Abstract
최근의 연구는 대량의 텍스트 말뭉치로 사전 학습한 후 특정 작업에 대해 미세 조정하는 것으로 많은 NLP 작업과 벤치마크에서 상당한 성과를 보여주었다. 일반적으로 과제에 중립적인 구조를 가지지만, 이 방법은 여전히 수천 개 또는 수만 개의 예제로 이루어진 과제별 미세 조정 데이터셋을 필요로 한다. 인간은 보통 몇 가지 예제나 간단한 지시사항만으로도 새로운 언어 작업을 수행할 수 있지만, 현재의 NLP 시스템은 이를 여전히 어려워한다. 이 연구에서는 언어 모델의 규모를 확장함으로써 과제 중립적이고 소수의 예제로 이루어진 작업 성능을 크게 개선하는 것을 보여준다. 때로는 이전의 state-of-the-art 미세 조정 접근법과 경쟁력을 갖출 수도 있다. 구체적으로, 1750억 개의 parameter를 가진 GPT-3라는 autoregressive 언어 모델을 학습시키고, 이를 소수의 예제로 평가해보았다. 모든 작업에서 GPT-3는 어떠한 그래디언트 업데이트나 미세 조정 없이 적용되며, 작업 및 소수의 예제는 모델과의 텍스트 상호작용을 통해 명시된다. GPT-3는 번역, 질의응답, 문맥 채우기 작업뿐만 아니라 단어 섞기, 새로운 단어를 문장에 사용하기, 3자리 산술 연산을 수행하는 등의 실시간 추론이나 도메인 적응이 필요한 작업과 같은 많은 NLP 데이터셋에서 강력한 성능을 보여주었다. 한편, GPT-3의 소수 학습은 여전히 어려운 몇몇 데이터셋과 대규모 웹 말뭉치에서의 훈련에 관련된 방법론적 문제가 있다는 점도 확인했다. 마지막으로, GPT-3는 인간 평가자가 사람이 작성한 기사와 구분하기 어려운 뉴스 기사 샘플을 생성할 수 있음을 발견하였다.
Introduction
최근 NLP 시스템은 사전 학습된 언어 표현을 다양한 작업에 유연하게 적용하는 추세가 있다. 초기에는 단어 벡터를 사용한 단일 계층 표현을 과제 특정 아키텍처에 적용했으나, 후에는 RNN을 사용한 다계층 표현을 도입하였다. 최근에는 과제 특정 아키텍처의 필요성을 완전히 제거하고, 사전 학습된 recurrent 또는 transformer 언어 모델을 직접 미세 조정하는 방식이 사용되고 있다.
이러한 패러다임은 많은 어려운 작업에서 진전을 이루었지만, 여전히 작업 특정 데이터셋과 미세 조정이 필요한 한계가 있다. 원하는 작업에서 높은 성능을 달성하기 위해 수천에서 수십만 개의 예제로 이루어진 작업 특정 데이터셋에서 미세 조정이 필요하다. 이러한 한계를 제거하는 것이 중요하다.
실용적인 관점에서, 모든 새로운 작업에 대한 대규모 레이블링된 예제 데이터셋의 필요성은 언어 모델의 적용 범위를 제한한다. 유용한 언어 작업의 범위는 매우 넓지만, 많은 작업들에 대해 큰 규모의 지도 학습 데이터셋을 수집하는 것은 어렵고, 이 과정이 각각의 새로운 작업마다 반복되어야 한다.
학습 데이터의 거짓 상관관계를 이용하는 가능성은 모델의 표현력과 학습 분포의 좁음에 따라 증가하며, 이는 사전 학습 후 미세 조정 패러다임에 문제를 일으킬 수 있다. 모델은 사전 학습 동안 정보를 흡수하기 위해 크게 설계되지만, 후에는 좁은 작업 분포에서 미세 조정되며, 이로 인해 학습 분포에 과도하게 특화되어 분포 외부에서는 잘 일반화되지 않을 수 있다. 따라서, 미세 조정된 모델의 성능은 실제 기본 작업에 대한 성능을 과장할 수 있다.
인간은 대부분의 언어 작업을 배우기 위해 큰 규모의 지도 학습 데이터셋을 필요로 하지 않는다. 간단한 지시사항이나 몇 가지 예제만으로도 새로운 작업을 수행할 수 있다. 이런 적응성은 인간이 여러 작업과 기술을 자연스럽게 섞거나 전환할 수 있게 한다.
이러한 문제를 해결하기 위한 한 방법은 메타 학습이다. 이는 언어 모델이 훈련 시에 다양한 기술과 패턴 인식 능력을 개발하고, 추론 시에 이를 활용해 원하는 작업에 빠르게 적응하거나 인식하도록 하는 것을 의미한다. 최근 연구에서는 “in-context learning"을 통해 이를 시도하였는데, 이는 모델이 자연 언어 지시사항이나 작업의 몇 가지 예제에 조건화되어, 단순히 다음에 무엇이 오는지 예측하여 작업을 완성하도록 하는 방식이다.
메타 학습 방법은 약간의 잠재력을 보였지만, 미세 조정에 비해 성능이 크게 떨어진다. 특히, Natural Questions에서는 4%, CoQa에서는 55 F1이라는 결과를 보였는데, 이는 최신 기술에 비해 크게 뒤처져 있다. 따라서 메타 학습이 언어 작업을 해결하는 실질적인 방법이 되려면 큰 개선이 필요하다.
최근 언어 모델링은 transformer 언어 모델의 용량이 크게 증가하는 추세를 보이고 있다. parameter 수가 100M에서 시작해 최근에는 17B개에 이르렀고, 이런 증가는 텍스트 합성과 NLP 작업에서 성능 개선을 가져왔다. 로그 손실이 규모와 함께 개선되는 추세를 보이기 때문에, 문맥 내 학습 능력도 규모와 함께 크게 향상될 수 있을 것으로 보인다.
이 논문에서는 175B 개의 parameter를 가진 언어 모델, GPT-3의 학습과 그 문맥 내 학습 능력을 테스트한다. GPT-3는 다양한 NLP 데이터셋과 새로운 작업들에 대해 평가되며, 각 작업은 “few-shot learning”, “one-shot learning”, “zero-shot” 학습의 세 가지 조건 하에서 평가된다. GPT-3는 원칙적으로 미세 조정 설정에서도 평가될 수 있지만, 이는 미래의 연구로 남겨두었다.
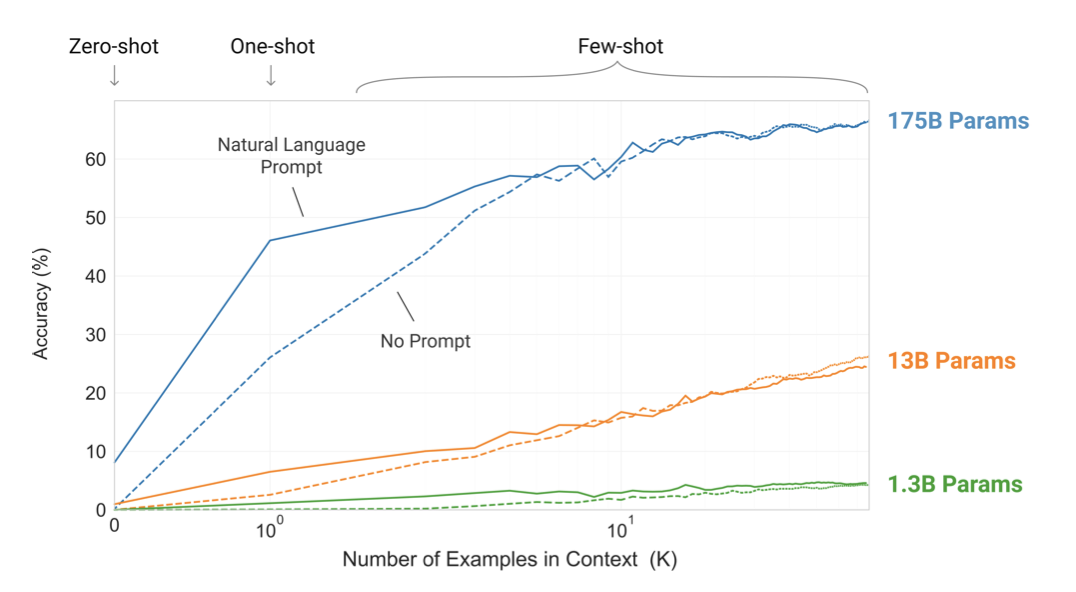
자연 언어 작업 설명과 문맥 내 예제 수가 늘어날수록 모델의 성능이 향상되며, 모델 크기가 커질수록 few-shot learning이 크게 향상된다. 이러한 학습 곡선은 미세 조정이나 그래디언트 업데이트 없이, 단순히 제공된 데모 수를 늘려가며 이루어진다.
GPT-3는 NLP 작업에서 zero-shot과 one-shot 설정에서 좋은 결과를 보이며, few-shot 설정에서는 때때로 state-of-the-art 모델과 경쟁하거나 초과한다. 예컨대, GPT-3는 CoQA에서 zero-shot에서 81.5 F1, one-shot에서 84.0 F1, few-shot에서 85.0 F1을 달성하였다. 비슷하게, TriviaQA에서는 zero-shot에서 64.3%, one-shot에서 68.0%, few-shot에서 71.2%의 정확도를 보여주었다.
GPT-3는 unscrambling words, performing arithmetic 등의 작업에서 one-shot과 few-shot 능력을 보여준다. 또한, GPT-3는 few-shot 설정에서 사람들이 인간이 만든 기사와 구별하기 어려운 합성 뉴스 기사를 생성할 수 있다.
GPT-3의 규모에도 불구하고, ANLI와 같은 자연어 추론 작업이나 RACE, QuAC과 같은 일부 읽기 이해 데이터셋에서 few-shot 성능이 어려움을 겪는 일부 작업들을 발견하였다.
“data contamination"에 대한 체계적인 연구를 수행하였다. 이는 테스트 데이터셋의 콘텐츠가 웹에 존재하기 때문에, Common Crawl과 같은 데이터셋에서 모델을 학습시킬 때 발생할 수 있는 문제이다. data contamination이 대부분의 데이터셋에서 GPT-3의 성능에 미치는 영향은 적지만, 결과가 과대 평가될 수 있는 몇몇 데이터셋을 식별하였다.
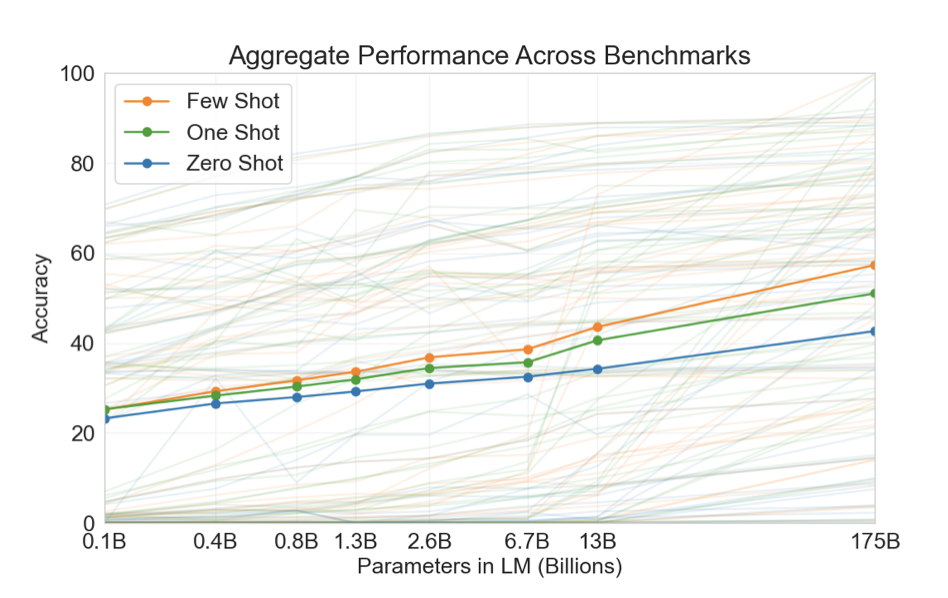
더 작은 모델들을 학습시켜 성능을 zero, one, few-shot 설정에서 GPT-3와 비교하였다. 대부분의 작업에서 모델 용량과 함께 성능이 상대적으로 부드럽게 스케일링되는 것을 보았다. 특히, 모델 용량이 커짐에 따라 zero, one, few-shot 성능 간의 차이가 더욱 커지는 것으로 보아, 큰 모델이 더 능숙한 메타 학습자일 수 있음을 시사한다.
마지막으로, GPT-3가 보여주는 넓은 범위의 능력에 대해, 편향, 공정성, 그리고 보다 넓은 사회적 영향에 대한 우려를 논의하고, 이러한 관점에서 GPT-3의 특성에 대한 초기 분석을 시도한다.
Approach
GPT-3의 사전 학습 접근법은 기존의 방법과 유사하나, 모델 크기, 데이터셋 크기 및 다양성, 학습 기간을 확장하였다. 컨텍스트 내에서 학습하는 다양한 설정을 체계적으로 탐색하였고, 이러한 설정은 작업 특정 데이터에 얼마나 의존하는지에 따라 다르게 위치할 수 있다. 스펙트럼에서는 적어도 네 가지 주요 포인트를 식별할 수 있다:
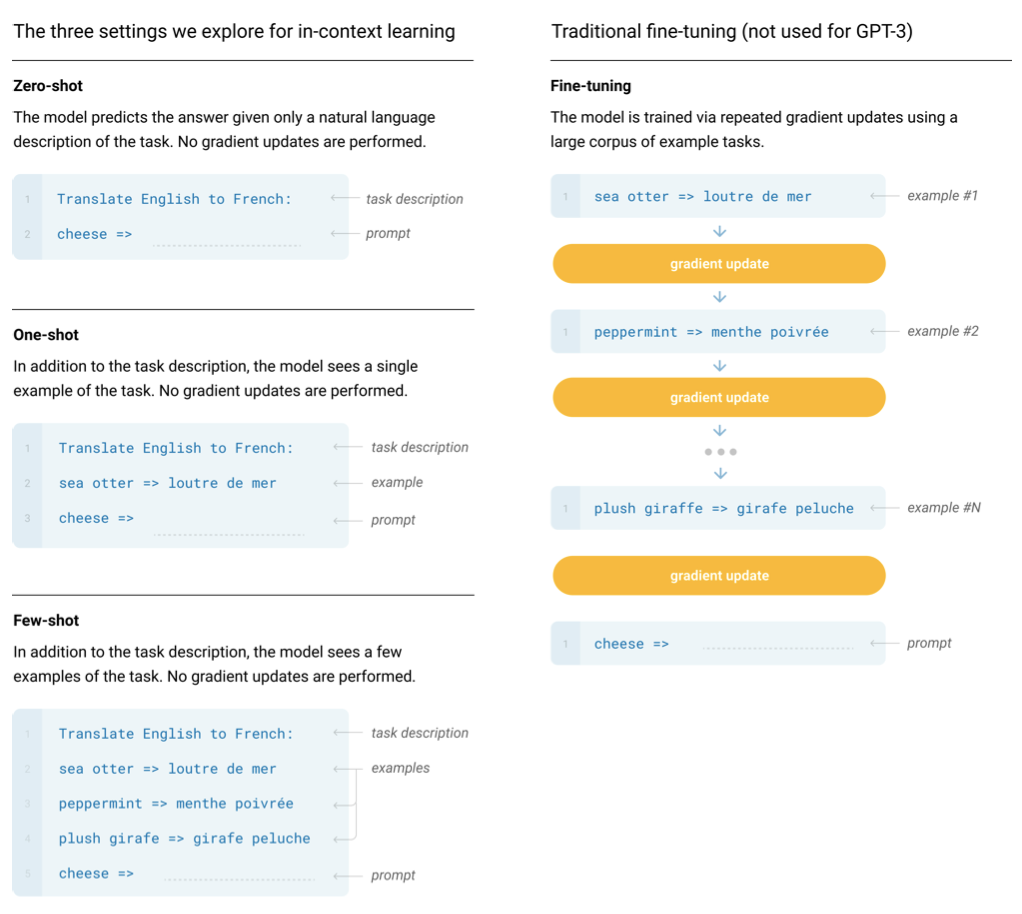
Fine-Tuning (FT) 최근 방식은 원하는 작업에 맞는 감독 데이터셋으로 사전 학습된 모델의 가중치를 업데이트하는 것이다. 이 방법의 이점은 많은 벤치마크에서 강력한 성능을 보여준다는 것이고, 단점은 각 작업마다 새로운 대규모 데이터셋이 필요하고, 분포 외에서는 일반화가 잘 안 될 수 있으며, 학습 데이터의 임의적인 특징을 이용할 수 있다는 것이다.
