Abstract
사전 학습된 언어 모델은 zero-shot, few-shot, 미세 조정 기법을 통해 다양한 자연어 처리 분야에서 state-of-the-art의 정확도를 달성할 수 있다. 이러한 성공으로 인해 이 모델들의 크기는 빠르게 증가하였고, 이에 따라 고성능 하드웨어와 소프트웨어, 그리고 알고리즘 기법이 필요해졌다. 이 논문에서는 Microsoft와 NVIDIA의 협력을 통해 개발된 530B 개의 parameter를 가진 가장 큰 언어 모델인 Megatron-Turing NLG 530B (MT-NLG)의 학습에 대해 설명하고 있다. 이 모델은 DeepSpeed와 Megatron을 활용한 3D 병렬화 방법론을 통해 학습되었다. 또한, 이 모델은 여러 NLP 벤치마크에서 우수한 성능을 보여주며, 대규모 학습 인프라와 언어 모델, 그리고 자연어 생성의 발전을 도모할 것이라고 기대하고 있다.
Introduction
최근에 출시된 BERT, GPT-2, RoBERTa와 같은 기초 모델들은 AI 시스템을 대규모로 사전 학습시키고, 전이 학습을 통해 다양한 작업에 적용하는 새로운 패러다임을 제시하였다. 이 모델들은 transformer 아키텍처, self-supervised learning, few-shot conditioning, 미세 조정 등을 결합하여 최첨단 자연어 처리 시스템에서 널리 사용되고 있다.
모델을 확장하는 것이 성능을 크게 향상시킨다는 것이 최근 연구들에서 입증되었다. 특히 zero-shot과 few-shot 설정에서 두드러진 성능 향상이 있었다. 예를 들어, GPT-3와 같은 대형 언어 모델은 미세 조정이나 gradient 업데이트 없이도 언어 작업에서 경쟁력 있는 성능을 발휘한다. 이러한 모델은 간단한 지시사항과 몇 가지 예제만으로 새로운 언어 작업을 수행할 수 있게 하며, 일관성 있는 장문의 텍스트 생성, 실세계 지식을 이용한 응답 생성, 기본적인 수학 연산 수행 등의 능력을 보여준다.
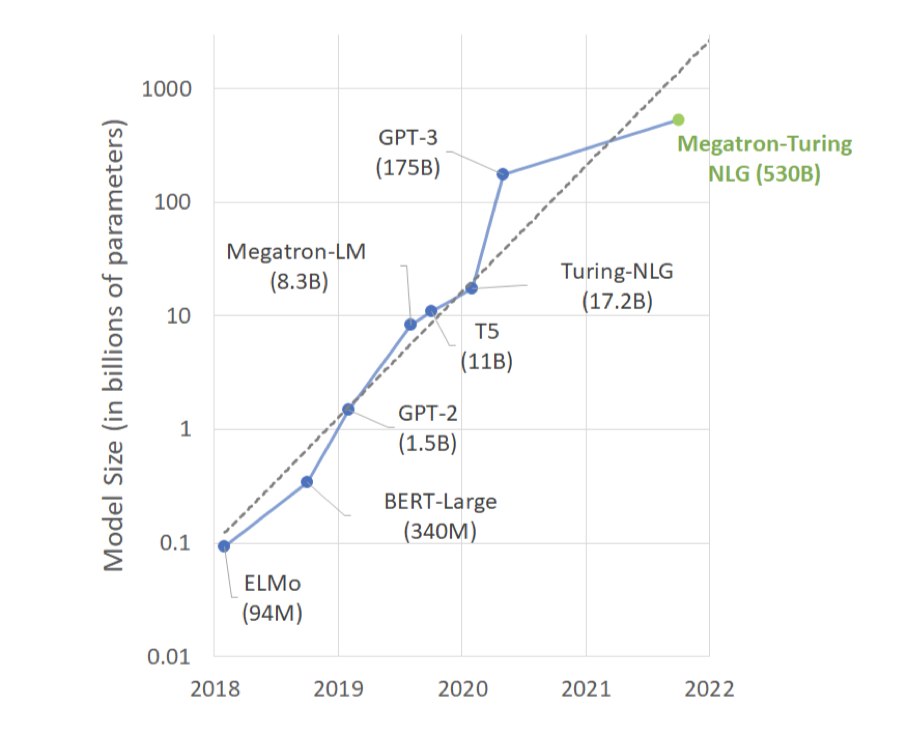
거대 언어 모델의 빠른 발전은 계산 자원의 증가, 대규모 데이터셋의 사용 가능성, 그리고 소프트웨어 스택의 발전에 의해 촉진되었다. 이러한 모델 학습을 위해 최첨단 슈퍼컴퓨팅 클러스터가 사용되며, 고품질이고 다양한 대량 데이터셋의 처리는 모델의 성능과 수렴에 기여한다. 그러나 모델 parameter 크기의 지수적인 성장을 지속하기 위해서는 새로운 방법, 인프라, 학습 기능 개발에 상당한 진전이 필요하다.
대형 모델을 학습시키는 것은 어렵다. 이는 가장 큰 GPU의 메모리에도 모델의 parameter를 담을 수 없을 뿐만 아니라, 대량의 계산 작업이 필요하여 알고리즘, 소프트웨어, 하드웨어 스택을 동시에 최적화하지 않으면 학습 시간이 너무 길어질 수 있기 때문이다. 이를 해결하려면 메모리와 계산 모두에서 확장 가능한 효율적인 병렬화 기법이 필요하다.
