Abstract
음악 생성은 심층 생성 모델의 발전과 함께 많은 관심을 받고 있지만, 텍스트에서 음악으로의 변환은 여전히 음악 구조의 복잡성과 높은 샘플링 속도 요구 때문에 어려운 과제이다. 이 논문에서는 JEN-1이라는 범용 고해상도 모델을 소개한다. JEN-1은 autoregressive와 non-autoregressive 학습을 통합한 diffusion 모델로, 텍스트로 가이드된 음악 생성 및 음악 인페인팅과 같은 다양한 작업을 수행할 수 있다. 평가 결과는 JEN-1이 텍스트와 음악의 정렬 및 품질에서 최신 기법들보다 우수한 성능을 보이면서도 계산 효율성을 유지한다는 것을 보여준다.
Introduction
음악은 조화, 선율, 리듬을 포함한 예술적 표현으로 큰 문화적 의미를 갖고 있다. 최근 deep generative 모델의 발전으로 음악 생성이 눈에 띄게 향상되었으나, 여전히 높은 샘플링 주파수와 복잡한 구조 등으로 인해 high-fidelity 음악 생성에는 어려움이 있다. 음악의 정확한 표현과 예술적 비전을 실현하기 위해서는 키, 장르, 멜로디 등의 속성을 세밀하게 조절할 수 있는 능력이 필수적이다.

text-to-music generation은 텍스트 설명과 음악 작곡을 연결하는 중요한 기술이다. 그러나 기존 모델은 스펙트로그램 변환 시 fidelity 손실, 비효율적인 생성 방법, 그리고 단일 작업에 한정된 학습 목표 등 여러 한계가 있다.
JEN-1은 text-to-music 모델로, 스펙트로그램 변환 없이 high-fidelity 48kHz 오디오를 직접 생성한다. 다중 작업 학습을 통해 다재다능성을 높이고, autoregressive와 non-autoregressive diffusion을 통합하여 생성 효율성과 모델링을 균형 있게 개선한다.
JEN-1은 최신 모델들보다 지각적으로 더 높은 품질의 음악을 생성하며 (85.7/100 vs 83.8/100), 각 기술 구성 요소의 효과를 입증하였다. 인간 평가자들은 JEN-1이 텍스트 프롬프트와 잘 일치하며 선율과 화성이 조화로운 음악을 생성한다고 평가하였다.
요약하자면, 이 연구의 주요 기여는 다음과 같다:
- JEN-1은 text-to-music generation, 연속 생성, 인페인팅을 단일 모델로 수행할 수 있는 솔루션을 제안한다.
- JEN-1은 waveform을 직접 모델링하여 스펙트로그램 변환 손실을 피하고, 48kHz 샘플링 주파수에서 고품질 음악을 생성한다.
- JEN-1은 autoregressive와 non-autoregressive diffusion 모드를 통합하여 순차적 의존성과 시퀀스 생성을 동시에 개선한다.
- 이 논문은 text-to-music generation 분야에서 중요한 발전을 이루며, 텍스트 프롬프트와 선율 구조에 맞는 고품질 음악을 생성하는 강력하고 효율적인 프레임워크를 제시한다.
Related Work
Single-task vs. Multi-task. conditional neural music generation은 low-level 제어 신호(예: 가사, MIDI)와 high-level 의미적 설명(예: 텍스트, 이미지)을 조건 신호로 사용한다. 그러나 이러한 신호-오디오 쌍은 부족해, self-supervised technique 으로 모델을 학습한다. 이 연구는 text-to-music generation을 위한 정렬된 쌍과 오디오 전용 self-supervised 학습을 통해 노이즈 강건성을 높이고, high-level 의미적 설명과 low-level 제어 신호를 기반으로 음악을 생성한다.