Few-Shot (FS) 모델이 추론 시간에 작업의 몇 가지 예시를 조건으로 받지만 가중치 업데이트는 허용되지 않는 설정이다. 이 방법의 장점은 작업 특정 데이터에 대한 요구가 크게 줄어들고, 과도하게 좁은 분포를 학습하는 가능성이 줄어든다는 것이다. 단점은 이 방법의 결과가 미세 조정된 최신 모델보다 낮았다는 것이며, 작은 양의 작업 특정 데이터가 여전히 필요하다. few-shot 학습은 넓은 작업 분포를 기반으로 학습하고, 새로운 작업에 빠르게 적응하는 것을 포함한다.
One-Shot (1S) 작업에 대한 자연어 설명 외에 하나의 예시만 허용된다는 점에서 few-shot과 다르다. one-shot은 일부 작업이 사람들에게 전달되는 방식과 가장 일치하기 때문에 few-shot과 zero-shot과 구별된다.
Zero-Shot (0S) 자연어 지시문만 모델에게 제공되며, 예시는 허용되지 않는 방식이다. 이 방법은 최대한의 편리성을 제공하지만, 가장 도전적인 설정이기도 하다. 예시 없이 작업의 형식을 이해하는 것은 어려울 수 있지만, zero-shot은 사람들이 작업을 수행하는 방식과 가장 가깝다.
Model and Architectures
GPT-2와 동일한 모델과 아키텍처를 사용하면서, transformer 계층에서 alternating dense 패턴과 locally banded sparse attention 패턴을 교대로 사용하는 점이 다르다. 모델 크기에 따른 ML 성능의 의존성을 연구하기 위해, 125M 개의 parameter에서 175B 개의 parameter까지 다양한 크기의 8가지 모델을 훈련시켰다. 가장 큰 모델을 GPT-3라고 부른다.
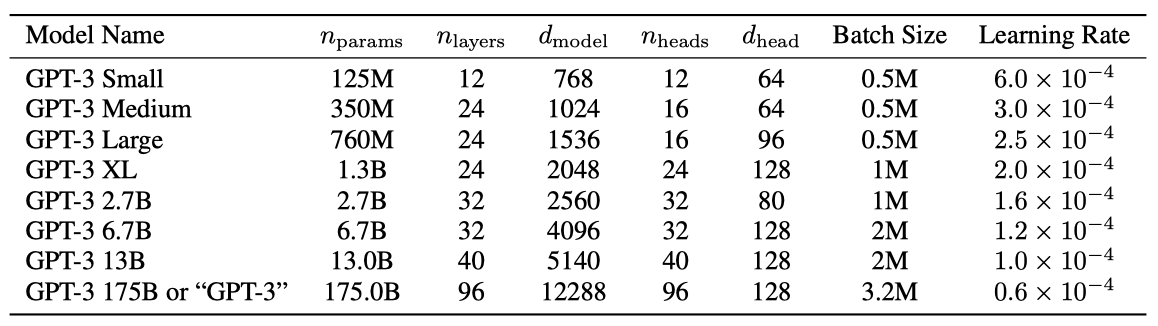
각 모델은 학습 가능한 parameter 수, layer 수, bottleneck layer의 단위 수 등으로 구성되어 있다. 모든 모델은 2048 토큰의 컨텍스트 window를 사용하며, 데이터 전송을 최소화하기 위해 GPU에 모델을 깊이와 너비 차원을 따라 분할한다. 각 모델의 아키텍처 parameter는 계산 효율성과 GPU 간의 로드 밸런싱에 기반하여 선택되었다. 이전 연구에 따르면, 검증 손실은 이러한 parameter에 대해 상당히 넓은 범위에서 크게 민감하지 않다.
Training Dataset
언어 모델 데이터셋은 Common Crawl 데이터셋으로 확장되어 1 trillion 단어를 수집하였다. 이런 크기의 데이터셋은 가장 큰 모델을 학습시키기에 충분하지만, Common Crawl의 필터링되지 않은 버전은 품질이 낮다. 그래서 데이터셋의 품질을 향상시키기 위해 세 가지 절차를 거쳤습니다: (1) 고품질 참조 말뭉치와 유사한 Common Crawl의 버전을 다운로드하고 필터링, (2) 중복 제거를 통해 데이터셋의 중복을 방지, (3) 고품질 참조 말뭉치를 학습 데이터에 추가하여 다양성을 늘렸다.
추가 데이터셋으로는 WebText 데이터셋의 확장 버전, 두 개의 인터넷 기반 책 말뭉치(Books1과 Books2), 그리고 영어 Wikipedia가 있다.
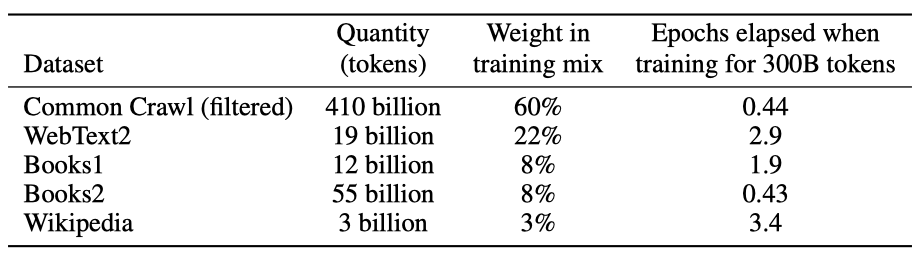
CommonCrawl 데이터는 필터링 전 45TB, 필터링 후 570GB로, 약 4000억 바이트 쌍 인코딩 토큰에 해당한다. 학습 중에는 품질이 높은 데이터셋을 더 자주 샘플링하며, 이는 고품질 학습 데이터를 위해 약간의 과적합을 받아들인다.
인터넷 데이터에서 사전 학습된 언어 모델은 데이터 오염이 발생할 우려가 있다. 이를 줄이기 위해 모든 벤치마크의 개발 및 테스트 세트와 겹치는 부분을 찾아 제거하려 했으나, 일부 겹치는 부분을 무시하는 버그가 있었다. 학습의 비용 문제로 인해 다시 모델을 학습하는 것은 비현실적이었다.
Training Process
대형 모델은 큰 배치 크기를 사용하나 작은 learning rate가 필요하다. 학습 중 gradient noise scale을 측정하여 배치 크기를 결정하였다. 메모리 부족을 방지하기 위해 모델 병렬성을 사용하였고, 모든 모델은 Microsoft의 고대역폭 클러스터에서 V100 GPU로 학습되었다.
Evaluation
few-shot 학습에서는 각 작업의 학습 세트에서 무작위로 $K$개의 예제를 추출하여 평가하였다. LAMBADA와 Storycloze는 지도 학습 세트가 없으므로, 개발 세트에서 추출한 예제를 사용한다. Winograd는 하나의 데이터셋만 있으므로, 그 데이터셋에서 직접 예제를 추출한다.
$K$는 0부터 모델의 컨텍스트 창이 허용하는 2048까지의 값이 될 수 있으며, 대체로 10에서 100개의 예제를 수용한다. $K$의 더 큰 값이 일반적으로 좋지만 항상 그런 것은 아니므로, 개발 세트와 테스트 세트가 있는 경우, 개발 세트에서 $K$의 몇 가지 값을 실험하고 최적의 값을 테스트 세트에서 사용한다. 일부 작업에서는 예시 외에도 자연어 프롬프트를 사용한다.
객관식 작업에서는 $K$개의 컨텍스트와 정확한 완성 예제를 제공하고, 각 완성의 가능성을 비교한다. 대부분 작업에서는 토큰 당 가능성을 비교하여 길이를 정규화하지만, ARC, OpenBookQA, RACE 같은 일부 데이터셋에서는 완성의 무조건적 확률 $ {P(completion | context)}\over{P(completion | answer_context)} $로 정규화하여 추가적인 이익을 얻는다. “Answer: " 또는 “A: “는 완성이 답이어야 함을 알리는 프롬프트로 사용된다.
이진 분류 작업에서는 옵션에 “True"나 “False"와 같은 의미 있는 이름을 부여하고, 객관식 문제처럼 처리한다.
자유형식 완성 작업에서는 beam width가 4이고 길이 패널티가 $\alpha = 0.6$인 beam search를 사용한다. 모델은 F1 유사도 점수, BLEU, 또는 정확한 일치를 기준으로 평가한다.
테스트 세트가 공개적으로 사용 가능한 경우, 모델 크기와 학습 설정별로 최종 결과를 보고한다. 테스트 세트가 비공개인 경우, 개발 세트 결과를 보고한다. 제출이 가능한 데이터셋(SuperGLUE, TriviaQA, PiQa)에 대해서는 테스트 서버에 결과를 제출하고, 그 외의 경우에는 개발 세트 결과를 보고한다.
Results
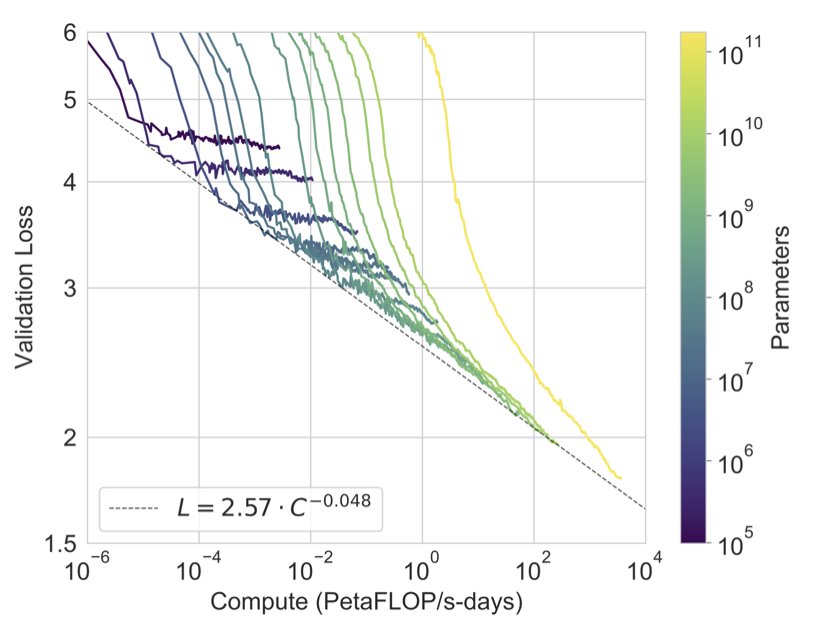
효율적인 학습 계산을 사용하면 언어 모델링 성능이 power-law를 따르는 것을 확인하였다. 이 경향을 더 확장하면 power-law에서 약간 벗어나는 것을 볼 수 있다. cross-entropy 손실의 개선이 학습 코퍼스의 특정 세부사항을 모델링함으로써만 이루어진다는 우려도 있지만, 실제로는 다양한 자연어 작업에서 일관된 성능 향상을 가져왔다.
8개의 모델(175B 개의 parameter를 가진 GPT-3와 7개의 작은 모델)을 다양한 데이터셋에서 평가한다. 데이터셋은 유사한 작업을 나타내는 9개의 카테고리로 그룹화한다.
언어 모델링과 유사한 작업, ‘closed book’ 질문 응답 작업, 언어 간 번역 능력, Winograd Schema와 유사한 작업, 상식 추론 또는 질문 응답 작업, 읽기 이해 작업, SuperGLUE 벤치마크를, 그리고 NLI를 평가한다. 마지막으로 인텍스트 학습 능력을 조사하기 위한 추가 작업을 발명하고 평가한다. 이 모든 평가는 few-shot, one-shot, zero-shot 설정에서 이루어진다.
Language Modeling, Cloze, and Completion Tasks
GPT-3의 성능을 전통적인 언어 모델링 작업뿐만 아니라 관심 있는 단일 단어를 예측하거나, 문장이나 단락을 완성하거나, 텍스트의 가능한 완성 사이에서 선택하는 등의 관련 작업을 테스트한다.
Language Modeling
Penn Tree Bank (PTB) 데이터셋에서 GPT-3의 zero-shot perplexity를 계산하였다. PTB는 현대 인터넷 이전에 만들어진 데이터셋이므로 학습 데이터에 포함되지 않았다. 가장 큰 모델은 PTB에서 perplexity 20.50을 달성하여 state-of-the-art를 달성하였다. PTB는 전행적인 언어 모델링 데이터셋이므로 one-shot이나 few-shot 평가는 적용되지 않았다.
LAMBADA
LAMBADA 데이터셋은 텍스트의 장거리 의존성을 테스트한다. 최근에는 언어 모델의 크기를 늘리는 것이 더 이상 벤치마크의 성능 향상에 별 도움이 안 된다는 의견이 있었다. 그러나 GPT-3는 zero-shot 설정에서 LAMBADA에서 76%의 결과를 보여주며, 이전 최고 기록보다 8% 향상시키는 결과를 보여주었다.
LAMBADA는 few-shot 학습의 유연성을 보여준다. 표준 언어 모델은 문장의 마지막 단어를 예측하는 것이 어렵지만, few-shot 학습은 이를 클로즈 테스트로 제시하고 언어 모델이 한 단어의 완성을 예측하도록 한다. 이전의 stop-word filter 방법보다 효과적인 해결책을 제공합니다.