모델 크기 증가에 따른 성능 향상을 추구하여, 우리는 530B 개의 parameter를 가진 transformer 기반 언어 모델인 Megatron-Turing NLG 530B (MT-NLG)를 구축하였다. 이는 현재까지 알려진 가장 큰 단일 언어 모델로, GPT-3보다 parameter가 3배 더 많다. 하지만, 더 많은 총 parameter를 가진 sparse 모델 구조가 학습된 것에 대해 언급하며, 이러한 접근법을 따르면 비교 가능한 parameter 효율성과 일반화 능력을 가질 수 있을지는 아직 불확실하다.
MT-NLG 학습은 NVIDIA의 Megatron-LM과 Microsoft의 DeepSpeed 간의 협력, 그리고 여러 AI 혁신을 통해 가능해졌다. 데이터, 파이프라인, 텐서 슬라이싱 기반 병렬성을 결합하여 효율적이고 확장 가능한 3D 병렬 시스템을 구축하였다. 또한, 수백 조의 토큰을 가진 고품질 자연어 학습 말뭉치를 구축하고, 최적화 효율성과 안정성을 향상시키는 학습 레시피를 공동 개발하였다.
Large Model Training Infrastructure
최첨단 클러스터들(예: NVIDIA Selene, Microsoft Azure NDv4)은 수조 개의 parameter를 학습할 수 있는 충분한 컴퓨팅 파워를 가지고 있다. 하지만 이러한 슈퍼컴퓨터의 전체 잠재력을 발휘하려면 수천 개의 GPU를 통해 병렬화하는 메모리 및 컴퓨팅 효율 전략이 필요하다. 기존의 병렬화 전략들은 이런 규모의 모델을 학습하는 데 한계가 있다. 이에 대한 도전과제를 해결하기 위해, 우리는 통합적이고 강력한 학습 인프라를 설계하고 성능을 평가하였다.
Challenges
대규모 언어 모델을 학습하는데 있는 도전 과제인 메모리와 컴퓨팅 효율성, 그리고 다양한 병렬화 전략의 타협점에 대해 논의하고 있다.
Memory and Compute Efficiency
Memory Efficiency 530B 개의 parameter를 가진 모델을 학습하는 데 필요한 메모리 요구량은 단일 GPU 장치에서 제공할 수 있는 것을 훨씬 초과한다.
mixed precision 학습은 forward와 backward propagation 과정에서 가중치와 기울기를 half precision 형식으로 저장하며, optimizer에서의 수치 안정성을 위해 전체 정밀도 복사본을 유지한다. Adam optimizer를 사용하여 학습할 때, 학습은 parameter 당 20 바이트의 메모리를 사용한다.
따라서 530B 개의 parameter를 가진 모델을 학습하는 데는 모델 가중치, 기울기, 그리고 최적화 상태를 위한 총 10테라바이트 이상의 메모리가 필요하다.
활성화는 학습 배치 크기, 시퀀스 길이, 모델 차원에 따라 크게 메모리를 소비한다. 거대 언어 모델을 학습할 때는 체크포인팅과 각 변환기 블록의 활성화를 다시 계산하여 활성화에 필요한 메모리를 줄이는 것이 일반적이다. 그러나 레이어 간 경계에서의 활성화는 여전히 저장되어야 한다.
$$ \text{batch-size} × \text{number-of-layers} × \text{sequence-length} × \text{hidden-dimension} × 2 \text{bytes} $$
활성화 메모리 요구 사항은 기울기 누적 전략을 통해 완화될 수 있다. 이 전략은 학습 배치를 여러 마이크로 배치로 나누고 이들을 순차적으로 처리한 후 그 결과 기울기를 누적하는 방식이다. 이 방법을 통해 학습 배치 크기를 늘려도 활성화 메모리가 증가하지 않는다. 예를 들어, 1920개의 마이크로 배치로 학습하면 최대 활성화 메모리를 16.9테라바이트에서 8.8기가바이트로 줄일 수 있다.
Compute Efficiency 대형 GPU 클러스터에서 높은 계산 효율을 달성하는 것은 어렵다. 대형 배치 크기는 계산 효율성을 높이는데 도움이 될 수 있지만, 너무 큰 배치 크기는 모델 품질에 부정적인 영향을 미칠 수 있다. 특히, 4000개의 GPU를 가진 경우에도 배치 크기가 4000을 넘어서면 GPU 당 배치 크기가 1로 제한되어 계산 효율성이 제한된다.
Tradeoffs of Data, Tensor, and Pipeline Parallelism
Data Parallelism 데이터 병렬화는 깊은 학습에서 각 입력 배치를 여러 데이터-병렬 작업자들에게 분배하는 기법이다. 이 방법은 계산 효율성과 구현의 용이성을 제공하지만, 배치 크기를 임의로 크게 확장할 수 없으며, 이는 작업자 수에 따라 배치 크기를 확장하는 것에 의존한다. 그러나 이를 과도하게 크게 확장하면 모델 품질에 영향을 줄 수 있다.
Memory Efficiency: 데이터 병렬화는 모델과 최적화기를 모든 작업자에게 복제하기 때문에 메모리 효율이 낮다. 이 문제를 개선하기 위해, ZeRO는 복제된 데이터를 작업자들 사이에 분할하여 데이터 병렬화의 메모리 효율성을 향상시키는 최적화 기법들을 제공한다.
