 않는 과제에서의 zero-shot 성능에 지시문을 사용한 학습이 결정적임을 나타냈다.
Instructions With Few-Shot Exemplars
few-shot 예시가 추론 시간에 사용 가능할 때 instruction tuning이 어떻게 사용될 수 있는지 연구하였다. few-shot 설정의 형식은 zero-shot 형식을 기반으로 한다. 학습 시간과 추론 시간 모두에서 예시는 학습 세트에서 무작위로 추출되며, 예시의 수는 16개로 제한하고 전체 시퀀스 길이가 960 토큰 미만이 되도록 했다. 실험은 보이지 않는 과제에 대한 few-shot 예시를 오직 추론 시간에만 사용하는 동일한 과제 분할과 평가 절차를 사용하였다.
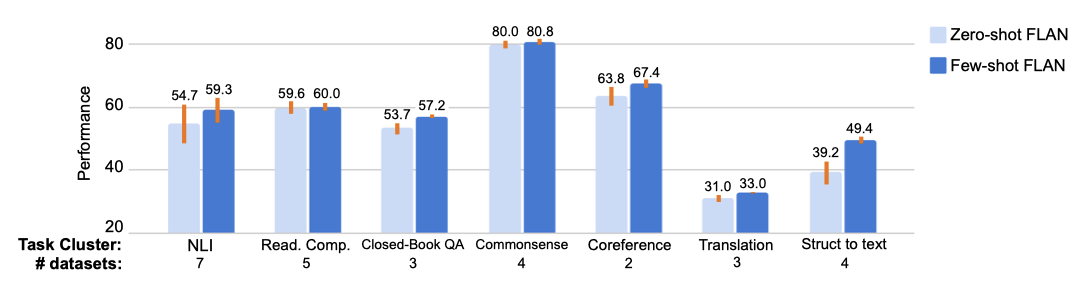
few-shot 예시는 zero-shot FLAN에 비해 모든 과제 클러스터의 성능을 향상시킨다. 예시는 특히 크거나 복잡한 출력 공간을 가진 과제에 효과적이며, 이는 예시가 모델이 출력 형식을 더 잘 이해하는 데 도움이 되기 때문일 가능성이 있다. 또한, 모든 과제 클러스터에서 템플릿 간의 표준 편차는 퓨샷 FLAN에서 더 낮아, 프롬프트 엔지니어링에 대한 민감도가 줄어든 것을 나타낸다.
Instruction Turning Facilitates Prompt Turning
instruction tuning이 모델의 지시문에 대한 반응 능력을 향상시키는 것을 확인했기 때문에, FLAN이 NLP 과제를 수행하는 데 더 적합하다면, 소프트 프롬프트를 사용하여 추론을 수행할 때도 더 나은 성능을 달성해야 한다. 추가 분석으로, SuperGLUE 과제 각각에 대해 연속 프롬프트를 훈련시켰고, 이는 특정 과제에 대한 프롬프트 튜닝을 수행할 때, 동일한 클러스터에 있는 다른 과제가 instruction tuning 동안 보이지 않게 하는 클러스터 분할을 따랐다. 프롬프트 튜닝 설정은 Lester et al.의 절차를 따르되, 몇 가지 변화를 주었고, 이 변화들이 LaMDA-PT의 성능을 향상시키는 것으로 확인되었다.
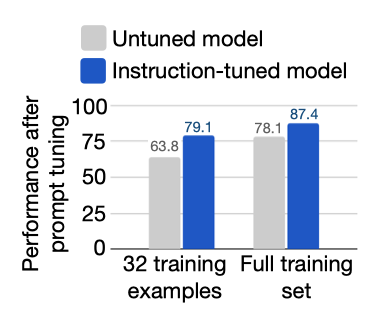
모든 시나리오에서 프롬프트 튜닝은 LaMDA-PT보다 FLAN에서 더 잘 작동하였다. 특히 low-resource 설정에서는, FLAN에서의 프롬프트 튜닝이 LaMDA-PT에서의 것보다 10% 이상 성능이 향상되었다. 이 결과는 instruction tuning이 NLP 과제를 수행하는 데 더 바람직한 모델을 만드는 데 어떻게 기여할 수 있는지를 보여준다.