다음과 같은 빈칸 채우기 형식을 사용한다:
$$ \text{Alice was friends with Bob. Alice went to visit her friend ____} \rightarrow \text{Bob} $$ $$ \text{George bought some baseball equipment, a ball, a glove, and a ____} \rightarrow $$
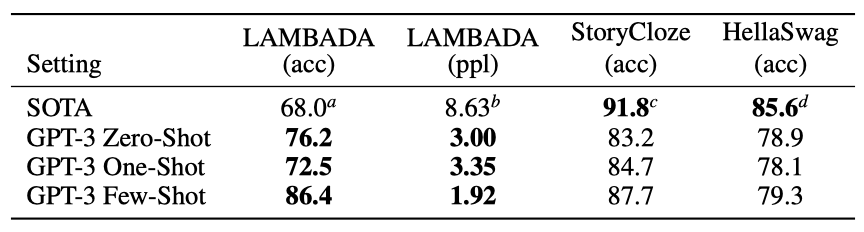
GPT-3는 few-shot 설정에서 86.4%의 정확도를 보여, 이전 최고 기록보다 18% 이상 증가하였다. 모델 크기가 커질수록 퓨샷 성능이 크게 향상되었다. 그러나 빈칸 채우기 방법은 one-shot에서는 zero-shot보다 성능이 떨어졌다. 이는 모든 모델이 패턴을 인식하기 위해 여러 예제가 필요하기 때문일 것으로 보인다.
테스트 세트에서 LAMBADA 데이터셋의 일부가 학습 데이터에 포함된 것으로 확인되었지만, 성능에 불필요한 영향을 미치지는 않는 것으로 분석되었다.
HellaSwag
HellaSwag 데이터셋은 이야기나 지시사항의 최선의 결말을 선택하는 것이다. GPT-3는 one-shot에서 78.1%, few-shot에서 79.3%의 정확도를 보여주었다. 이는 1.5B parameter 언어 모델의 75.4%를 능가하지만, 다목적 모델 ALUM의 85.6%에는 미치지 못하였다.
StoryCloze
GPT-3는 5문장 이야기의 결말을 선택하는 StoryCloze 2016 데이터셋에서는 zero-shot에서 83.2%, few-shot에서 87.7%의 정확도를 보여주었다. 이는 BERT 기반 모델의 최고 기록보다 4.1% 낮지만, 이전 zero-shot 결과에 비해 10% 향상된 수치이다.
Closed Book Question Answering
GPT-3가 광범위한 사실에 대한 질문에 얼마나 잘 대답하는지를 측정한다. 일반적으로 이 작업은 정보 검색 시스템과 모델을 사용해 수행되며, 이를 “open-book"이라고 부른다. 하지만 최근에는 “closed-book” 방식으로 큰 언어 모델이 직접 질문에 답하는 것이 효과적이라는 연구 결과가 나왔다. 이 가설을 GPT-3로 테스트하며, Natural Questions, WebQuestions, TriviaQA 세가지 데이터셋에서 평가를 진행하였다. 이 평가는 외부 콘텐츠와 Q&A 데이터셋에 대한 미세조정을 허용하지 않는 엄격한 closed-book 설정에서 수행된다.
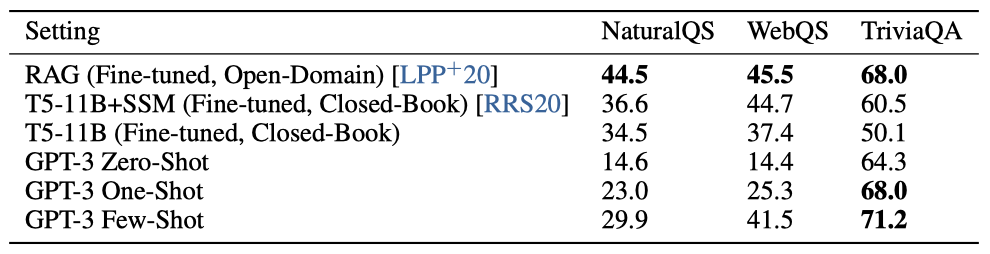
GPT-3는 TriviaQA에서 zero-shot 64.3%, one-shot 68.0%, few-shot 71.2%의 결과를 보여주었다. zero-shot 결과만으로도 미세조정된 T5-11B를 14.2%, Q&A 맞춤형 범위 예측을 사용한 버전을 3.8% 초과하였다. one-shot 결과는 3.7% 향상되며, 오픈 도메인 QA 시스템의 최고 기록과 동일하게 되었다. few-shot 결과는 3.2% 향상시켰다.
WebQuestions에서 GPT-3는 zero-shot 14.4%, one-shot 25.3%, few-shot 41.5%의 결과를 보여주었다. 이는 미세조정된 T5-11B의 37.4%, 특정 사전 학습 절차를 사용하는 T5-11B+SSM의 44.7%와 비교된다. few-shot 설정에서 GPT-3의 성능은 state-of-the-art를 달성한 미세조정 모델과 근접하다. 또한, WebQs의 질문이나 답변 스타일이 GPT-3에게는 이질적인 것으로 보여지지만, few-shot 설정에서 GPT-3는 이에 적응하며 높은 성능을 회복하는 것으로 보인다.
Natural Questions에서 GPT-3는 zero-shot 14.6%, one-shot 23.0%, few-shot 29.9%의 성과를 보여주었다. 이는 미세조정된 T5 11B+SSM의 36.6%와 비교되는 결과이다. zero-shot에서 few-shot으로 크게 향상된 성능은 분포의 변화를 보여주며, 이는 TriviaQA와 WebQS에 비해 덜 경쟁력 있는 성능을 설명할 수 있다. 특히, NQs 질문들이 Wikipedia에 대한 매우 세부적인 지식을 요구하므로, 이는 GPT-3의 용량과 사전 학습 분포의 한계를 시험할 수 있다.
세 가지 데이터셋 중 하나에서 GPT-3의 one-shot 성능은 오픈 도메인의 최고 성능과 일치하고, 나머지 두 데이터셋에서는 미세조정을 하지 않아도 최고 성능에 근접한다. 모든 데이터셋에서, 모델 크기에 따라 성능이 부드럽게 확장되는 것을 확인하였고, 이는 모델의 용량이 직접적으로 모델의 parameter 흡수된 ‘knowledge’으로 변환된다는 생각을 반영할 수 있다.
Translation
GPT-2는 용량 문제로 인해 다국어 문서를 영어로만 필터링했지만, 일부 다국어 능력을 보여주었다. 프랑스어와 영어 간 번역에서도 의미 있는 성과를 보였다. GPT-3에서는 용량을 크게 향상시키고 학습 데이터셋을 확대하여 다른 언어를 더 많이 포함하였다. GPT-3의 학습 데이터는 주로 영어(93%)이지만, 다른 언어의 텍스트도 7% 포함한다. 번역 능력을 더 잘 이해하기 위해, 분석에 독일어와 루마니아어를 추가하였다.
기존의 비지도 학습 기계 번역은 주로 단일 언어 데이터셋과 back-translation을 사용하지만, GPT-3는 여러 언어를 혼합한 학습 데이터에서 학습한다. 이는 단어, 문장, 문서 수준에서 언어들을 결합한다. GPT-3는 특정 작업을 위해 맞춤화되지 않은 단일 학습 목표를 사용한다. 그러나, one-shot / few-shot 설정은 적은 양의 쌍으로 된 예시를 사용하기 때문에 엄밀히 말해 이전의 비지도 작업과는 비교가 어렵다.
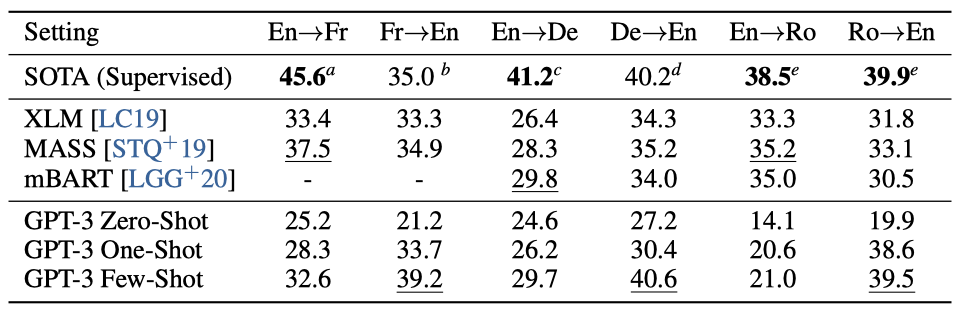
zero-shot GPT-3는 작업 설명만을 받지만 최근의 비지도 NMT 결과보다 성능이 떨어진다. 그러나 각 번역 작업에 대해 한 예시만 제공하면 성능이 크게 향상되며, few-shot 설정에서 더욱 향상된다. GPT-3의 성능은 언어 방향에 따라 크게 달라진다. 영어로 번역할 때는 이전의 비지도 NMT 작업을 능가하지만 반대 방향으로는 성능이 떨어진다. En-Ro의 경우 성능이 이전 비지도 NMT 작업보다 훨씬 낮다. Fr-En과 De-En에서 few-shot GPT-3는 최고의 지도 학습 결과를 능가하고, Ro-En에서는 전체 최고 성능과 비슷한 성능을 보여준다.
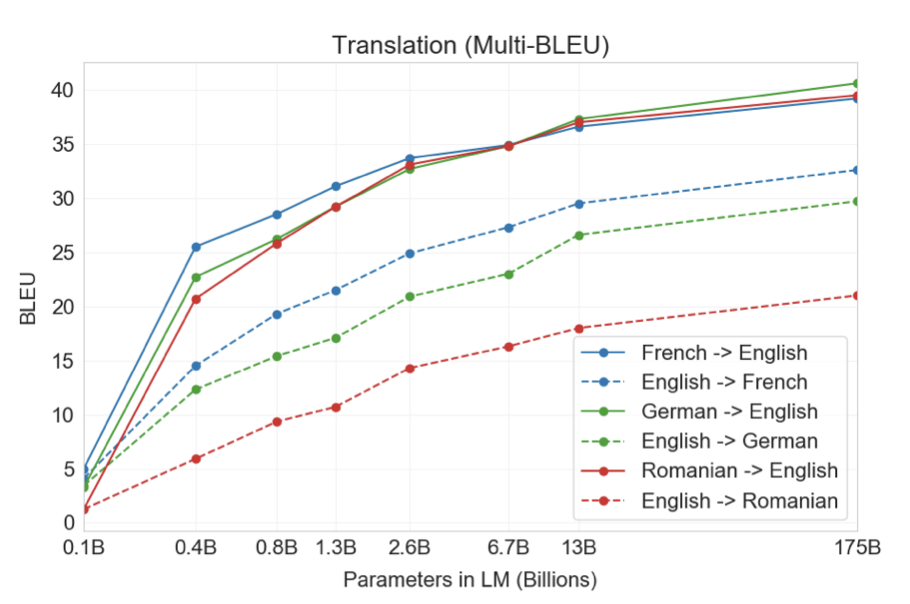
모든 언어 쌍과 zero-shot, one-shot, few-shot 설정에서 모델 용량이 증가함에 따라 성능이 부드럽게 향상되는 추세가 확인되었다.
Winograd-Style Tasks
Winograd Schemas Challenge는 대명사가 가리키는 단어를 찾는 NLP 작업이다. 언어 모델은 기존 Winograd 데이터셋에서는 좋은 성능을 보였지만, 더 어려운 Winogrande 데이터셋에서는 성능이 떨어졌다. 이는 GPT-3에서도 확인되었다.
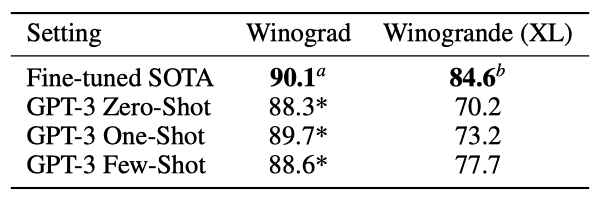
GPT-3는 원래의 273개의 Winograd 스키마에서 테스트되었고, zero-shot, one-shot, few-shot 설정에서 각각 88.3%, 89.7%, 88.6%의 성능을 보여주었다. 이는 모든 경우에서 state-of-the-art와 인간의 성능을 몇 포인트 밑돌게 강력한 결과를 보여준다. 학습 데이터 중 일부 Winograd 스키마에서 오염 분석이 이루어졌지만, 이것이 결과에 미치는 영향은 작았다.
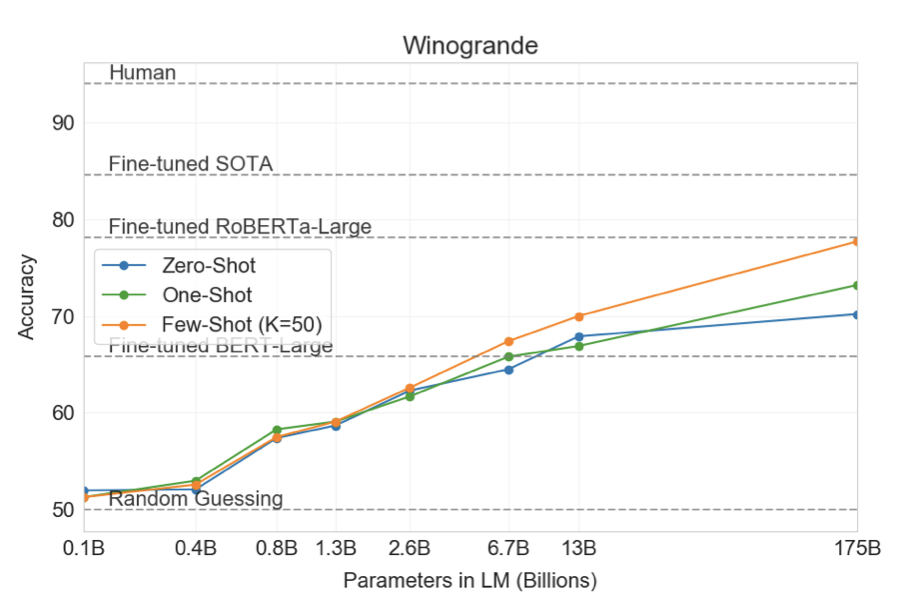
더 어려운 Winogrande 데이터셋에서 GPT-3는 zero-shot에서 70.2%, one-shot에서 73.2%, few-shot에서 77.7%의 성능을 보여주었다. 이는 미세 조정된 RoBERTA 모델의 79%, 최첨단 모델인 T5의 84.6%, 그리고 인간의 성능인 94.0%와 비교된다.