Compute Efficiency: 병렬화 수준과 배치 크기를 높여도 각 작업자의 계산량은 일정하며, 데이터 병렬화는 규모가 작을 때 거의 완벽한 확장성을 보인다. 그러나 gradient를 집계하는 통신 비용은 모델 크기가 커질수록 증가하고, 이로 인해 대형 모델이나 통신 대역폭이 낮은 시스템의 계산 효율성이 제한될 수 있다. gradient 누적은 이 비용을 분산하는 전략으로, 배치 크기를 더 크게 하고, 미세 배치에서 여러 번의 전파를 수행하면서 gradient를 누적한다. 또한, 다른 텐서의 gradient를 계산하는 것과 병렬로 gradient를 동시에 전송함으로써 성능을 향상시킬 수 있다.
Tensor Model Parallelism 텐서 모델 병렬화는 모델의 각 레이어를 작업자들 사이에 분할하는 기법으로, 작업자 수에 비례해 메모리 사용량을 줄인다. Megatron은 이를 이용해 대규모 언어 모델의 transformer block을 효율적으로 분할한다.
Memory Efficiency: 텐서 병렬화는 작업자 수에 따라 모델의 메모리 사용량을 줄이며, 모델 구조에 따라 일부 활성화 메모리도 감소시킨다. 그러나 일부 데이터는 여전히 복제될 수 있다.
Compute Efficiency: 텐서 병렬화는 각 전파 과정에서 활성화 데이터의 추가 통신을 요구하며, 이로 인해 고대역폭 통신이 가능한 환경에서 효율적으로 작동한다. 모델-병렬 작업자는 각 통신 단계 간의 계산량을 줄이므로, 계산 효율성에 영향을 미친다. 텐서 병렬화는 데이터 병렬화만으로는 도달할 수 없는 메모리와 계산 효율성을 확장하는 데 사용된다.
Pipeline Model Parallelism 파이프라인 모델 병렬화는 모델의 레이어를 병렬 처리 가능한 단계로 분할한다. 한 단계가 micro-batch의 전방 전파를 완료하면, 활성화 메모리는 다음 단계로 전송된다. 그리고 다음 단계가 backward propagation를 완료하면 gradient는 backward로 전송된다. 병렬 계산을 유지하기 위해 여러 micro-batch가 동시에 처리되어야 한다.
Memory Efficiency: 파이프라인 병렬화는 파이프라인 단계 수에 비례해 메모리를 줄여 작업자 수에 따라 모델 크기를 선형적으로 확장한다. 하지만 각 레이어의 활성화에 대한 메모리는 줄이지 않으며, 각 작업자는 처리 중인 모든 micro-batch의 활성화를 저장해야 한다. forward와 backward propagation를 번갈아 수행하는 1F1B 파이프라인 일정을 사용하며, 이 방식의 장점은 처리 중인 micro-batch 수가 파이프라인 단계 수로 제한되고, 전체 학습 배치의 micro-batch 수로 제한되지 않는다는 것이다.
Compute Efficiency: 파이프라인 병렬화는 파이프라인 단계 사이에서만 활성화를 통신하므로 통신 오버헤드가 가장 작다. 하지만 이 방법은 모델의 깊이에 의해 한계가 있으며, 파이프라인 차원을 늘릴수록 계산 효율성이 감소한다. 또한, 각 단계가 로드 밸런싱되어야 높은 효율성을 얻을 수 있다.
파이프라인 병렬화는 학습 배치의 시작과 끝에서 파이프라인을 채우고 비우는 과정에서 버블 오버헤드를 유발한다. 이 오버헤드의 크기는 파이프라인 병렬화로 인한 속도 향상을 제한하며, 이 향상 가능 비율(또는 병렬 효율성)은 파이프라인 단계 수와 총 micro-batch 수에 따라 달라진다.
$$ \text{efficiency} = {{\text{MB}\over{\text{MB} + \text{PP} − 1}}} $$
micro-batch 수가 파이프라인 단계 수의 4배나 8배일 때, 파이프라인은 각각 81%, 90%의 병렬 효율성을 보인다.
기존의 병렬화 기법 중 어느 것도 수백억 개의 parameter를 가진 모델 학습의 모든 도전을 해결할 수 없다. 하지만 각 기법은 자신만의 장점이 있어 상호 보완적으로 사용될 수 있다. 이를 위해, 계산과 메모리 효율성을 동시에 해결하는 데이터, 텐서, 파이프라인 병렬화의 조합인 3D 병렬화를 사용한다.
Software System — 3D Parallelism with DeepSpeed and Megatron
DeepSpeed의 파이프라인과 데이터 병렬화, 그리고 Megatron의 텐서 슬라이싱을 결합하여 유연한 3D 병렬화를 구현한다. 여기서 데이터, 텐서, 파이프라인 병렬화는 각각 메모리와 계산 효율성 향상에 특별한 역할을 한다.
Memory Efficiency: transformer block은 파이프라인 단계로 나눠지고, 각 단계의 블록은 텐서 병렬화를 통해 더 세분화된다. 이 2D 방식은 가중치, 기울기, 최적화 상태, 활성화의 메모리 사용량을 줄인다. 그러나 계산 효율성을 유지하면서 모델을 무한히 분할할 수는 없다.
Compute Efficiency: 학습을 가속화하기 위해 데이터 병렬화를 사용하여 GPU 수를 크게 늘린다. 예를 들어, 530B 개 parameter 모델 복제본은 280개의 NVIDIA A100 GPU에 분산되며, 노드 내에서 8-way tensor-slicing, 노드 간에 35-way 파이프라인 병렬화를 사용한다. 그 후 데이터 병렬화로 수천 개의 GPU로 더 확장한다.