Waveform vs. Spectrum. 계산 효율성을 위해 raw audio waveform을 직접 사용하는 것은 어렵다. 그래서 음악 생성에서는 두 가지 주요 전처리 접근 방식이 사용된다. 첫 번째는 waveform을 mel-spectrogram으로 변환한 후, 이미지 처리 기술을 이용하여 오디오를 생성하는 방법이다. 두 번째는 quantization-based audio codec을 활용해 continuous waveform 신호를 압축된 이산 표현으로 변환하는 방법이다. 예를 들어, MusicGen은 EnCodec을 통해 양자화된 오디오 유닛에 transformer-based decoder를 적용하고, AudioLM과 AudioPaLM은 텍스트를 오디오 토큰으로 변환 후 SoundStream을 사용해 raw audio로 변환한다.
Autoregressive vs. Non-autoregressive. 음악 생성에는 autoregressive와 non-autoregressive 접근 방식이 있다. autoregressive 모델 (예: PerceiverAR, AudioGen, MusicLM, Jukebox)은 transformer를 사용해 토큰을 순차적으로 생성하여 높은 일관성을 제공하지만, 속도가 느리다. 반면, non-autoregressive 모델은 여러 토큰을 동시에 생성해 속도를 크게 개선한다. 최근에는 diffusion 모델 (예: Make-An-Audio, Noise2Music, AudioLDM, TANGO)이 빠른 생성 속도와 높은 품질을 동시에 달성하는 데 유망한 접근법으로 주목받고 있다.
Peliminary
Conditional Generative Models
컨텐츠 합성 분야에서는 autoregressive(AR) 또는 non-autoregressive(NAR) 모델을 사용한다. AR 패러다임은 언어의 순차적 구조에 적합하여, transformer 기반 모델(GPT 시리즈 등)이 텍스트 생성에 널리 사용된다. AR 방법은 가시적인 히스토리 토큰을 기반으로 미래 토큰을 예측하며, 확률은 다음과 같이 표현된다:
$$ p_{AR}(y \mid x) = \prod_{i=1}^{N} p(y_i \mid y_{1:i-1}; x) $$
여기서 $y_i$는 시퀀스에서 $i$번째 토큰을 의미한다.
computer vision(CV)에서는 이미지가 시간 시리즈 구조가 없고 연속적인 공간을 차지하기 때문에 NAR 접근법이 더 적합하다. stable diffusion과 같은 NAR 방법은 이미지 생성에서 널리 사용되며, latent embedding을 conditional independence 하에 균일하게 생성한다. 확률은 다음과 같이 표현된다:
$$ p_{NAR}(y \mid x) = \prod_{i=1}^{N} p(y_i \mid x) $$
NAR의 병렬 생성 방식은 속도 면에서 유리하지만, 장기적인 일관성은 부족할 수 있다.
이 연구에서는 오디오 데이터가 이미지와 텍스트의 특성을 모두 지닌 하이브리드 데이터라고 주장한다. 따라서, JEN-1 디자인에서 autoregressive와 non-autoregressive 모드를 결합한 omnidirectional diffusion을 제안한다.