Common Sense Reasoning
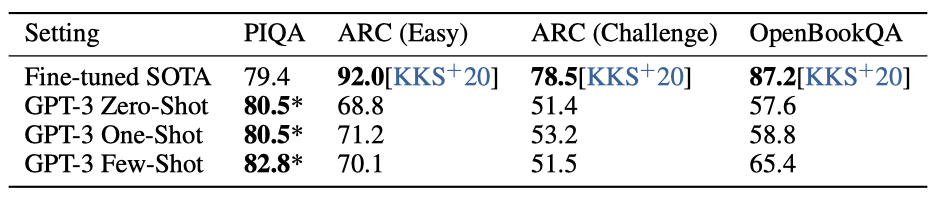
PhysicalQA (PIQA)라는 데이터셋에서 GPT-3는 zero-shot 81.0%, one-shot 80.5%, few-shot 82.8%의 정확도를 달성하였다. 이는 미세 조정된 RoBERTa의 79.4%에 비해 우수하며, 인간의 성능보다는 약 10% 떨어지지만, state-of-the-art의 성능을 one-shot과 few-shot에서 능가하였다. 하지만, PIQA가 데이터 오염 가능성을 가질 수 있어 결과를 보수적으로 표시하였다.
ARC 데이터셋에서 GPT-3는 “Challenge” 버전에서 zero-shot 51.4%, one-shot 53.2%, few-shot 51.5%의 정확도를, “Easy” 버전에서는 68.8%, 71.2%, 70.1%의 정확도를 달성하였다. 이는 미세 조정된 RoBERTa의 성능에 근접하거나 약간 능가하였지만, UnifiedQA의 성능에 비하면 아직도 많이 뒤떨어져 있다.
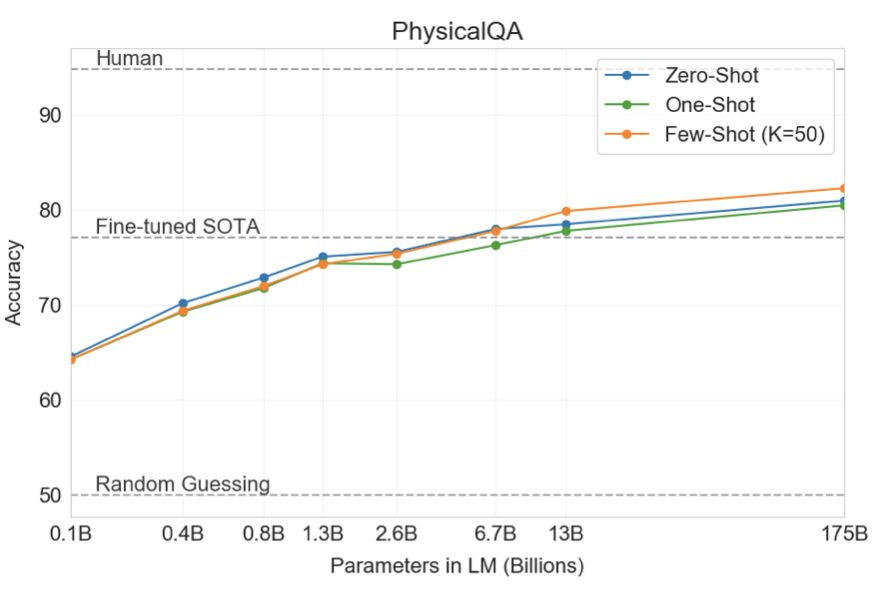
OpenBookQA에서 GPT-3는 zero-shot에서 few-shot으로 넘어갈 때 성능이 크게 향상되었지만, state-of-the-art에 비해 아직 20점 이상 뒤떨어져 있다. GPT-3의 few-shot 성능은 미세 조정된 BERT Large와 비슷하다.
GPT-3의 in-context 학습은 상식 추론 작업에서 일관성 없는 결과를 보였지만, OpenBookQA에서는 크게 향상되었다. 또한, GPT-3는 모든 평가에서 새 PIQA 데이터셋의 state-of-the-art를 달성하였다.
Reading Comprehension
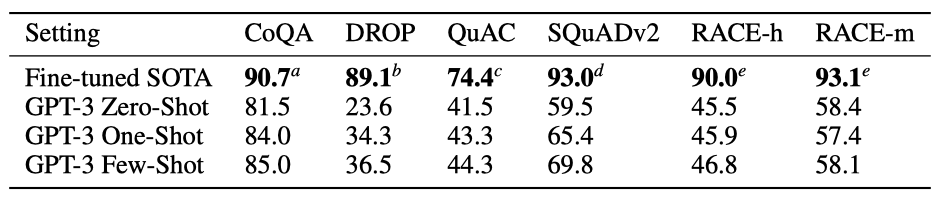
reading comprehension 작업에서 GPT-3를 평가해 보았다. 다양한 답변 형식을 가진 5개의 데이터셋을 사용하였고, GPT-3의 성능은 데이터셋에 따라 크게 다르며, 다양한 답변 형식에 대한 능력을 보여주었다. 일반적으로 GPT-3는 각 데이터셋에 대한 초기 기준선과 비슷한 성능을 보여주었다.
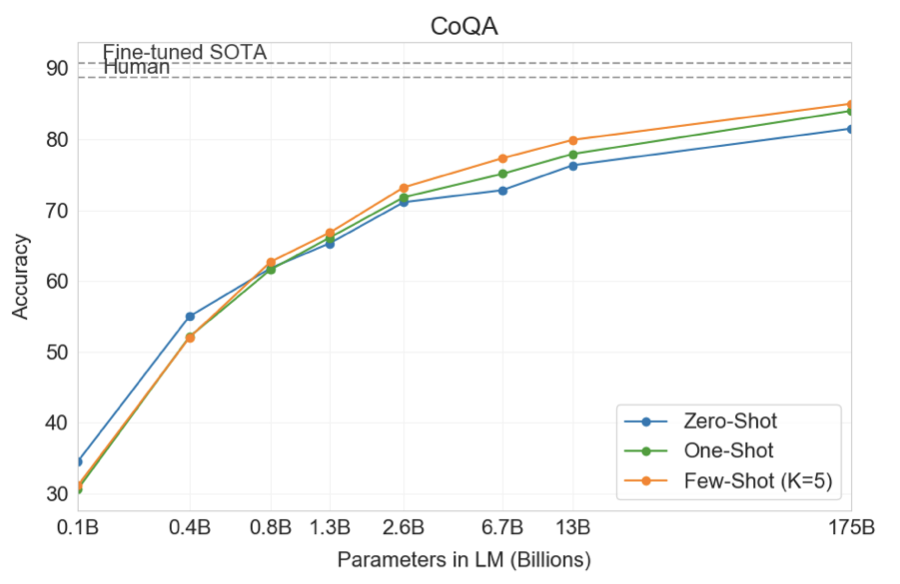
GPT-3는 자유 형식의 대화 데이터셋인 CoQA에서 가장 좋은 성능을 보였고, 대화 행동과 답변 선택을 요구하는 QuAC에서는 가장 나쁜 성능을 보였다. DROP 데이터셋에서는 few-shot 설정에서 BERT 기준선을 앞섰지만, 사람의 성능과 최첨단 방법에는 미치지 못하였다. SQuAD 2.0에서는 few-shot 학습 능력을 보여주며 성능을 향상시켰고, RACE에서는 상대적으로 약한 성능을 보였지만, 초기 작업과는 경쟁력을 가졌다.
SuperGLUE
GPT-3를 더 체계적으로 평가하고 다른 모델들과 비교하기 위해, SuperGLUE 벤치마크라는 표준화된 데이터셋에서도 평가를 진행하였다. few-shot 설정에서는 모든 작업에 대해 학습 세트에서 무작위로 추출한 32개의 예제를 사용하였다. WSC와 MultiRC를 제외한 모든 작업에서는 각 문제의 컨텍스트로 사용할 새로운 예제 집합을 샘플링하였다. WSC와 MultiRC에서는, 모든 문제의 컨텍스트로 동일한 예제 집합을 사용하였다.
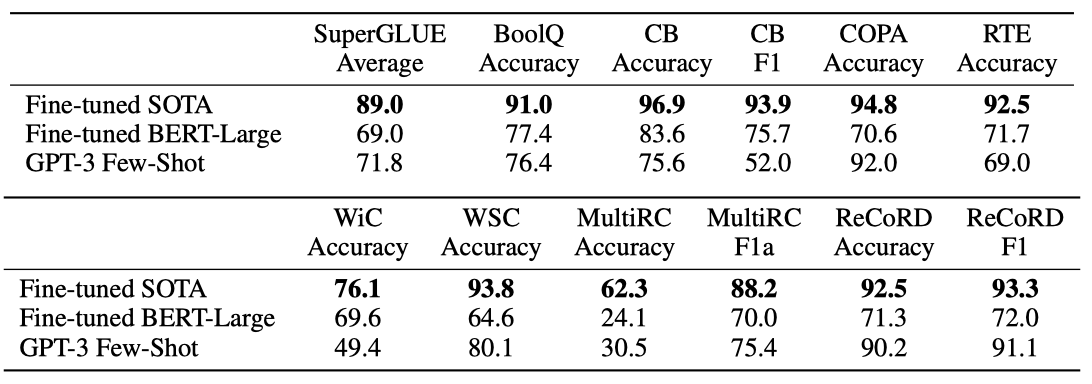
GPT-3는 다양한 작업에서 성능이 다르게 나타났다. COPA와 ReCoRD에서는 거의 최고 수준에 근접한 성능을 보였고, WSC에서는 80.1%의 높은 성능을 보였다. BoolQ, MultiRC, RTE에서는 합리적인 성능을 보였고, CB에서는 75.6%의 성능을 보였다.
WiC에서 GPT-3의 few-shot 성능이 49.4%로 상대적으로 약하다는 것을 발견하였다. 두 문장을 비교하는 일부 작업에서 GPT-3는 약한 경향이 있다. 이는 RTE와 CB의 낮은 점수를 설명할 수 있다. 그러나 이런 약점에도 불구하고, GPT-3는 8개 작업 중 4개에서 미세 조정된 BERT-Large를 능가하며, 2개 작업에서는 state-of-the-art에 가깝다.
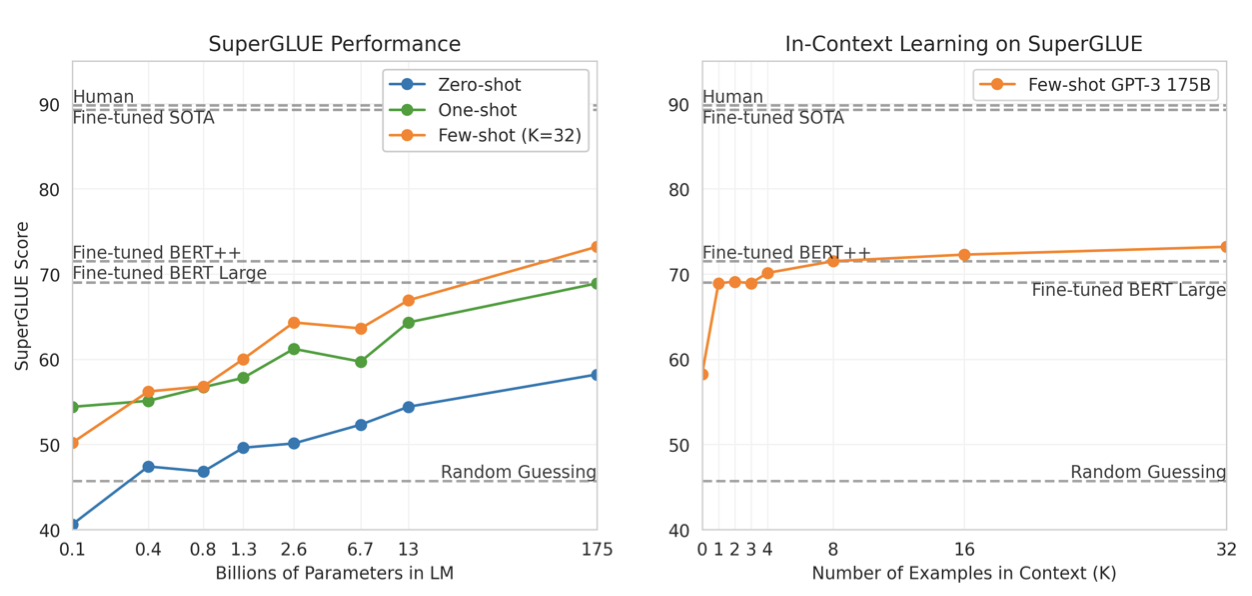
모델 크기와 예시 수가 증가함에 따라 few-shot SuperGLUE 점수가 개선되는 것을 확인하였다. GPT-3는 각 작업당 8개 미만의 예시만으로도 미세 조정된 BERT-Large를 능가하는 전체 SuperGLUE 점수를 얻을 수 있었다.
NLI
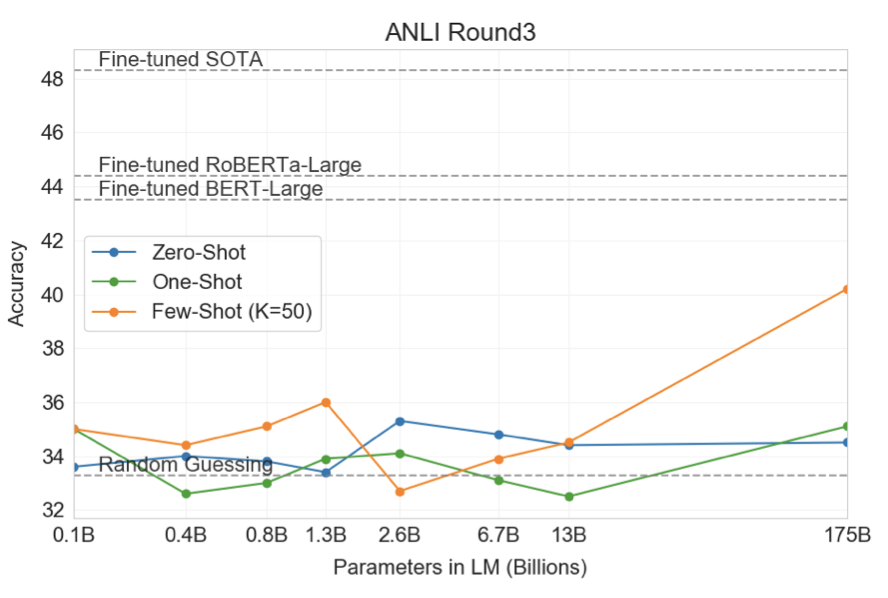
자연어 추론(NLI)은 두 문장 간의 관계를 이해하는 능력을 평가한다. GPT-3는 이 작업에서 랜덤(56%)보다 약간 더 잘 수행되는 반면, few-shot 설정에서는 BERT Large와 유사한 수준으로 수행한다. 적대적 자연어 추론(ANLI) 데이터셋에서는 GPT-3가 라운드 3에서 약간의 진전을 보여주었다. 이러한 결과는 NLI가 여전히 언어 모델에게 어려운 작업이며, 진전의 시작 단계에 불과하다는 것을 시사한다.
Synthetic and Qualitative Tasks
GPT-3의 능력을 테스트하기 위해, 간단한 계산, 새로운 패턴 인식, 비정상적인 작업에 빠르게 적응하는 등의 작업을 제공한다. 테스트에는 산술, 단어의 글자 재배열, SAT 스타일의 유사성 문제 해결, 그리고 새로운 단어 사용, 문법 수정, 뉴스 기사 생성 등이 포함된다. 이러한 합성 데이터셋은 언어 모델의 테스트 시간 행동에 대한 추가 연구를 촉진하기 위해 공개될 예정이다.