3D 병렬화는 토폴로지 인식 매핑을 통해 최적화되어 모든 병렬화의 통신 오버헤드를 최소화하며, 이는 특히 데이터 병렬화에 큰 영향을 미친다. 이 매핑 방법은 대규모에서 뛰어난 계산 효율성을 달성하는데 중요하다.
Topology-Aware 3D Mapping
병렬화의 각 축이 작업자들에게 신중하게 할당되어 두 가지 주요 구조적 특성을 활용하여 계산 효율성을 극대화한다.
Mapping for Bandwidth 노드 내 통신은 노드 간 통신보다 대역폭이 높다. 따라서 통신 볼륨이 큰 병렬 그룹을 동일 노드에 우선 배치한다. 텐서 병렬화는 가장 큰 통신 오버헤드를 가지므로, 이 작업자들을 노드 내에 배치한다. 가능하면 데이터 병렬 작업자도 노드 내에 배치하여 기울기 통신을 가속화하며, 그렇지 않으면 가까운 노드에 매핑한다. 파이프라인 병렬화는 낮은 통신 볼륨을 가지므로, 통신 대역폭에 제한 없이 노드 간에 단계를 배치할 수 있다.
Bandwidth Amplification 파이프라인 및 텐서 병렬화가 증가함에 따라 각 데이터 병렬 그룹의 기울기 통신 볼륨은 선형적으로 줄어든다. 이로 인해 순수 데이터 병렬화의 전 통신 볼륨이 감소하며, 각 데이터 병렬 그룹이 더욱역화된 작업자들 사이에서 독립적이고 병렬적인신을 수행하게 된다. 결과적으로, 통신 볼륨의 감소와 지역성 및 병렬성의 증가가 결합하여 데이터 병렬 통신의 효과적인 대역폭이 증폭된다.
Hardware System
모델 학습은 NVIDIA의 Selene 슈퍼컴퓨터에서 16비트 bfloat를 사용한 mixed precision으로 진행된다. 각 클러스터 노드는 NVLink와 NVSwitch로 연결된 8개의 NVIDIA 80-GB A100 GPU를 가지고 있다. 노드들은 팻트리 토폴로지로 연결되어 efficient all-reduce 통신을 가능하게 하며, 고성능 데이터 액세스 및 저장을 위한 공유 병렬 파일 시스템을 사용한다. A100 GPU의 피크 처리량은 312 테라FLOP/s로, 피크 16비트 정밀도 성능의 총합은 1.4 엑사FLOP/s이다.
System Performance Evaluation
530B 개의 parameter 모델에 대해 Selene의 280, 350, 420개의 DGX A100 서버에서 배치 크기 1920을 사용했을 때, 시스템의 종단간 처리량은 각각 60.1초, 50.2초, 44.4초의 반복 시간이었고, 이는 각각 GPU 당 126, 121, 113 테라FLOP/s에 해당한다.
Training Dataset and Model Configuration
이 섹션에서는 실험에서 사용된 학습 데이터셋, 전처리 기법, 그리고 모델과 hyperparameter에 대한 세부 사항을 제시한다.
Training Dataset and Preprocessing
Common Crawl (CC) 등의 웹 스냅샷 리소스는 언어 데이터의 원천으로 활용된다. 이 데이터는 풍부하지만, 품질이 좋은 데이터를 선택하기 위한 신중한 전처리 과정이 필요하다. 필터링되지 않은 CC 데이터의 품질은 선별된 데이터셋보다 낮기 때문에, 품질을 향상시키는 조치가 필요하다. 다양한 학습 세트를 수집하는 최근 연구를 활용하고, 이전에 대형 언어 모델 학습에 사용된 RealNews와 CC-Stories도 포함하여 학습 데이터셋을 구축하였다.
Training Dataset
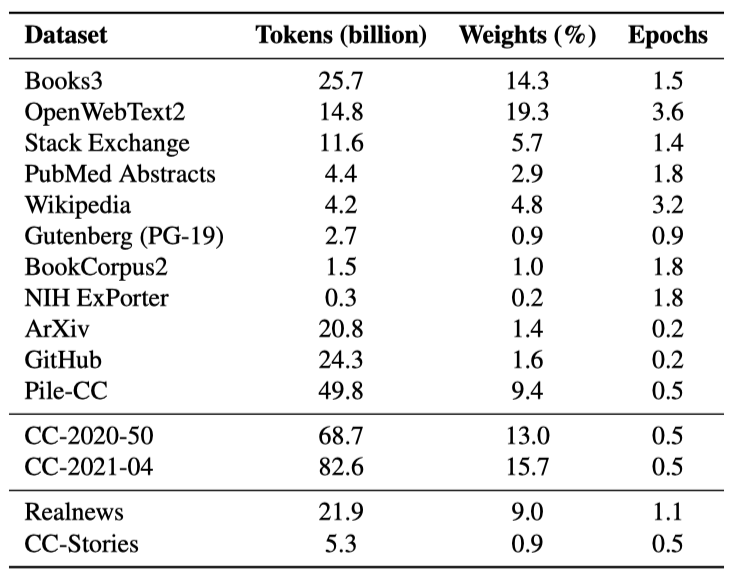
이 연구는 이전 작업을 기반으로 했으며, 처음에는 The Pile의 고품질 부분집합을 선택하였다. 그 후, 두 개의 전체 CC 스냅샷을 다운로드하고 필터링했다. 이 과정에서는 원시 HTML에서 텍스트를 추출하고, 고품질 데이터에 학습된 분류기를 사용해 문서를 점수 매기는 등의 단계를 거쳤다. 마지막으로, 중복과 거의 중복된 문서를 제거하고, downstream 작업 데이터를 제거하기 위해 n-gram 기반 필터링을 사용하였다.