Diffusion Models for Audio Generation
diffusion model은 데이터 분포 $p(x)$를 학습하기 위해 개발된 확률적 모델이다. 학습 과정은 전방 확산 프로세스와 점진적 노이즈 제거로 구성되며, 각 과정은 $T$ 단계의 마르코프 체인으로 이루어진다. 전방 확산 프로세스는 초기 변수 $z_0$를 점진적으로 교란시켜 표준 가우시안 분포로 수렴시키며, 이 과정은 다음과 같이 표현된다:
$$ q(z_t \mid \bar{\alpha}_t; x) = N(z_t \mid \sqrt{\bar{\alpha}_t} z_0, (1 - \bar{\alpha}_t)I) $$
$$ \bar{\alpha}_t = \prod_{i=1}^{t} \alpha_i $$
여기서 $\alpha_i$는 시간 단계 $t$에 따라 감소하는 계수이며, $z_t$는 해당 시간 단계의 잠재 상태이다. 역방향 과정은 표준 가우시안 노이즈에서 시작해, 점진적으로 노이즈 제거 전이 $p_\theta (z_{t-1} \mid z_t ; x)$를 이용해 생성한다. 이는 다음과 같이 표현된다:
$$ p_\theta (z_{t-1} \mid z_t ; x) = N(z_{t-1} ; \mu_\theta (z_t , t ; x), \Sigma_\theta (z_t , t ; x)) $$
여기서 평균 $\mu_\theta$와 분산 $\Sigma_\theta$는 파라미터 $\theta$로 학습된다. 학습 가능한 파라미터가 없는 미리 정의된 분산을 사용하며, 조건부 확산 모델의 학습 목표는 다음과 같다:
$$ L = \mathbb{E}_{z_0, \epsilon \sim N(0,1), t} \left[ | \epsilon - \epsilon_{\theta} (z_t , t) |^2_2 \right] $$
여기서 $t$는 균일하게 샘플링되고, $\epsilon$는 실제 노이즈, $\epsilon_\theta (\cdot)$는 예측된 노이즈이다.
기존의 non-autoregressive diffusion 모델은 음악의 순차적 의존성을 잘 포착하지 못한다. 이를 해결하기 위해, unidirectional과 bidirectional 학습을 통합한 JEN-1 프레임워크를 제안하며, 이를 통해 음악 데이터의 순차적 의존성을 더 효과적으로 포착할 수 있다.
Method
JEN-1은 unidirectional과 bidirectional 모드를 결합한 전방향 1D diffusion 모델로, 텍스트나 음악 표현을 조건으로 하는 음악 생성을 지원한다. 노이즈에 강한 latent embedding 공간에서 작동하며, 단일 모델로 고해상도 음악을 생성할 수 있다. JEN-1은 autoregressive와 non-autoregressive 학습을 동시에 활용하여 순차적 의존성과 시퀀스 생성을 개선하며, 문맥 학습과 다중 작업 학습을 통해 텍스트나 멜로디 기반의 조건부 생성을 지원한다.
Masked Autoencoder for High-Fidelity Latent Representation Learning
High Fidelity Neural Audio Latent Representation. 제한된 자원으로 학습을 하면서도 품질을 유지하기 위해, JEN-1은 고해상도 오디오 오토인코더 $E$를 사용해 원본 오디오를 잠재 표현 $z$로 압축한다. 이 모델은 시간과 주파수 도메인에서의 재구성 손실과 패치 기반 적대적 목표를 결합하여 학습되며, 양자화 없이 연속적인 임베딩을 직접 추출한다. 이를 통해 오디오 재구성의 충실도를 높이고 고주파 세부 사항을 잘 유지한다.
Noise-robust Masked Autoencoder. 디코더 $D$의 강 robustness을 높이기 위해, 중간 잠재 임베딩의 5%를 무작위로 마스킹하는 전략을 사용한다. 이로 인해 디코더는 손상된 입력에서도 고품질의 오디오를 재구성할 수 있다. 48kHz 스테레오 오디오를 큰 배치 사이즈로 학습하고, 지수 이동 평균을 사용하여 가중치를 집계한다. 이 개선 덕분에 오디오 오토인코더의 성능이 원본 모델을 초월하며, 이를 후속 실험에 적용한다.

Normalizing Latent Embedding Space. 임의로 확장된 잠재 공간을 피하기 위해, JEN-1은 성분별 분산을 추정하고 잠재 $z$를 단위 표준 편차로 조정하는 대신, 채널별로 평균 0 정규화하고 SVD를 통해 공분산 행렬을 단위 행렬로 변환하는 후처리 기술을 사용한다. 배치-증분 알고리즘과 차원 축소 전략을 추가하여 이방성 문제를 해결하고 전체 효과를 개선한다.