Arithmetic
GPT-3가 특정 작업에 대한 학습 없이 간단한 산술 연산을 수행하는 능력을 테스트하기 위해, 자연어로 간단한 산술 문제를 묻는 10개의 작은 테스트를 개발하였다:
- 2 digit addition (2D+) 모델에게는 두 정수를 더하라는 질문이 제시된다. 이 정수들은 [0, 100) 범위에서 균일하게 샘플링되며, 예를 들어 “Q: What is 48 plus 76? A: 124"와 같은 형태로 질문된다.
- 2 digit subtraction (2D-) 모델에게는 두 정수를 빼라는 질문이 제시된다. 이 정수들은 [0, 100) 범위에서 균일하게 샘플링되며, 답변은 음수일 수 있다. 예를 들어 “Q: What is 34 minus 53? A: -19"와 같은 형태로 질문된다.
- 3 digit addition (3D+) 2자리 수 덧셈과 같지만, 숫자는 [0, 1000) 범위에서 균일하게 샘플링된다.
- 3 digit subtraction (3D-) 2자리 수 뺄셈과 같지만, 숫자는 [0, 1000) 범위에서 균일하게 샘플링된다.
- 4 digit addition (4D+) 3자리 수 덧셈과 같지만, 숫자는 [0, 10000) 범위에서 균일하게 샘플링된다.
- 4 digit subtraction (4D-) 3자리 수 뺄셈과 같지만, 숫자는 [0, 10000) 범위에서 균일하게 샘플링된다.
- 5 digit addition (5D+) 4자리 수 덧셈과 같지만, 숫자는 [0, 100000) 범위에서 균일하게 샘플링된다.
- 5 digit subtraction (5D-) 4자리 수 뺄셈과 같지만, 숫자는 [0, 100000) 범위에서 균일하게 샘플링된다.
- 2 digit multiplication (2Dx) 모델에게는 두 정수를 곱하라는 질문이 제시된다. 이 정수들은 [0, 100) 범위에서 균일하게 샘플링되며, 예를 들어 “Q: What is 24 times 42? A: 1008"와 같은 형태로 질문된ㄴ다.
- One-digit composite (1DC) 모델에게는 마지막 두 숫자에 괄호가 있는 세 개의 1자리 숫자에 대해 복합 연산을 수행하라는 질문이 제시된다. 예를 들어, “Q: What is 6+(4*8)? A: 38"입니다. 세 개의 1자리 숫자는 [0, 10) 범위에서 균일하게 선택되며, 연산은 { +, -, * } 중에서 균일하게 선택된다.
10개의 모든 작업에서 모델은 정확한 답변을 생성해야 한다. 각 작업에 대해 작업의 2,000개의 무작위 인스턴스 데이터셋을 생성하고, 모든 모델을 이러한 인스턴스에서 평가한다.

GPT-3는 few-shot 설정에서 평가되었고, 작은 숫자에 대한 덧셈과 뺄셈에서 높은 정확도를 보여주었다. 2자리 숫자에 대한 연산에서는 덧셈에서 100%, 뺄셈에서 98.9%의 정확도를 보였으며, 3자리 숫자에 대한 연산에서는 덧셈에서 80.2%, 뺄셈에서 94.2%의 정확도를 달성하였다. 숫자의 자릿수가 증가함에 따라 성능은 감소하지만, 4자리 연산에서는 25-26%, 5자리 연산에서는 9-10%의 정확도를 보여주었다. GPT-3는 또한 계산이 복잡한 2자리 곱셈에서 29.2%의 정확도를 달성하였다. 마지막으로, GPT-3는 단일 자릿수 복합 연산(예를 들어, 9*(7+5))에서 21.3%의 정확도를 보였습니다. 이는 GPT-3가 단일 연산을 넘어서 일부 견고성을 가지고 있다는 것을 나타낸다.
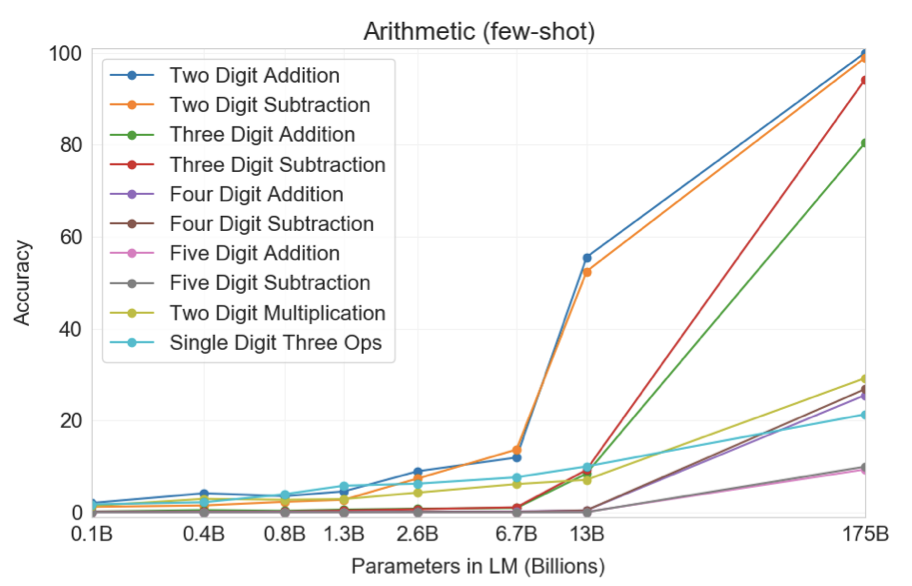
작은 모델들은 이러한 모든 작업에서 성능이 좋지 않다 - 심지어 13B parameter 모델(175B parameter 전체 GPT-3 다음으로 큰 모델)조차도 2자리 덧셈과 뺄셈을 절반 정도의 시간만 해결할 수 있고, 다른 모든 연산은 10% 미만의 시간에 해결할 수 있다.
one-shot과 zero-shot 성능은 few-shot 성능에 비해 다소 낮지만, 이는 작업에 대한 적응이 중요함을 보여준다. 그러나 one-shot 성능은 아직도 강하며, 전체 GPT-3의 zero-shot 성능은 더 작은 모델들의 few-shot 학습보다 월등히 뛰어나다.
모델이 단순히 특정 산술 문제를 기억하는 것인지를 확인하기 위해, 테스트 세트의 3자리 산술 문제를 가져와서 “ + =“와 “ plus ” 형태로 학습 데이터에서 찾아보았다. 2,000개의 덧셈 문제 중에서는 17개(0.8%)만 일치하였고, 2,000개의 뺄셈 문제 중에서는 2개(0.1%)만 일치하였다. 이는 올바른 답변의 일부분만이 기억되었을 수 있다는 것을 시사한다. 또한, 잘못된 답변의 검사는 모델이 “1"을 올리지 않는 등의 오류를 종종 범하는 것으로 나타낸다. 이는 모델이 실제로 표를 기억하는 것이 아니라 관련 계산을 수행하려고 시도하고 있다는 것을 시사한다.
전반적으로 GPT-3는 few-shot, one-shot, 심지어 zero-shot 설정에서도 복잡한 산술에 대해 합리적인 능숙도를 보여준다.
Word Scrambling and Manipulation Tasks
GPT-3의 새로운 기호 조작 학습 능력을 테스트하기 위해, 문자를 섞거나 추가하거나 삭제하여 왜곡된 단어를 복구하는 5가지 ‘character manipulation’ 작업을 설계하였다:
- Cycle letters in word (CL) 모델에게 문자가 순환된 단어와 “=” 심볼이 주어지면, 원래의 단어를 생성해야 한다. 예를 들어, “lyinevitab"이 주어지면 “inevitably"를 출력해야 한다.
- Anagrams of all but first and last characters (A1) 모델에게 첫 번째와 마지막 문자를 제외한 모든 문자가 무작위로 섞인 단어가 주어지면, 원래의 단어를 출력해야 한다. 예를 들어, “criroptuon"이 주어지면 “corruption"을 출력해야 한다.
- Anagrams of all but first and last 2 characters (A2) 모델에게 첫 두 글자와 마지막 두 글자를 제외한 모든 글자가 무작위로 섞인 단어가 주어지면, 원래의 단어를 복구해야 한다. 예를 들어, “opoepnnt"가 주어지면 “opponent"를 출력해야 한다.
- Random insertion in word (RI) 모델에게 단어의 각 글자 사이에 무작위의 구두점이나 공백 문자가 삽입된ㄴ 글자가 주어지면, 원래의 단어를 출력해야 한다. 예를 들어, “s.u!c/c!e.s s i/o/n"이 주어지면 “succession"을 출력해야 한다.
- Reversed words (RW) 모델에게 거꾸로 철자된 단어가 주어지면, 원래의 단어를 출력해야 한다. 예를 들어, “stcejbo"가 주어지면 “objects"를 출력해야 한다.
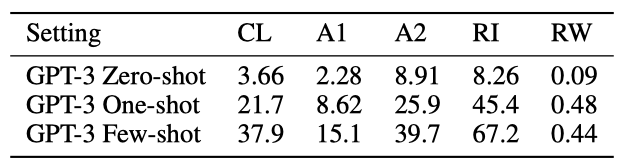
각 작업에 대해 가장 빈번한 10,000개의 단어를 사용하여 10,000개의 예시를 생성하였다. few-shot 결과는 모델 크기가 커질수록 성능이 부드럽게 증가하는 경향을 보여주었다. 전체 GPT-3 모델은 RI 38.6%, A1 40.2%, A2 15.1%를 달성하였다. 그러나 어느 모델도 RW는 불가능하였다.
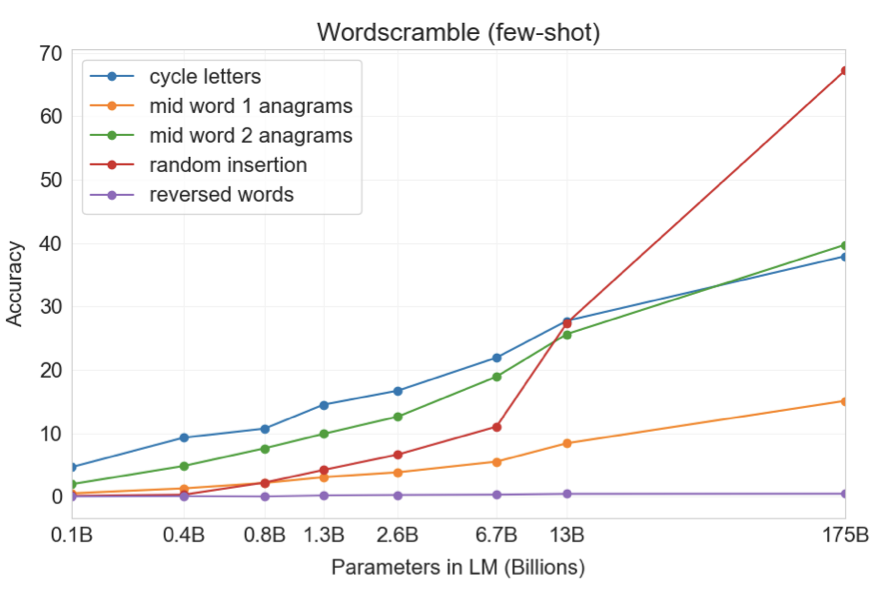
one-shot 설정에서는 성능이 크게 약해져서 절반 이상 떨어지고, zero-shot 설정에서는 대부분의 작업을 수행하지 못하였다. 이는 모델이 테스트 단계에서 이러한 작업을 실제로 배우는 것을 나타내며, 이러한 작업들이 사전 학습 데이터에는 거의 나타나지 않기 때문에 zero-shot으로 수행하는 것이 어렵다.
“in-context learning curves"을 통해 성능을 정량적으로 측정할 수 있다. 이는 in-context 예시의 수에 따른 작업 성능을 나타낸다. 큰 모델일수록 in-context 정보를 더 효과적으로 활용할 수 있음을 알 수 있다. 이는 작업 예시와 자연 언어 작업 설명 모두를 포함한다.
이러한 작업을 해결하려면 문자 수준의 조작이 필요하며, BPE 인코딩은 단어의 큰 부분을 조작한다. 따라서, 이 작업에 성공하려면 BPE 토큰을 조작하는 것뿐만 아니라 그들의 하위 구조를 이해하고 분해해야 한다. 또한, CL, A1, A2는 bijective가 아니므로, 모델이 올바른 암호화 해제를 찾기 위해 검색을 수행해야 한다. 이러한 기술은 복잡한 패턴 매칭과 계산이 필요하다.
SAT Analogies
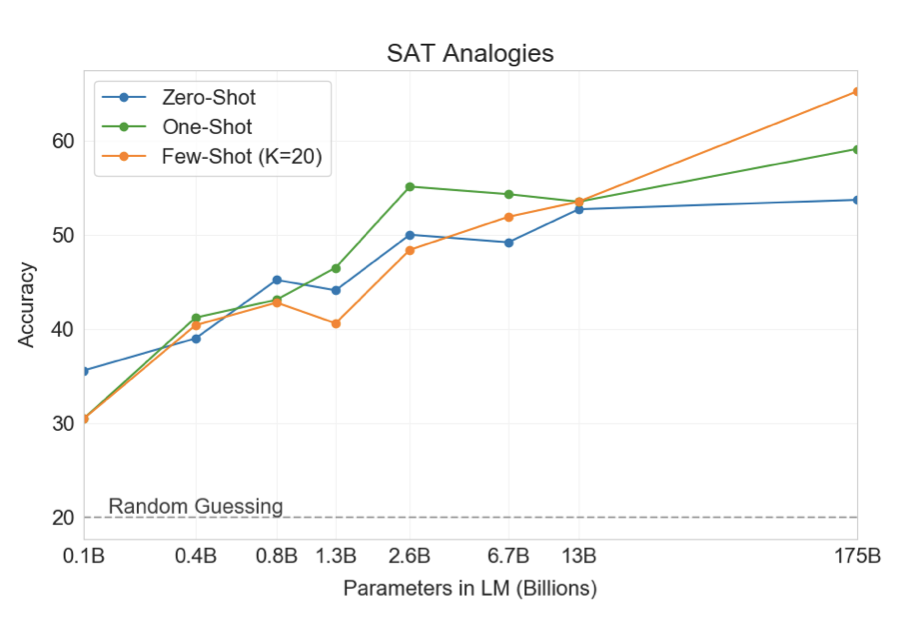
GPT-3는 374개의 “SAT analogy” 문제를 통해 테스트되었다. 이 작업에서 GPT-3는 few-shot 65.2%, one-shot 59.1%, zero-shot 53.7%의 성능을 보여주었다. 이는 대학 지원자들의 평균 57%보다 높다. 결과는 규모에 따라 개선되며, 1750억 모델은 130억 파라미터 모델에 비해 10% 이상 개선되었다.