Pre-Processing Details
Common Crawl: Common Crawl은 대규모 데이터를 포함하며, 2020-50과 2021-04 두 스냅샷을 처리하여 약 150B 개의 학습 데이터를 획득하려고 했다. 이 과정의 첫 단계는 언어 감지와 원시 HTML에서 텍스트 추출이었고, 이를 위해 pycld2와 jusText 라이브러리를 사용하였다. 이 단계를 거치면서 문서의 수가 크게 줄었으며, 문서 중 약 25%만이 영어로 분류되고 비어 있지 않은 본문을 가지게 되었다.
고품질 문서를 선택하기 위해, 2-gram fastText 분류기를 학습시켰다. 긍정적인 문서는 OpenWebText2, Wikipedia, Books3에서 무작위로 선택하였고, 부정적인 문서는 텍스트 추출 결과에서 무작위로 샘플링하였다. 이 문서들 중 10%를 분류기 평가를 위해 두었고, 학습 후 90.3%의 정확도를 달성하였다. 분류기는 각 문서에 적용되었고, 긍정 레이블의 확률이 문서의 점수로 사용되었다.
위 과정에서 생성된 점수를 이용해, $\alpha = 3$인 Pareto 분포로 문서를 필터링하였다. 이로 인해 텍스트의 약 80%가 필터링되었다. $\alpha$ 선택이 이전 연구보다 낮았지만, 데이터 검사 결과 허용 가능한 품질이었으며, $\alpha = 3$ 사용으로 원래의 토큰 목표를 약간 초과하여 달성하였다.
Other Datasets: Common Crawl 데이터 외에도, 우리는 The Pile의 여러 데이터셋과 Megatron 훈련에 사용된 CC-Stories와 RealNews 데이터셋을 활용하였다.
Fuzzy Document Deduplication: 인터넷 콘텐츠는 대부분 문서간에 중복되며, Common Crawl 스냅샷에서 스크랩된 URL도 고유하지 않다. 선택한 스냅샷 중 53%와 34%의 문서는 이전에 보지 못한 새로운 URL에서 가져온 것이었다. 또한, OpenWebText2나 Wikipedia 같은 다른 데이터셋의 콘텐츠도 Common Crawl에 존재할 가능성이 높다.
정확한 일치 중복 제거는 계산 비용이 많이 들어, 우리는 퍼지 중복 제거 방법을 선택하였다. 해싱 벡터화기를 이용해 문서를 벡터화하고, 최소 해시를 계산한 뒤, 지역 민감 해싱을 통해 잠재적 중복을 찾았다. 이 과정에서 Jaccard 유사도가 ≥ 0.8인 문서들이 같은 LSH 버킷에 들어갈 확률을 높였으며, 이를 위해 총 260개의 해시 함수를 가진 20개의 밴드를 사용하였다.
LSH 수행 후, 각 버킷을 처리해 모든 쌍의 Jaccard 유사도를 근사 계산하여 거짓 긍정 중복을 제거하였다. 이 과정은 무작위 문서를 샘플링하고, 그 문서와 버킷 내의 다른 문서들과의 유사도를 계산해 임계값 이상인 문서를 제거하는 것이다. 이후 희소 문서 그래프를 구성해 연결된 구성 요소를 찾았고, 각 구성 요소에서 하나의 대표 문서를 선택하였다. 데이터셋의 품질이 다양하므로, 대표 문서 선택 시 우선 순위를 정의하였고, 가장 높은 우선 순위의 데이터셋에서 처음 만난 문서를 최종적으로 유지하였다.
Additional Processing: 학습 데이터셋에서 Ftfy 라이브러리를 사용해 유니코드 텍스트를 정제하고, langdetect 라이브러리로 영어가 아니거나, 글자수가 512 미만인 문서를 제거하였다. 또한 “javascript"라는 단어가 포함되고 256자 미만인 문서도 제거하였다.
Downstream Task Data Removal: 학습 데이터셋에서 n-gram을 사용해 downstream 작업에 있는 텍스트를 제거하였다. 작업 문서와 학습 문서 사이에 n-gram 일치가 있으면, n-gram과 양쪽 200자를 제거해 학습 문서를 두 부분으로 나누었다. 200자 미만이거나 10회 이상 분할된 학습 문서는 제거하였다. 이 과정에서 총 319,781,622개의 문서 중 35,988개 문서가 분할되었고, 1,109개 문서가 제거되었다.
Blending Datasets: 샘플링 가중치에 따라 데이터셋을 이질적인 배치로 혼합하였다. 그러나 이로 인해 각 배치의 샘플이 균등하게 분할되지 않았다. 이를 해결하기 위해, 각 데이터셋의 과다 샘플링과 부족 샘플링을 추적하여 각 단계에서 배치 구성을 약간 조정하였다. 이렇게 함으로써 샘플 분포를 선택한 혼합 가중치 분포에 가깝게 유지하였다.
Model and Training Process
왼쪽에서 오른쪽으로 autoregressive, generative transformer-based 언어 모델인 transformer decoder의 아키텍처를 사용하여 이를 530B 개의 parameter로 확장하였다. 시퀀스 길이는 2048, 글로벌 배치 크기는 1920이며, 8-way 텐서와 35-way 파이프라인 병렬성을 사용하였다. learning rate는 5.0e-5로 설정하였고, 선형 학습률 워밍업을 위해 10억 토큰을 사용하였다. Adam 최적화 기법을 사용하였고, 가중치 초기화를 위해 평균 0, 표준 편차 4.0e-3인 정규 분포를 사용하였다. 학습 데이터셋은 339B 토큰으로 구성되어 있으며, 15개의 학습 데이터셋을 혼합하여 270B 토큰에 대해 학습시켰다. 또한, 데이터의 2%를 검증을 위해 분리하였다.