Omnidirectional Latent Diffusion Models
기존의 연구에서는 mel-spectrogram을 사용해 오디오 생성을 이미지 생성으로 변환하였다. 그러나 이 과정에서 품질이 저하된다고 주장하며, JEN-1은 이를 해결하기 위해 시간 1D efficient U-Net을 사용한다. 이 U-Net 모델은 raw 오디오 파형을 직접 모델링하고, 잔여 연결을 통해 down-sampling과 up-sampling 블록을 결합하여 노이즈 예측을 수행한다. 입력은 노이즈 샘플과 조건 정보로 구성되며, diffusion 과정에서의 노이즈 예측이 출력된다.
Task Generalization via In-context Learning. 다양한 학습 목표를 위해, UNet 아키텍처를 변경하지 않고 새로운 omnidirectional latent diffusion 모델을 제안한다. JEN-1은 음악 생성 작업을 텍스트 기반 맥락 학습으로 변환하며, 맥락과 스타일에 맞는 현실적인 음악을 생성한다. 예를 들어, 음악 채우기나 연속 작업에서는 추가된 마스크된 음악 정보가 잠재 임베딩으로 추출되어 U-Net의 입력에 추가 채널로 포함된다.
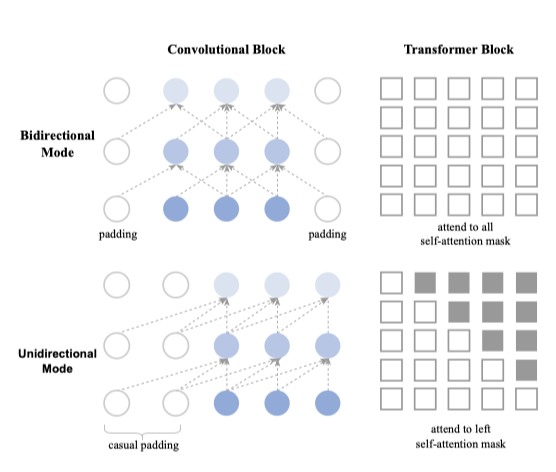
From Bidirectional mode to Unidirectional mode. JEN-1은 음악의 순차적 특성을 반영하기 위해 unidirectional diffusion 모드를 통합한다. 이는 오른쪽의 잠재 생성이 왼쪽에서 생성된 것에 의존하도록 하며, unidirectional self-attention mask와 causal 패딩을 사용한다. 이 모델은 다양한 입력 경로를 통해 데이터를 통합할 수 있으며, 학습 중에는 unidirectional 모드와 bidirectional 모드 간에 전환이 가능하다. 모든 1D convolutional 레이어에서 causal 패딩을 사용하고, triangular attention mask로 미래 토큰을 마스킹한다.
Unified Music Multi-Task Training
기존의 방법이 단일 텍스트 안내 목표에 의존하는 반면, JEN-1은 여러 생성 학습 목표를 공통 파라미터로 동시에 통합한다. 이 프레임워크는 bidirectional 텍스트 안내 음악 생성, bidirectional 음악 채우기, unidirectional 음악 연속 등 세 가지 음악 생성 작업을 포함하며, 통합된 학습 절차를 통해 모델의 일반화 능력과 순차적 의존성 처리 능력을 향상시킨다.
Text-guided Music Generation Task. 이 작업에서는 bidirectional 모드와 unidirectional 모드를 사용하여, bidirectional 모델은 포괄적인 맥락 정보를 인코딩하고, unidirectional 모델은 시간적 의존성을 학습한다. 또한, U-Net의 입력에서 일관성을 유지하기 위해 전체 크기의 마스크를 빈 마스크 오디오와 함께 추가 조건으로 사용한다.