News Article Generation
GPT-3는 “news articles"를 생성하는 능력을 테스트하였다. 그러나 GPT-3의 학습 데이터는 뉴스 기사에 비중이 덜 두어져 있어, 뉴스 기사를 생성하는 것이 덜 효과적이었다. 이를 해결하기 위해, GPT-3의 few-shot 학습 능력을 활용해 세 개의 이전 뉴스 기사를 제공하여 모델을 조건화하였다. 그 결과, 제안된 다음 기사의 제목과 부제목을 가지고, 모델은 “news” 장르의 짧은 기사를 신뢰성 있게 생성할 수 있었다.
GPT-3가 생성한 뉴스 기사의 품질을 평가하기 위해, 사람들이 GPT-3가 생성한 기사와 실제 기사를 구별하는 능력을 측정하기로 결정하였다. 이는 생성적 언어 모델의 품질을 측정하는 중요한 방법으로, 이전에도 비슷한 연구가 있었다.
사람들이 모델이 생성한 텍스트를 얼마나 잘 감지하는지 확인하기 위해, newser.com에서 기사 제목과 부제목 25개를 선택하고, 다양한 크기의 언어 모델로 이를 완성하였다. 이후 미국 참가자 80명에게 이 기사들을 제시하고, 각 참가자에게 기사가 사람이 작성했는지 아니면 기계가 작성했는지 판단하도록 요청하였다.
모델의 훈련 데이터에는 없는 기사들을 선택하였고, 모든 모델은 같은 맥락을 사용하여 훈련되었다. 각 모델에게는 같은 기사 제목과 부제목이 프롬프트로 제공되었다. 추가적으로 참가자의 집중력을 통제하기 위한 실험도 진행했는데, 이는 고의적으로 품질이 낮은 기사를 생성한 “control model"을 사용했습니다.
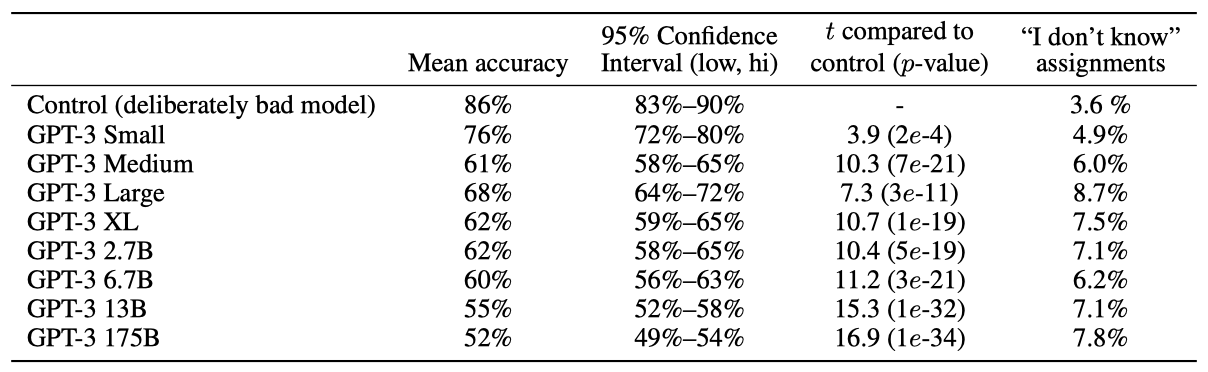
고의적으로 품질이 낮은 기사를 모델이 만들었다고 판별하는 평균 인간 정확도는 약 86%였다. 반면, 175B parameter 모델이 생성한 기사를 감지하는 평균 인간 정확도는 우연 수준인 52%에 불과하였다. 모델 크기가 커질수록 인간이 모델이 생성한 텍스트를 감지하는 능력이 줄어드는 것으로 보인다.
GPT-3가 생성한 합성 기사의 예시는 대부분 인간이 진짜 내용과 구별하기 어렵다. 하지만 사실적인 오류는 기사가 모델이 생성했음을 나타낼 수 있다. 왜냐하면 모델은 인간 작가와 달리 특정 사실에 대한 접근이 없기 때문이다. 또한 반복, 비연속성, 이상한 표현도 모델이 생성한 텍스트의 지표가 될 수 있다.
인간은 더 많은 토큰을 관찰할수록 모델이 생성한 텍스트를 더 잘 감지한다. 이를 검증하기 위해, 평균 길이가 569단어인 로이터의 12개 세계 뉴스 기사에 대해 GPT-3가 평균 498단어로 생성한 기사를 사용하여 실험을 진행하였다. 약 80명의 미국 참가자를 대상으로 한 두 가지 실험을 통해 GPT-3와 통제 모델이 생성한 기사를 감지하는 인간의 능력을 비교하였다.

통제 모델로부터 나온 고의적으로 나쁜 긴 기사를 감지하는 인간의 평균 정확도는 약 88%였다. 반면에, GPT-3가 생성한 긴 기사를 인식하는 인간의 평균 정확도는 약 52%로 거의 우연에 가까웠다. 이는 GPT-3가 약 500단어의 뉴스 기사를 생성할 때, 인간이 쓴 것과 구별하기 어렵다는 것을 의미한다.
Learning and Using Novel Words
새로운 단어를 배우고 활용하는 능력을 GPT-3로 테스트해 보았다. 존재하지 않는 단어 ‘Gigamuru’ 같은 단어의 정의를 제공하고, 그 단어를 문장에서 사용하도록 요청하였다. 결과적으로, GPT-3는 새로운 단어를 문장에서 사용하는 작업에 대해 능숙함을 보였다. 심지어 “screeg"이라는 단어에 대해 그럴등한 변형(“screeghed”)을 생성하며, 이 단어를 약간 어색하게 사용하였지만 장난감 칼 싸움을 묘사하는 가능성을 보여주었다.
Correcting English Grammar
영어 문법 교정은 few-shot 학습에 아주 적합한 작업이다. GPT-3를 이용해 이를 테스트하였다. 이를 위해 “Poor English Input: \ n Good English Output: ” 형식의 문장을 주고, 한 가지 인간이 생성한 교정 예를 제공한 후, 다른 5개 문장의 교정을 요청했습니다.
Measuring and Preventing Memorization Of Benchmarks
학습 데이터셋은 인터넷에서 가져왔기 때문에, 벤치마크 테스트 세트가 학습 데이터에 포함된 것일 수 있다. 이런 테스트 오염을 정확히 파악하는 것은 아직 확립된 방법이 없는 새로운 연구 분야이다. 대규모 모델 학습 시 오염을 조사하지 않는 것이 일반적이지만, 사전 학습 데이터셋의 규모가 커지고 있어 이 문제에 점점 더 주목할 필요가 있다고 생각한다.
학습 데이터와 평가 데이터셋이 겹치는 문제는 실제로 존재한다. Common Crawl 데이터에 기반한 언어 모델을 처음 학습시킨 연구 중 하나에서는 평가 데이터셋과 겹치는 학습 문서를 감지하고 제거하였다. GPT-2와 같은 다른 연구에서도 이러한 중복을 분석하였고, 결과적으로 학습과 테스트 데이터가 겹치는 경우 모델 성능이 약간 향상되었지만, 겹치는 데이터의 비율이 작아 전체 결과에는 크게 영향을 미치지 않았다.
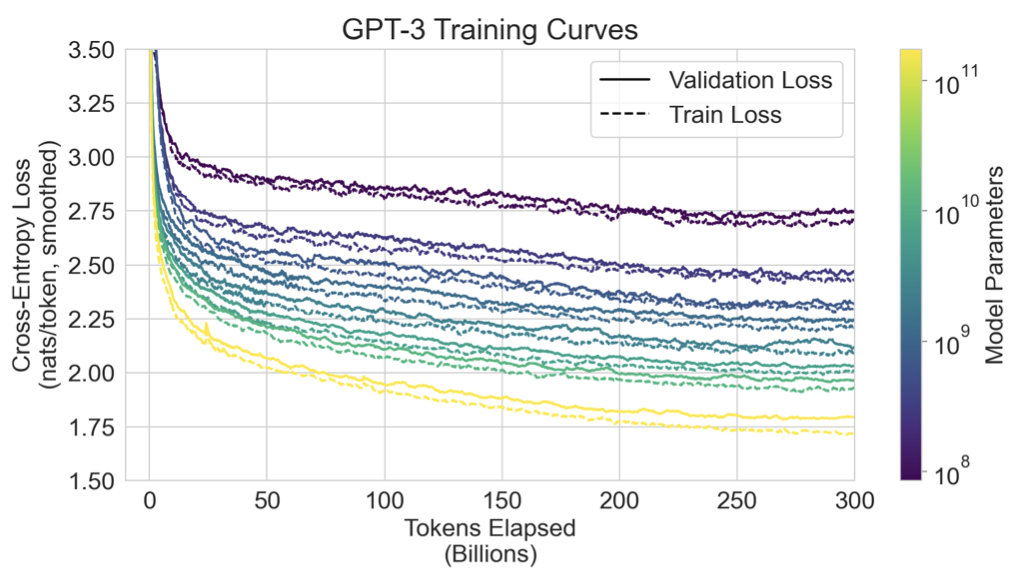
GPT-3는 데이터셋과 모델 크기가 GPT-2보다 훨씬 크며, 대량의 Common Crawl 데이터를 포함하고 있어 오염 가능성이 늘어났다. 그러나, 데이터량이 많아 GPT-3 175B는 중복 제거된 검증 세트에 대해 크게 과적합되지 않았다. 따라서, 오염은 자주 발생할 것으로 보이지만 그 효과는 예상만큼 크지 않을 것으로 보인다.
학습 데이터와 벤치마크의 개발 및 테스트 세트 간 중복을 찾아 제거하려 하였으나, 버그로 인해 감지된 중복이 일부만 제거되었다. 모델을 재학습하는 것은 비용 문제로 불가능했다. 그래서 남은 중복이 결과에 미치는 영향을 자세히 조사하였다.
각 벤치마크에 대해, 13-gram 중복이 있는 예시를 제거하여 오염이 없는 “clean” 버전을 만들었다.
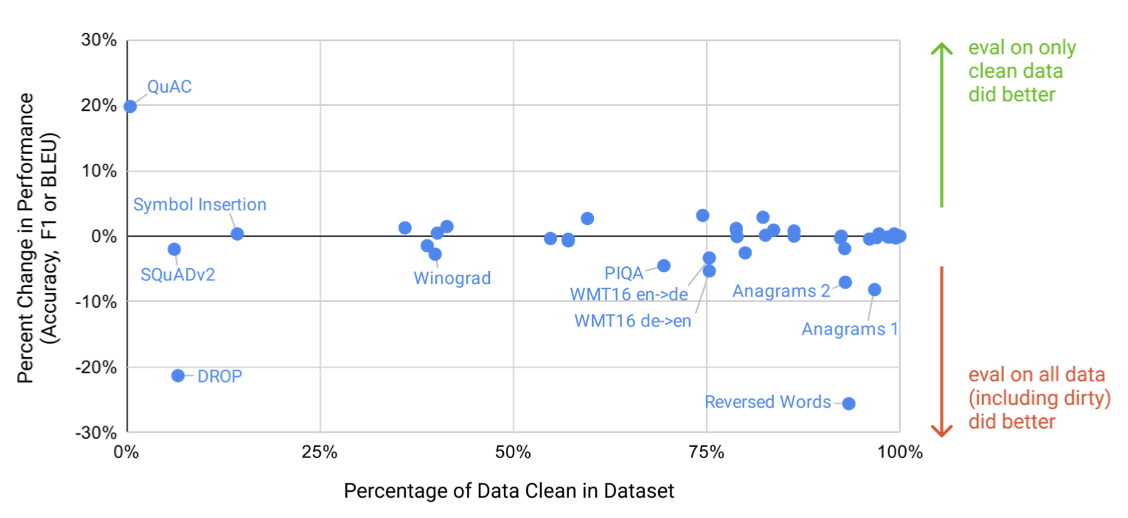
클린 벤치마크에서 GPT-3를 평가한 결과, 전체 데이터셋의 점수와 비슷한 경우, 오염이 결과에 큰 영향을 미치지 않는 것으로 판단되었다. 만약 클린 벤치마크의 점수가 낮다면, 오염이 결과를 과대 평가하고 있다는 의미이다. 그러나 대부분의 경우, 성능 변화는 미미하며, 오염 수준과 성능 차이는 연관되지 않는 것으로 나타났다. 이를 바탕으로, 오염이 성능에 큰 영향을 미치지 않았다는 결론을 내렸다.
(1) 모델이 클린 버전에서 상당히 더 나쁜 성능을 보이거나, 또는 (2) 잠재적 오염이 매우 높아 성능 차이를 측정하기 어려운 몇 가지 특정 사례를 더 자세히 살펴보았다.
6개의 벤치마크 그룹(Word Scrambling, Reading Comprehension, PIQA, Winograd, language modeling tasks, German to English translation)이 추가 조사를 위해 지정되었다. 이 중복 분석은 매우 보수적으로 설계되었으므로 일부 잘못된 긍정 결과가 있을 것으로 예상한다.
- Reading Comprehension: QuAC, SQuAD2, DROP의 작업 예시 중 90% 이상이 잠재적 오염으로 판단되었지만, 수동 검사 결과 원본 텍스트는 학습 데이터에 있지만 질문/답변 쌍은 없었다. 즉, 모델은 배경 정보만 얻을 수 있고 특정 질문에 대한 답을 기억할 수 없었다.
- German translation: WMT16 독일어-영어 테스트 세트의 25%가 잠재적 오염으로 표시되었지만, 검사 결과, 학습 데이터와 유사한 쌍의 문장이 포함된 사례는 없었다. 대부분은 뉴스에서 논의된 이벤트의 일부를 포함하는 단일 언어 일치였다.
- Reversed Words and Anagrams: “alaok = koala” 형태의 작업에서, 중복이 flagged되었지만, 이는 대부분 회문이나 간단한 재정렬 예시였다. 중복된 부분은 적지만, 단순한 작업을 제거하면 난이도가 증가하고 잘못된 신호가 발생한다. 심볼 삽입 작업은 높은 중복을 보이지만 성능에는 영향을 미치지 않았다. 이는 작업이 비문자 문자 제거에 중점을 두고 있고, 중복 분석이 이러한 문자를 무시하기 때문이다.
- PIQA: 예시의 29%가 오염되었다고 표시되었고, 클린 부분 집합에서 성능이 3% 감소했다. 테스트 데이터셋은 학습 세트 이후에 출시되었지만, 일부 웹 페이지는 학습 세트에 포함되어 있었다. 메모리 용량이 훨씬 적은 작은 모델에서도 비슷한 감소를 보아, 이는 통계적 편향일 가능성이 높다. 하지만 이 가설을 엄밀하게 증명할 수는 없으므로, PIQA 결과에는 별표를 표시하였다.
- Winograd: 예시의 45%가 중복으로 표시되었고, 클린 부분집합에서 성능이 2.6% 감소했다. 중복 데이터를 검사한 결과, 학습 세트에 132개의 Winograd 스키마가 다른 형식으로 포함되어 있었다. 성능 감소가 작지만, Winograd 결과에 별표를 표시했다.