MT-NLG와 같은 대형 모델에서 학습 안정성은 핵심적인 도전 과제이다. learning rate, 가중치 초기화, 그리고 Adam optimizer parameter가 모델 안정성에 크게 영향을 미친다는 것을 발견하였다. 더 높은 learning rate는 모델의 불안정성을 증가시키며, 가중치 초기화에 대해 높은 분산을 사용하면 모델이 수렴하지 못함을 확인하였다. 이를 해결하기 위해, 가중치 초기화는 표준편차로 $\sqrt{1 / (3 * H))}$를 사용하였고, 학습 손실의 급증을 줄이기 위해 β2 값을 0.99에서 줄였다.
Results and Achievements
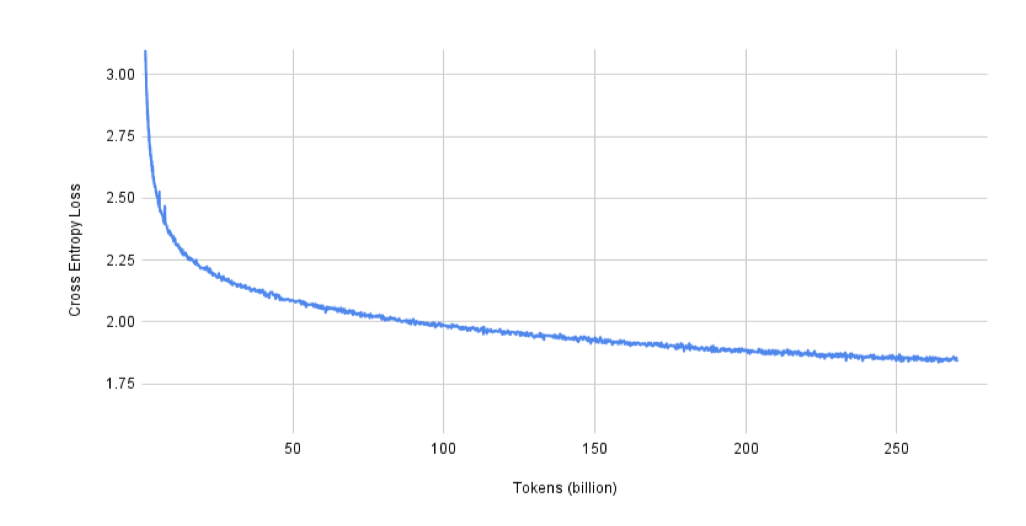
언어 모델 성능이 학습 도중 어떻게 향상되는지를 이해하기 위해, MT-NLG의 검증 손실 곡선을 제시한다. 검증 데이터셋은 5.5B 토큰으로 구성되어 있으므로, 전체 데이터셋으로 손실을 측정하는 것은 비효율적이다. 그래서 검증 데이터셋의 시퀀스를 섞고, 각 손실 계산 시에는 글로벌 배치 크기가 1920인 네 번의 반복을 실행하여 총 1,600만 토큰을 평가하게 된다.
모델이 처음 10억 토큰에 대해 학습된 후의 검증 손실은 3.15이며, 배치 크기를 처음 12B 토큰 동안 선형적으로 증가시킨 뒤의 손실은 2.31이다. 그리고 모델이 목표 토큰 수인 270B에 도달하면, 검증 손실은 1.85가 된다.
모델의 품질을 평가하기 위해, 이전 연구와 유사한 zero/one/few-shot 평가 방식을 사용하였다. 이 평가는 오픈 소스 프로젝트인 lm-evaluation-harness를 기반으로 하며, 각 작업에 맞게 조정하였습니다. few-shot 실험의 경우, 최적의 shot 수를 찾는 검색 없이 이전 연구에서 제안된 설정을 그대로 사용하였고, 이 설정은 대부분의 경우에 충분히 잘 수행되었다.
평가를 종합적으로 하기 위해, 완성 예측, 독해 이해, 상식 추론, 자연어 추론, 단어 의미 중의성 해소와 같은 다양한 카테고리에서 여덟 가지 작업을 선택하였다. 이 작업들에 대한 사전 학습된 대형 언어 모델의 성능을 이전 연구와 비교하였고, “specialist” 모델과 “generalist” 모델 사이의 차이를 이해하기 위해, 적용 가능한 경우 감독 기준선을 제공하였다.
많은 평가 작업은 모델을 사용하여 후보 완성 문장을 점수화하는 것을 포함한다. 여기서 가능성이라는 용어는, 특별히 언급하지 않는 한, 프롬프트에 따른 후보 답변의 확률을 토큰 수로 정규화한 것을 의미한다.
Completion Prediction
LAMBADA LAMBADA 데이터셋은 전체 문맥이 주어졌을 때 인간이 마지막 단어를 쉽게 추측할 수 있도록 선택된 서술 문단들이다. 하지만 마지막 문장만 주어진다면 답을 할 수 없다. 이 작업은 언어 모델이 단순한 통계 패턴이나 국소적 문맥보다는 더 넓은 담화 문맥을 이해하고 유지하는 능력을 테스트한다.