Music inpainting Task. 오디오 편집에서 인페인팅은 누락된 음악을 복원하거나 손상된 오디오 및 원치 않는 요소를 제거하는 기술이다. JEN-1은 bidirectional 모드를 사용하여, 학습 시 20%에서 80% 사이의 비율로 랜덤 오디오 마스크를 생성하고 이를 통해 마스크된 오디오를 얻어 U-Net 모델의 조건부 입력으로 활용한다.
Music Continuation Task. JEN-1 모델은 omnidirectional diffusion을 통해 음악 인페인팅과 연속을 지원한다. 기존 diffusion 모델은 non-autoregressive 성격으로 인해 성능이 부족했으며, 이를 해결하기 위해 JEN-1은 unidirectional 모드를 사용하여 왼쪽 컨텍스트에만 주의를 기울이고, 20%에서 80% 비율로 오른쪽 전용 마스크를 생성하여 음악 연속을 시뮬레이션한다.
Experiment
Setup
Implementation Details. 마스크된 음악 오토인코더는 48kHz 음악 오디오를 인코딩하기 위해 320의 hop size를 사용하며, latent embedding의 차원은 128이다. 학습 중 5%의 latent embedding을 랜덤하게 마스킹하여 노이즈에 강한 디코더를 구현한다. FLAN-T5 모델을 사용하여 텍스트 임베딩을 추출하고, omnidirectional diffusion 모델의 intermediate cross-attention 차원은 1024로 설정되어 746M 파라미터를 가진다. 다중 작업 학습 중에는 배치의 1/3을 각 작업에 할당하며, 분류기 없는 가이던스를 적용하여 샘플과 텍스트 조건 간의 일치를 개선한다. cross-attention layer는 0.2의 확률로 self-attention으로 교체된다. JEN-1 모델은 8개의 A100 GPU에서 200k 스텝 동안 AdamW 옵티마이저를 사용해 학습되며, 학습률은 3e−5에서 시작하여 선형으로 감소한다.
Datasets. JEN-1은 5,000시간의 고품질 프라이빗 음악 데이터로 학습된다. 데이터는 48kHz로 샘플링된 전체 길이의 음악과 풍부한 메타데이터를 포함한다. 평가에는 5.5K의 10초 길이 음악 샘플로 구성된 MusicCaps 벤치마크가 사용되며, 장르 균형이 맞춰진 1K 샘플 서브셋도 포함된다. 객관적인 메트릭은 불균형 세트에서, 정성적 평가와 변별 분석은 장르 균형이 맞춰진 세트에서 수행된다.
Evaluation Metrics. 정량적 평가는 세 가지 메트릭을 사용한다: Fréchet Audio Distance (FAD), Kullback-Leibler Divergence (KL), 그리고 CLAP 점수. FAD는 생성된 오디오의 그럴듯함을 측정하며, KL은 원본과 생성된 음악의 유사성을, CLAP 점수는 오디오와 텍스트의 정렬을 평가한다. 주관적 평가는 인간 평가자가 생성된 음악의 품질(T2M-QLT)과 텍스트와의 정렬(T2M-ALI)을 1에서 100까지의 척도로 평가하는 방식으로 진행된다.
Comparison With State-Of-The-Arts
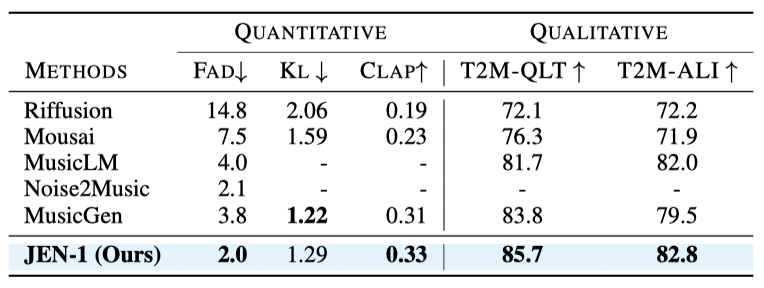
JEN-1은 최신 기술인 Riffusion, Mousai, MusicLM, MusicGen, Noise2Music과 비교되었다. 이들은 모두 대규모 음악 데이터셋에서 학습된 최신 음악 합성 모델들이다. JEN-1은 MusicCaps 테스트 세트에서 정량적 및 정성적 평가 모두에서 우수한 성능을 보였으며, 특히 FAD와 CLAP 점수에서 Noise2Music과 MusicGen을 크게 초월하였다. 인간 평가에서도 JEN-1은 T2M-QLT와 T2M-ALI 점수에서 최고 점수를 기록했다. JEN-1은 또한 계산 효율성이 뛰어나, MusicGEN의 22.6%와 Noise2Music의 57.7%에 해당하는 파라미터 수로 구현된다.