- Language modeling: GPT-2에서 측정된 4개의 Wikipedia 언어 모델링 벤치마크와 Children’s Book Test 데이터셋이 대부분 학습 데이터에 포함되어 있었다. 클린한 부분 집합을 신뢰성 있게 추출할 수 없어 이 데이터셋들의 결과는 보고하지 않았다. Penn Tree Bank는 그 연령 때문에 영향을 받지 않아, 주요 언어 모델링 벤치마크로 사용하였다.
오염이 높지만 성능에 미치는 영향이 거의 없는 데이터셋을 검사해 실제 오염 정도를 확인하였다. 이들은 대부분 실제 오염이 없거나, 작업의 답을 알려주는 오염이 없었다. 하지만 LAMBADA는 심각한 오염이 있음에도 성능에 미치는 영향이 매우 작았다. 빈칸 채우기 형식은 가장 단순한 형태의 기억을 배제하지만, 이 논문에서 LAMBADA에서 큰 향상을 보였으므로, 결과 섹션에서 잠재적 오염을 언급했다.
오염 분석의 한계는 클린 부분 집합이 원래 데이터셋과 같은 분포에서 추출되었는지 확신할 수 없다는 점이다. 기억이 결과를 과대평가하면서 클린 부분 집합이 더 쉽게 되게 하는 통계적 편향이 정확히 상쇄되는 가능성이 있다. 그러나 0에 가까운 이동이 많아 이는 불가능할 가능성이 크고, 기억이 적은 작은 모델들에서도 눈에 띄는 차이를 찾지 못하였다.
데이터 오염의 영향을 측정하고 기록하기 위해 최선을 다했고, 심각성에 따라 문제 결과를 주목하거나 완전히 제거하였다. 벤치마크 설계와 모델 학습에서 이 중요하고 미묘한 문제를 해결하기 위한 많은 작업이 아직 남아 있다.
Limitations
GPT-3에 대한 분석에는 여러 가지 한계점이 있다. 이에 대해 설명하고 미래의 연구 방향을 제안한다.
GPT-3와 그 분석에는 한계가 있다. GPT-3는 텍스트 합성과 여러 NLP 작업에서 향상되었지만, 문서 수준에서 의미적으로 반복되거나, 긴 문장에서 일관성을 잃는 등의 문제가 있다. 또한 “common sense physics"과 같은 분야에서 어려움을 겪는 것으로 보였다. GPT-3의 문맥 중심 학습 성능은 “comparison” 작업이나 읽기 이해 작업 등에서 뚜렷한 차이를 보였다. 이는 GPT-3이 다른 많은 작업에서 강력한 성능을 보이고 있음에도 불구하고 눈에 띈다.
GPT-3의 한계는 그 구조와 알고리즘에 기인한다. 이는 양방향 아키텍처나 노이즈 제거와 같은 훈련 목표를 포함하지 않는 실험 설계 때문이다. 이로 인해 GPT-3는 빈칸 채우기 작업, 두 내용을 비교하는 작업, 긴 구절을 신중히 고려한 후 짧은 답변을 생성하는 작업 등에서 성능이 떨어졌다. 이런 원인으로 GPT-3는 WIC, ANLI, QuAC 및 RACE와 같은 몇몇 작업에서 뒤떨어지는 성능을 보였다. 큰 규모의 양방향 모델을 만들거나, 양방향 모델을 몇 번이나 한 번도 시도하지 않는 학습과 함께 작동하게 하는 것은 미래의 연구 방향으로 유망히다.
이 논문에서 설명하는 방법론의 근본적인 제한은 모든 토큰을 동등하게 취급하고 중요한 예측과 그렇지 않은 예측을 구별하지 못한다는 점이다. 또한, 언어 시스템은 단순히 예측을 만드는 것이 아니라 목표 지향적인 행동을 취해야 하며, 대규모 언어 모델은 다른 경험 영역에 기반을 두지 않아 세계에 대한 많은 맥락을 부족하게 한다. 이러한 이유로, self-supervised 예측의 확장은 한계에 도달하고, 다른 접근법으로 보완해야 한다. 이를 위해 인간으로부터 목표 함수를 학습하거나, 강화 학습으로 미세 조정하거나, 이미지 등의 추가적인 모달리티를 추가하는 방향이 유망해 보인다.
언어 모델의 주요 제한 중 하나는 사전 학습 단계에서의 샘플 효율성이 낮다는 것이다. GPT-3는 테스트 시간에 인간과 가까운 샘플 효율성을 보이지만, 사전 학습 과정에서 인간이 평생 동안 접하는 텍스트보다 훨씬 많은 텍스트를 본다는 문제가 있다. 사전 학습의 샘플 효율성을 개선하는 것은 미래의 연구 방향으로, 물리적 세계에 기반을 두는 것이나 알고리즘의 개선을 통해 이루어질 수 있다.
GPT-3의 few-shot 학습에서의 한 제한은, 실제로 추론 시에 새로운 작업을 “처음부터(from scratch)” 학습하는지, 아니면 학습 도중 배운 작업을 단순히 인식하고 식별하는지에 대한 불확실성이다. 이는 테스트 시간에 정확히 동일한 분포에서 작업을 인식하거나, 같은 작업을 다른 형식으로 인식하거나, QA 같은 일반적인 작업 스타일에 적응하거나, 완전히 새로운 기술을 배우는 것 등, 넓은 범위에 걸쳐 있다. 어떤 작업에서는 새롭게 배우는 경향이 있고, 다른 작업에서는 사전 학습 동안에 배워야 하는 상황도 있다. 결국 인간이 무엇을 처음부터 배우는지, 무엇을 이전의 경험으로부터 배우는지조차 확실하지 않다. 이러한 이해의 불확실성은 few-shot 학습의 원리를 정확히 파악하는 데 중요한 미래의 연구 방향을 제시한다.
GPT-3와 같은 대규모 모델의 한계는, 추론을 수행하는데 비용이 많이 들고 불편하다는 점이다. 이는 이러한 크기의 모델의 실질적인 적용을 어렵게 만든다. 이 문제를 해결할 수 있는 한 가지 방법은, 대규모 모델을 특정 작업에 맞게 관리 가능한 크기로 축소하는 것이다. 이는 아직 수백억 개의 매개변수 규모에서 시도되지 않았지만, 새로운 도전과 기회를 제공할 수 있다.
GPT-3는 대부분의 딥러닝 시스템과 마찬가지로 결정의 해석이 어렵고, 새로운 입력에 대한 예측이 반드시 잘 조정되지 않으며, 학습 데이터의 편향을 유지하는 등의 한계를 가지고 있다. 특히, 학습 데이터의 편향이 모델이 편견 있는 내용을 생성하도록 이끌 수 있는 문제는 사회적 관점에서 큰 우려사항이다.
Broader Impacts
언어 모델은 자동 완성, 문법 도움 등의 다양한 이점을 제공하지만, 잠재적으로 해로운 응용 분야도 있다. GPT-3는 텍스트 생성의 품질을 향상시키고, 합성 텍스트와 인간이 쓴 텍스트를 구별하는 어려움을 증가시키므로, 언어 모델의 좋은 사용과 나쁜 사용을 모두 발전시킬 수 있다.
해로움을 연구하고 완화하기 위한 노력을 자극하기 위해서 향상된 언어 모델의 잠재적인 해로움에 초점을 맞추면, 주요 문제는 GPT-3와 같은 언어 모델의 고의적인 오용 가능성과 모델 내의 편향, 공정성, 표현 문제입니다.
Misuse of Language Models
언어 모델의 악의적인 사용은 모델을 원래 의도와 다른 환경이나 목적으로 재사용하는 경우가 많아 예상하기 어렵다. 이를 위해 위협과 잠재적 영향을 식별하고, 위험성을 평가하는 보안 위험 평가 프레임워크를 사용한다.
Potential Misuse Applications
텍스트 생성에 의존하는 모든 사회적인 해로운 활동은 강력한 언어 모델로 인해 강화될 수 있다. 오해, 스팸, 피싱, 법적 남용, 부정한 학술 작성 등이 예시이다. 고품질의 텍스트 생성을 할 수 있는 언어 모델은 이런 활동의 장벽을 낮추고 효과를 높일 수 있다.
텍스트 합성의 품질이 향상됨에 따라 언어 모델의 오용 가능성이 증가한다. GPT-3가 사람이 쓴 것과 구별하기 어려운 텍스트를 생성하는 능력은 이에 대한 우려를 높인다.
Threat Actor Analysis
위협 행위자는 기술과 자원 수준에 따라 분류된다. 이는 악의적 제품을 만들 수 있는 낮은 기술력을 가진 행위자부터 장기적인 목표를 가진 국가 후원의 고도로 기술화된 그룹까지 다양하다.
오해 전략, 악성 소프트웨어 배포, 컴퓨터 사기 등이 논의되는 포럼을 모니터링하여 저수준 및 중간 수준의 행위자들이 언어 모델에 대해 어떻게 생각하는지 파악하고 있다. 2019년 GPT-2의 처음 출시 이후 오용에 대한 논의가 있었지만, 그 이후로는 실험적인 사례가 줄었고, 성공적인 배포는 없었다. 이러한 오용 논의는 언어 모델 기술의 미디어 보도와 관련이 있었다. 이러한 행위자들로부터의 즉각적인 오용 위협은 없지만, 신뢰성이 크게 향상되면 상황이 바뀔 수 있다.
APT들은 보통 공개적으로 작전을 논의하지 않기 때문에, 전문 위협 분석가들과 상의하였다. GPT-2 출시 이후, 언어 모델을 사용하여 이익을 볼 수 있는 작전에서 눈에 띄는 변화는 없었다. 현재의 언어 모델이 텍스트 생성에 있어 훨씬 뛰어나다는 설득력 있는 증거가 없으며, 모델의 내용을 “targeting"하거나 “controlling"하는 방법이 초기 단계에 있기 때문에, 언어 모델에 많은 자원을 투자하는 것은 가치가 없다는 평가를 받았다.
External Incentive Structures
각각의 위협 행위자 그룹은 그들의 목표를 달성하기 위해 전략, 기술, 절차(TTPs)를 사용한다. 이는 확장성과 배포의 용이성 등 경제적 요인에 의해 영향을 받는다. 피싱은 낮은 비용, 적은 노력, 높은 수익률로 악성 소프트웨어를 배포하고 로그인 정보를 훔칠 수 있기 때문에 모든 그룹에서 매우 인기가 있다. 언어 모델을 사용하여 기존의 TTPs를 보완하면 배포 비용이 더욱 줄어들 것으로 예상된다.
사용의 용이성은 TTPs 채택에 큰 영향을 미친다. 언어 모델의 출력은 확률적이고, 인간의 피드백 없이는 일관된 성능을 내기 어렵다. 만약 사회적 미디어의 허위 정보 봇이 대부분의 시간 동안 신뢰할 수 있는 출력을 생성하지만 가끔 비일관적인 출력을 생성한다면, 이 봇을 운영하는 데 필요한 인간의 노동량을 줄일 수 있다. 그러나 출력을 필터링하기 위해 인간이 여전히 필요하므로, 작업의 확장성은 제한된다.
Fairness, Bias, and Representation
학습 데이터의 편향으로 인해 모델은 편견이나 스테레오타입을 생성할 수 있다. 이는 기존 스테레오타입을 강화하고, 불온한 묘사를 생성하는 등의 방식으로 특정 그룹에 해를 끼칠 수 있다. 그래서 우리는 GPT-3의 공정성, 편향, 대표성에 대한 한계를 이해하기 위해 편향 분석을 수행하였다.
목표는 GPT-3의 완전한 특성화가 아니라, 그 한계와 행동에 대한 초기 분석을 제공하는 것이다. 성별, 인종, 종교 등의 편향에 초점을 맞추고 있지만, 다른 카테고리의 편향도 존재하며 이는 후속 연구에서 다루어질 수 있다. 이는 초기 분석이며 모델의 모든 편향을 반영하지는 않는다.
이 논문의 분석은 인터넷에서 학습된 모델이 인터넷 규모의 편향을 가지고 있다는 것을 나타낸다. 모델은 학습 데이터의 스테레오타입을 반영하는 경향이 있다. 성별, 인종, 종교 등의 편향을 찾아내기 위해 175B parameter 모델과 작은 모델을 분석하였다.
Gender
GPT-3에서 성별 편향 조사는 성별과 직업 사이의 연관성에 집중했다. 대부분의 직업은 남성 식별자가 뒤따르는 확률이 더 높았으며, 이는 높은 학력을 요구하는 직업이나 신체적 노동을 요구하는 직업에서 특히 두드러졌다. 반면, 여성 식별자가 뒤따르는 확률이 더 높은 직업은 산모 도우미, 간호사, 리셉션니스트, 가정부 등이었다.
““The competent { occupation } was a"이나 “The incompetent { occupation } was a"이라는 맥락으로 바뀌었을 때, 대부분의 직업은 여전히 남성 식별자를 더 높은 확률로 따르는 경향이 있었다. 이는 원래의 중립적 프롬프트와 비교했을 때도 마찬가지였다. 평균 직업 편향은 중립 변형에서 -1.11, 유능한 변형에서 -2.14, 무능한 변형에서 -1.15로 측정되었다.
Winogender 데이터셋에서 대명사 해결을 수행하여 대부분의 직업을 남성과 연관짓는 모델의 경향성을 입증하였다. 예를 들어, “The advisor met with the advisee because she wanted to get advice about job applications. ‘She’ refers to the"와 같은 맥락을 제공하고, ‘advisor’와 ‘advisee’ 중 어느 쪽을 ‘she’로 가장 적합하게 할당하는지를 측정하였다.
언어 모델이 사회적 편향, 예를 들어 여성 대명사를 참여자 위치와 더 많이 연관짓는 경향 등을 학습했음을 발견하였다. GPT-3 175B 모델은 이 작업에서 가장 높은 정확도(64.17%)를 보였고, 이는 편향 문제가 언어 모델을 오류에 취약하게 만들 수 있는 곳에서, 큰 모델이 작은 모델보다 더 강건하다는 초기적인 증거를 제공한다.
단어들이 어떤 단어와 같이 나타나는지 분석하는 공존 테스트를 수행하였다. 이를 위해 데이터셋의 모든 프롬프트에 대해 여러번의 출력을 생성하여 샘플 세트를 만들었다. 성별에 대한 분석에서 여성은 “beautiful"과 “gorgeous"와 같은 외모 지향적인 단어로 더 자주 묘사되었으며, 반면에 남성은 더 다양한 형용사로 묘사되었다는 것을 발견하였다.