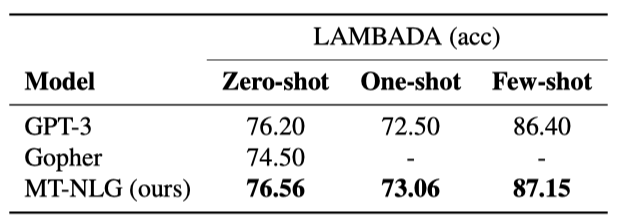
이 작업을 평가할 때, 각 패시지를 입력으로 제공하고 모델이 탐욕적 생성을 통해 마지막 단어를 정확히 생성할 수 있는지 확인한다. 하지만 one-shot/few-shot 평가에서는 문장의 마지막 단어를 예측하는 것이 목표임을 더 잘 알려주기 위해 클로즈 스타일의 프롬프트 형식을 사용하였다. 이 방법은 few-shot 설정에서 성능을 크게 향상시키지만, one-shot 성능은 약간 저하되었다. LAMBADA 테스트 세트에서 모든 설정에 state-of-the-arts를 달성하였다.
Reading Comprehension
이 섹션에서는 독해를 위한 MT-NLG의 평가에 대해 논의한다. 우리는 다른 스타일의 질문을 대상으로 하는 두 개의 데이터셋을 선택하였고, 평가 시에 그들에 대한 예시의 수를 늘렸을 때 매우 다른 추세를 발견하였다.
RACE RACE는 영어 시험에서 추출한 패시지와 질문들로 구성된 독해력 데이터셋이다. 각 예시는 기사와 질문-답변 쌍으로 이루어져 있다. 프롬프트 생성을 위해 기사, 질문, 답변 텍스트에 각각 “Article: “, “Question: “, “Answer: " 태그를 붙이고, 이들을 연결한다. 마지막 질문의 실제 답변은 제외하고, 모델은 “Answer:” 후의 가능한 모든 답변을 점수화하여 가장 높은 점수를 받은 답변을 선택한다.
이 데이터셋에는 직접적인 질문과 클로즈 스타일의 질문 두 가지 유형이 있다. 두 질문 유형 모두 위에서 설명한 방식으로 동일하게 취급하며, 이는 기본적으로 사용되는 방식과 다르다. 또한, GPT-3를 따라서 특정 점수 기준을 사용하였고, 이를 통해 더 좋은 성능을 관찰하였다.
$$ {P(\text{completion} | \text{context})}\over{P(\text{completion} | \text{answer context})} $$
점수를 매기는 기준으로 사용하며, 이때 context는 전체 프롬프트이고, answer context는 “Answer:” 문자열이다. GPT-3와 비슷하게, length-normalized log-probability를 점수 기준으로 사용하는 것보다 RACE에서 더 좋은 성능을 보였다.
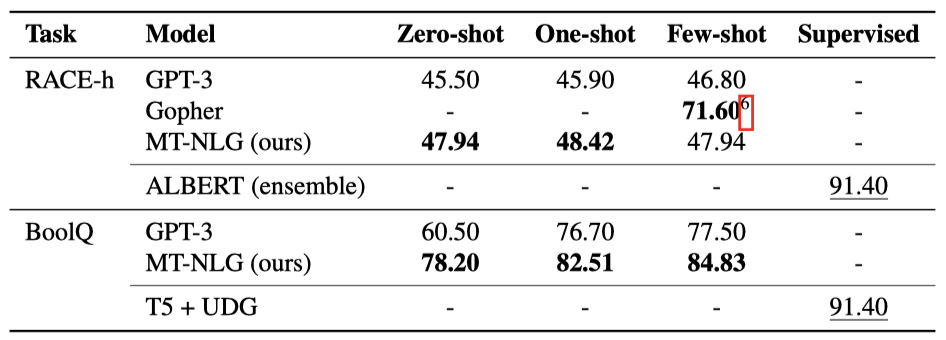
데이터셋은 어려운 문제와 중간 난이도의 문제를 대응하는 RACE-h와 RACE-m 두 하위 집합을 포함한다. 프롬프트에 더 많은 예시를 포함하더라도 성능 향상이 크지 않음을 확인하였다. 그러나 zero-shot 성능은 이미 GPT-3의 few-shot 성능을 +1.14% 초과한다.
RACE 데이터셋에서, ALBERT 앙상블이라는 지도 학습 모델이 91.4%의 높은 정확도를 보여주며, 이는 사전 학습된 언어 모델들의 결과보다 월등히 높다. 최근 연구는 사전 학습된 언어 모델과 지도 학습 모델 간의 차이를 줄였지만, 여전히 큰 차이가 있다.
BoolQ BoolQ은 yes/no 질문에 대한 데이터셋이다. 이에 대한 답변은 위키백과 단락을 사용한다. 지원 단락, 질문, 그리고 답변을 연결하여 프롬프트를 만들고, 모델을 사용하여 “yes"와 “no"를 점수화한다. 가장 높은 점수를 얻은 옵션을 선택한다. 많은 예시가 포함된 프롬프트는 성능을 크게 향상시킬 수 있다. 이는 작업 프롬프트 형식이 모델에게 혼란스럽게 느껴질 수 있고, 주어진 예시가 모델을 패시지-질문-답변 형식을 따르도록 충분히 조건화하는 데 도움이 되기 때문이다.
BoolQ 작업에서 T5 + UDG 모델이 91.4%의 정확도를 보여주며 최상의 성능을 보였다. 그러나 RACE-h와 비교해봤을 때, 감독된 모델과 사전 학습된 언어 모델 사이의 성능 차이는 크지 않았다. 특히, MT-NLG 모델은 이 성능 차이를 더욱 줄일 수 있었다.