Related Work
이 논문은 zero-shot 학습, 프롬프팅, 다중 과제 학습, NLP 응용 프로그램을 위한 언어 모델 등 여러 넓은 연구 영역과 관련이 있다. 이러한 넓은 영역에 대한 이전 연구를 확장된 관련 연구 섹션에서 설명하고, 이 논문의 연구와 가장 밀접하게 연관된 범위가 좁은 두 개의 하위 영역을 설명하였다.
모델에 지시문에 대한 반응을 요청하는 방식은 QA 기반 과제 구성과 유사하며, 이는 NLP 과제를 통일하는 것을 목표로 한다. 이 방법들은 주로 다중 과제 학습에 초점을 맞추며, 사전 학습된 LMs의 기존 지식을 사용하는 것에 크게 기반하지 않는다. 이 연구의 작업은 모델 규모와 과제 범위 모두에서 최근의 일부 연구를 초월한다.
언어 모델의 성공으로 모델이 지시문을 따르는 능력에 대한 연구가 진행되고 있다. 최근 연구에서는 지시문과 few-shot 예시를 이용해 BART를 미세 조정하고, 이를 통해 보이지 않는 과제에 대한 few-shot 성능을 향상시킬 수 있음을 보여주었다. 또한, T5를 미세 조정하는 등의 방법으로 zero-shot 학습을 개선하고, 미세 조정과 강화 학습을 병행하여 인간 평가자가 선호하는 출력을 생성하는 연구도 있다.
Discussion
지시문으로 표현된 여러 과제에 대해 모델을 미세 조정하면 보이지 않는 과제에서의 성능이 향상된다는 것을 보여주었다. FLAN은 미세 조정되지 않은 모델보다 성능이 좋고, zero-shot GPT-3를 능가한다. 또한, 충분한 모델 규모에서만 instruction tuning에 의한 성능 향상이 나타나며, 이는 다른 프롬프팅 방법과도 결합될 수 있다.
언어 모델의 다양한 능력은 specialist 모델과 generalist 모델 사이의 균형에 대한 관심을 끌어내었다. 레이블이 있는 데이터가 specialist 모델을 개선하는 데 도움이 될 것으로 예상되지만, instruction tuning을 통해 이 데이터가 큰 언어 모델이 보이지 않는 다양한 과제를 수행하는 데도 도움이 될 수 있음을 보여주었다. 이는 과제 특정 학습이 일반 언어 모델링과 보완적이라는 것을 보여주며, generalist 모델에 대한 추가 연구를 촉진한다.
이 연구의 한계점은 과제를 클러스터에 할당하는 데 있는 주관성과 짧은 지시문의 사용에 대한 연구의 한정성이다. 개별 예시가 모델의 사전 훈련 데이터에 포함되어 있을 수 있지만, 이것이 결과에 크게 영향을 미쳤다는 증거는 찾지 못하였다. 또한, FLAN 137B의 규모는 그것을 서비스하는 데 비용이 많이 든다. 향후 instruction tuning 연구는 더 많은 과제 클러스터를 수집하고, 다언어 실험을 진행하며, downstream classifier 학습 데이터를 생성하고, 편향과 공정성에 대한 모델 행동을 개선하는 방향으로 진행될 수 있다.
Conclusions
이 논문은 지시문에 기반한 zero-shot 과제를 수행하는 대규모 언어 모델의 능력을 향상시키는 간단한 방법을 연구하였다. FLAN은 GPT-3에 비해 더 우수한 결과를 보여주며, 대규모 언어 모델이 지시문을 따를 수 있는 잠재력을 보여주었다.