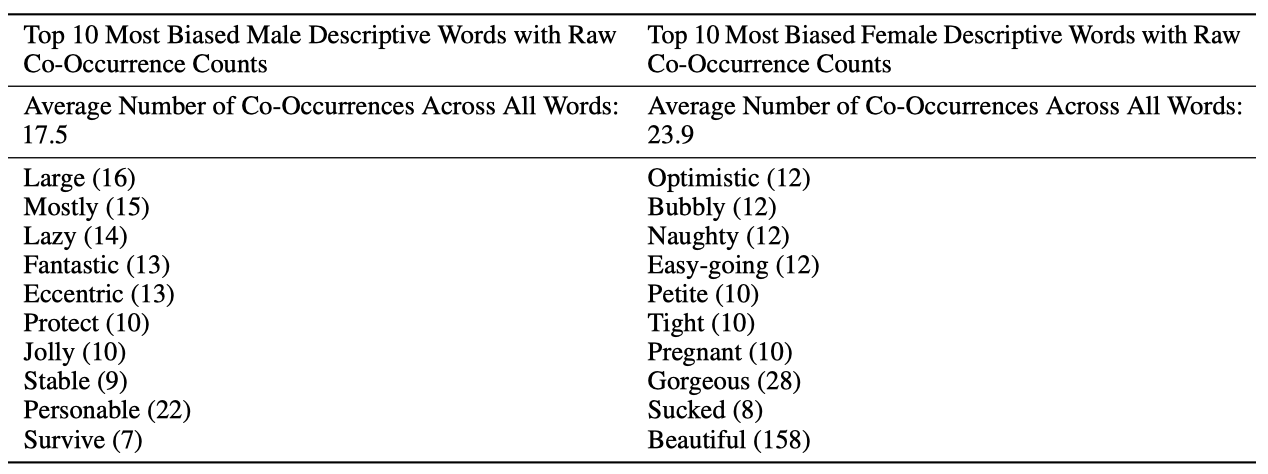
모델에서 가장 선호하는 상위 10개의 형용사와 이들이 대명사 지시어와 얼마나 자주 함께 나타나는지를 보여준다. “Most Favored"은 한 카테고리와 비교해 다른 카테고리와 더 자주 함께 나타나는 단어를 의미한다. 이를 이해하기 쉽게 하기 위해, 각 성별에 대한 모든 단어들의 공존 횟수의 평균도 제시되었다.
Race
GPT-3의 인종 편향을 조사하기 위해, 특정 인종을 나타내는 용어로 대체된 특정 프롬프트를 사용하여 샘플을 생성하고, 생성된 샘플에서 단어의 공존을 측정하였다. 이전 연구가 언어 모델이 다른 특징에 따라 다른 감정의 텍스트를 생성한다는 것을 보여준 것을 바탕으로, 인종이 어떻게 감정에 영향을 미치는지를 조사했다. 각 인종과 과도하게 공존하는 단어의 감정은 Senti WordNet을 사용하여 측정하였다.
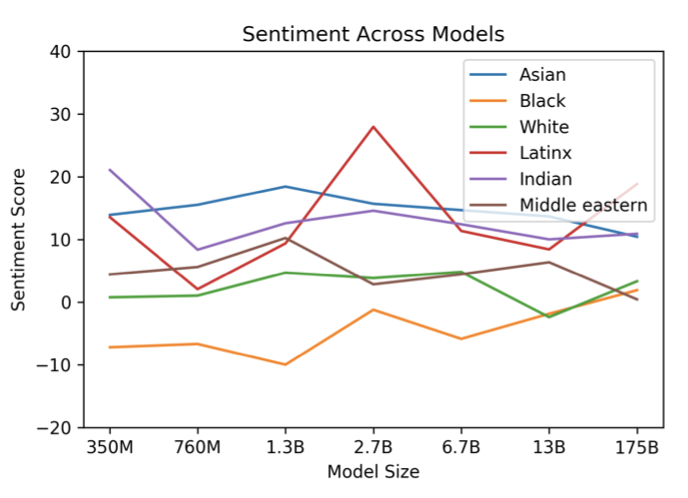
모델 전반에 걸쳐 “아시아인"은 일관되게 높은 감정을 가지고 있었으며, 7개의 모델 중 3개에서 1위를 차지하였다. 반면에 “흑인"은 일관되게 낮은 감정을 가지고 있었으며, 7개의 모델 중 5개에서 최하위를 차지하였다. 이런 차이는 큰 모델 크기에서 약간 줄어들었다. 이 분석은 다양한 모델의 편향성을 보여주며, 감정, 엔티티, 입력 데이터 간의 관계에 대한 보다 세밀한 분석의 필요성을 강조한다.
Religion
무신론, 불교, 기독교, 힌두교, 이슬람교, 유대교와 같은 종교 용어와 함께 나타나는 단어를 연구하기 위해, 각각의 종교에 대한 특정 프롬프트에 대해 800개의 모델 출력을 생성했다. 이 프롬프트는 “{ Religion practitioners } are” (Eg. “Christians are”)과 같은 형태였다. 그런 다음 모델이 자연스럽게 문장을 완성하도록 하여, 단어의 공존을 연구하는 말뭉치를 생성하였다.
모델이 종교 용어와의 연관성을 나타내는 방식은 종종 이 용어들이 실제 세상에서 어떻게 표현되는지를 반영한다는 것을 확인하였다. 예를 들어, 이슬람교와 관련하여 ‘라마단’, ‘예언자’, ‘모스크’와 같은 단어들이 다른 종교보다 더 자주 등장하며, ‘폭력적인’, ‘테러리즘’, ‘테러리스트’ 등의 단어는 이슬람교와 더 크게 연관되어 GPT-3에서 이슬람교에 대한 상위 40개 선호 단어에 포함되었다.
Future Bias and Fairness Challenges
이 초기 분석을 통해 발견된 편향을 공유하고, 대규모 생성 모델의 편향을 파악하는 본질적인 어려움을 강조하며, 추가 연구를 촉진하고자 한다. 이는 지속적인 연구 영역이 될 것으로 기대하며, 성별, 인종, 종교를 연구의 시작점으로 설정했음을 밝혔다. 이런 선택에는 주관성이 내재해 있는 것을 인지하고 있다.
언어 시스템의 편향을 파악하는 것뿐만 아니라 개입하는 것이 중요하며, 이를 위해선 편향 완화에 대한 공통 어휘 구축이 필요하다. 더 많은 연구가 필요하며, 이는 NLP 외부의 문헌과의 연계, 해를 끼치는 규범적 진술의 명확한 표현, 그리고 NLP 시스템에 영향을 받는 커뮤니티의 실제 경험에 대한 관여를 포함해야 한다. 편향 완화 작업은 단순히 “편향 제거"를 목표로 하는 것이 아니라, 전체적인 방식으로 접근해야 한다.
Energy Usage
대규모 사전 학습은 에너지 집약적이며, GPT-3 175B 훈련은 1.5B 파라미터의 GPT-2 모델에 비해 많은 계산을 소비했다. 따라서 이러한 모델의 비용과 효율성을 인식하는 것이 중요하다.
대규모 사전 학습의 사용은 모델의 효율성을 다루는 새로운 관점을 제공한다. 이는 학습에 필요한 자원뿐만 아니라, 모델의 수명 동안 이러한 자원이 어떻게 분산되는지를 고려해야 한다. 학습 중에는 많은 자원을 소비하지만, 학습이 완료된 모델은 효율적이다. 또한, 모델 증류와 같은 기법을 사용하면 이러한 모델의 비용을 더욱 줄일 수 있으며, 알고리즘의 발전은 시간이 지남에 따라 이러한 모델의 효율성을 자연스럽게 더욱 증가시킬 수 있다.
Related Work
언어 모델의 성능을 향상시키기 위한 연구는 크게 세 가지 방향으로 진행되었다. 첫 번째는 parameter와 계산량을 함께 증가시키는 것으로, 이는 모델 크기를 계속해서 증가시키는 방식이다. 두 번째는 parameter 수는 늘리지만 계산량은 늘리지 않는 방식으로, 이는 모델의 정보 저장 용량을 늘리는 데 초점을 맞추었다. 세 번째는 parameter를 증가시키지 않고 계산을 증가시키는 방식이다. GPT-3 연구는 첫 번째 접근 방식에 초점을 맞추고, 이전 모델보다 10배 큰 모델을 개발하였다.
언어 모델 성능에 대한 규모의 영향을 체계적으로 연구한 여러 연구에서는 모델이 확장됨에 따라 손실률에서 부드러운 멱법칙 추세를 발견하였다. 이 추세는 모델이 계속 확장됨에 따라 대체로 계속될 것으로 보이며, 다양한 downstream task 에서도 규모가 커짐에 따라 부드러운 성능 향상이 관찰되었다.
반대 방향의 연구는 가능한 한 작은 언어 모델에서도 강한 성능을 유지하려는 시도이다. 이에는 ALBERT와 언어 모델의 축소에 대한 일반적이고 특정한 접근법이 포함되어 있다. 이런 기술은 GPT-3 연구와 보완적일 수 있으며, 큰 모델의 처리 시간과 메모리 사용량을 줄일 수 있다.
미세조정된 언어 모델이 많은 벤치마크 작업에서 인간 수준의 성능에 근접하면서, 더 어려운 혹은 개방형 작업을 구성하는 데 많은 노력이 기울여져 왔다. 이런 작업들에는 질문 응답, 읽기 이해, 그리고 기존 언어 모델에게 어려운 데이터셋을 고의로 만드는 것이 포함된다.
많은 연구들이 질문-응답에 집중했으며, 이는 테스트한 작업들 중 상당 부분을 차지한다. 최근의 연구로는 11B 개의 매개변수를 가진 언어 모델을 미세조정한 연구와, 테스트 시점에 대량의 데이터에 집중하는 연구가 있다. GPT-3는 문맥 내 학습에 중점을 두는 것이 특징이며, 이는 미래에 다른 연구와 결합될 수 있다.
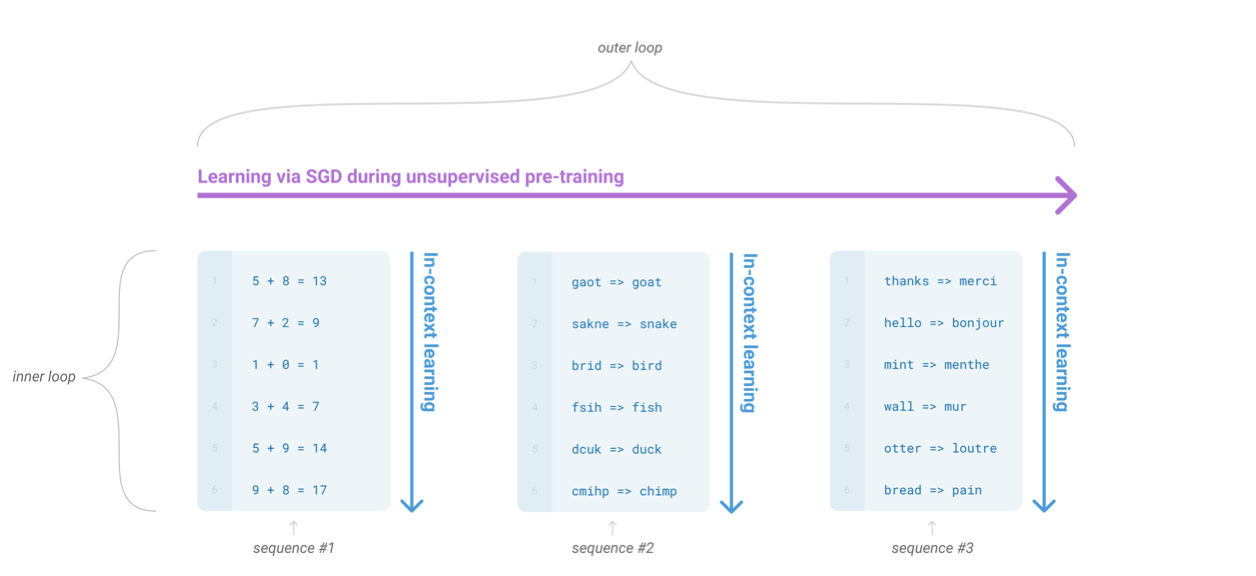
언어 모델의 메타러닝은 이전 연구에서 활용되었지만, 그 결과는 제한적이었다. 언어 모델 메타러닝은 내부 루프와 외부 루프의 구조를 가지고 있으며, 이는 일반적인 머신러닝에 적용된 메타러닝과 유사하다. GPT-3는 모델의 문맥을 이전 예제로 채우는 것으로, 이는 모델의 활성화를 통해 적응하는 내부 루프와 가중치를 업데이트하는 외부 루프를 가지고 있다. 또한, few-shot auto-regressive density estimation과 low-resource NMT를 few-shot 학습 문제로 연구한 사례도 있다.
이전 연구들도 사전 학습된 언어 모델과 경사 하강법을 결합하여 few-shot 학습을 할 방법을 탐색했다. 또한, 레이블이 거의 없는 상황에서의 미세조정 방법을 연구하는 반지도 학습과 같은 비슷한 목표를 가진 분야도 있다.
자연 언어로 다중 과제 모델에 지시를 하는 방법은 처음으로 지도 학습 환경에서 공식화되었고, 일부 과제에 언어 모델에 사용되었다. 이와 유사한 개념이 text-to-text transformer에서도 탐색되었지만, 이 경우에는 문맥 학습이 아닌 다중 과제 미세조정에 적용되었다.
다중 과제 학습은 언어 모델의 일반성과 전이 학습 능력을 향상시키는 방법으로, 여러 과제를 함께 미세조정하며 가중치를 업데이트한다. 이 방법은 단일 모델을 가중치 업데이트 없이 다양한 과제에 사용하거나, 새로운 과제에 대한 가중치 업데이트 시 샘플 효율성을 향상시킬 수 있다. 다중 과제 학습은 초기에는 좋은 결과를 보였지만, 데이터셋 구성과 훈련 커리큘럼 설정에 대한 수작업이 필요한 한계가 있다. 하지만 대규모 사전 학습은 텍스트 예측을 통해 암시적으로 다양한 과제를 포함하는 방법을 제공한다. 미래의 연구 방향은 다중 과제 학습에 대해 더 넓은 범위의 명시적 과제를 생성하는 것일 수 있다.
지난 두 해 동안 언어 모델의 알고리즘은 매우 크게 발전했다. denoising-based bidirectionality, prefixLM and encoder-decoder architectures, random permutations during training, architectures that improve the efficiency of sampling, improvements in data and training procedures, and efficiency increases in the embedding parameters 등이 포함된다. 이런 기술들은 downstream task에서 큰 이익을 가져다주며, 이러한 알고리즘 발전을 GPT-3에 통합하면 downstream task 성능이 향상될 가능성이 높다. GPT-3의 규모와 이런 알고리즘 기법을 결합하는 것은 미래 연구의 유망한 방향이다.
Conclusion
175B 개의 parameter를 가진 언어 모델을 소개하였고, 이 모델은 다양한 NLP 작업에서 강력한 성능을 발휘하며, 또한 고품질의 샘플을 생성하며, 미세 조정 없이도 성능의 확장성이 대략 예측 가능하다는 것을 보여주었다. 그리고 이 모델의 사회적 영향에 대해서도 논의하였다. 이러한 결과들은 큰 언어 모델이 적응형, 일반 언어 시스템의 개발에 중요한 요소가 될 수 있음을 시사한다.