Performance Analysis
제안된 omnidirectional diffusion 모델 JEN-1의 다양한 측면을 조사하기 위해 종합적인 성능 분석을 제시한다.
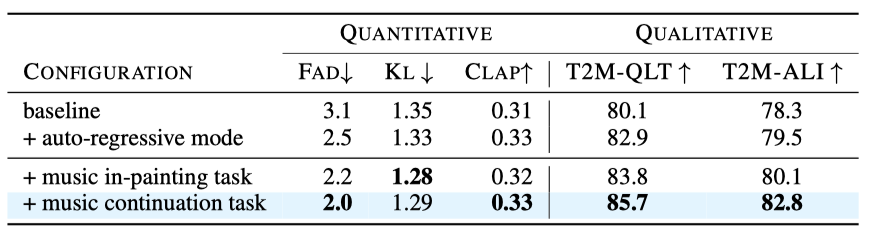
Ablation Studies. omnidirectional diffusion 모델의 효과를 평가하기 위해, 모델 구성과 다양한 다중 작업 목표를 비교하였다. 결과는 JEN-1이 auto-regressive 모드로 음악의 시간적 일관성을 개선하고, 다중 작업 학습 목표가 성능을 향상시키며, 고충실도의 음악 생성이 추가 비용 없이 가능하다는 것을 보여준다.
Generation Diversity. tranformer 기반 방법과 비교하여, diffusion 모델은 생성의 다양성이 뛰어나다. JEN-1은 동일한 텍스트 프롬프트로 다양한 샘플을 생성하며, 높은 품질을 유지하면서 인상적인 다양성을 보여준다.
Generation, Generalization, and Controllability. JEN-1은 supervised learning으로 학습되었음에도 zero-shot 생성 능력과 뛰어난 제어 능력을 보여준다. 데모 페이지에서 창의적인 zero-shot 프롬프트로 만족스러운 음악을 생성하는 예시를 제공하며, 음악의 장르, 악기, 분위기 등을 효과적으로 반영하는 것을 확인할 수 있다.
Conclusion
이 연구에서는 JEN-1을 제안하며, 이는 기존 방법들보다 효율성과 품질 모두에서 우수한 text-to-music 생성 프레임워크이다. JEN-1은 mel-spectrogram 대신 직접 파형을 모델링하고, auto-regressive와 non-autoregressive 학습을 결합하며, 다중 작업 목표를 통해 48kHz 고품질 음악을 생성한다. diffusion 모델과 마스크된 오토인코더의 통합으로 복잡한 시퀀스 의존성을 잘 포착하며, 평가 결과 JEN-1은 주관적 품질, 다양성, 제어 가능성에서 우수함을 입증하였다.
이 연구는 텍스트로부터 고품질의 제어 가능한 음악을 생성하는 혁신적인 방법을 제시하며, text-to-music 생성의 발전을 이끌고 있다. 향후에는 외부 지식 통합 및 다른 크로스-모달 생성 작업으로의 확장이 고려될 수 있다. 이 연구가 예술적 생성 모델 개발에 영향을 미치고, 음악 작곡, 공유, 감상 방식을 혁신할 잠재력을 지니고 있기를 기대한다.