Commonsense Reasoning
사전 학습된 언어 모델이 훈련 데이터에서 얼마나 많은 세계 지식을 유지하는지를 파악하기 위해, 상식 추론 관련 작업 두 가지에서 모델을 평가했다. 이를 위해 UNICORN 이라는 감독 기준선과 3개의 데이터셋을 비교했다.
Winogrande Winogrande는 Winograd 스키마 챌린지를 더 크고 어렵게 만들려는 데이터셋이다. 이 작업은 통계적 언어 모델링만으로는 해결할 수 없는 대명사 해결 문제로, 이를 해결하기 위해서는 기본적인 사건과 객체에 대한 상식 지식이 필요하다.
이전 연구의 평가 방법을 적용해, 실제 명사를 모호한 대명사로 바꾸고 문장의 가능성을 평가했다. 가장 가능성이 높은 대명사 치환을 모델의 답으로 선택했다. 결과적으로, zero-shot 정확도에서는 GPT-3에 비해 크게 향상되었지만, few-shot에서는 그 차이가 줄어들었다. 한 예시만 있을 때보다 few-shot 설정에서 모델의 성능이 크게 향상되었고, 이는 상식 추론 성능이 shot 수와 잘 맞춰진다는 일반적인 추세를 보여준다. 이는 독해 이해에서 보는 추세와는 다르다.
HellaSWAG HellaSWAG은 목표와 후속 행동을 선택하는 상식 추론 데이터셋이다. Wikihow와 Activitynet Captions에서 예시를 추출하였다. 평가는 목표에 따른 각 후보 답변의 가능성을 평가하고 가장 가능성이 높은 답변을 선택하는 방식으로 이루어졌다. 결과적으로, 모든 설정에서 GPT-3에 비해 크게 개선되었고, zero-shot 성능이 GPT-3의 few-shot을 넘어섰다. zero-shot에서 one-shot으로 이동하는 것은 성능을 크게 향상시키지 않았지만, few-shot에서 더 많은 예시를 포함시키면 성능이 크게 향상되었다.
PiQA PiQA는 물리적 상호작용 이해를 위한 이진 선택형 질문 응답 데이터셋이다. 이는 일상 활동 완료 방법에 대한 질문을 제시하고, 모델은 두 가지 후보 답변 중 하나를 선택하는 작업을 한다.
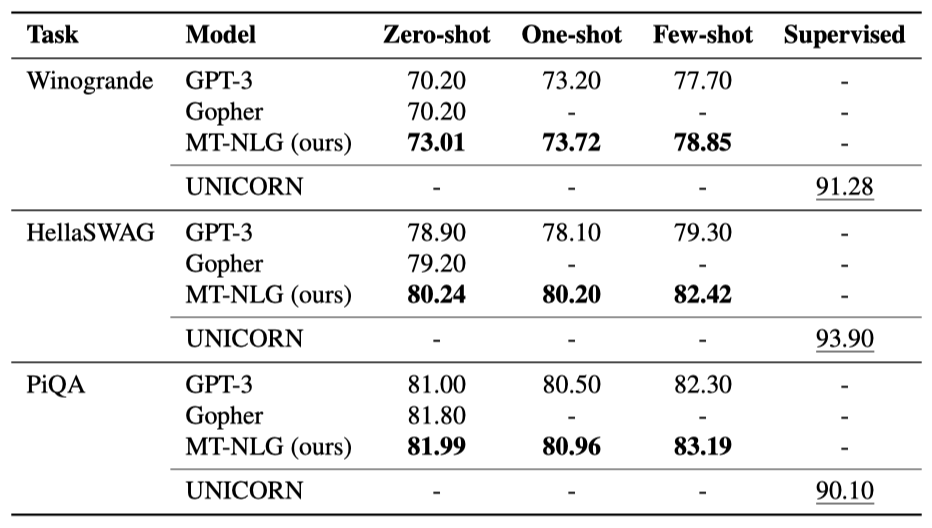
PiQA에서는 질문/목표를 모델에 제시하고 두 가지 행동에 대한 후보 문장의 가능성을 평가하여 더 높은 가능성을 가진 옵션을 선택한다. 결과적으로, one-shot 성능은 zero-shot에 비해 떨어지지만, few-shot 성능은 적절하게 향상되는 것을 확인하였다.
Natural Language Inference
이 섹션에서는 모델이 자연어 추론 (NLI) 작업에서 어떻게 평가되는지에 대해 논의한다.
ANLI ANLI는 어려운 NLI 문제 집합을 만들기 위한 데이터셋이다. 질문-답변 형식으로 NLI 문제를 재구성하고, 가장 가능성이 높은 옵션을 모델의 답변으로 선택하였다. 결과적으로, 하나의 예시만으로도 모델의 성능이 향상되었지만, 추가 예시를 포함한 few-shot 설정에서는 성능 향상이 없었다. 이는 추가 예시가 내용적으로 관련이 없어 모델에게 새로운 지식을 제공하지 않기 때문일 수 있다. ANLI에서는 InfoBERT를 기준으로 비교하였다.
HANS HANS는 모델이 NLP 데이터의 표면적인 문법적 휴리스틱을 이용하는 경향성을 평가하기 위한 NLI 데이터셋이다. 이는 특정 문법적 및 구문적 구조의 템플릿에서 예시를 생성하는 환경을 제공한다. 작업 형식은 ANLI와 유사하며, NLI 문제를 이진 질문 응답 형식으로 변환한다. 이 작업은 lm-evaluation-harness의 기존 작업들 중에서 평가에 포함시켰다.
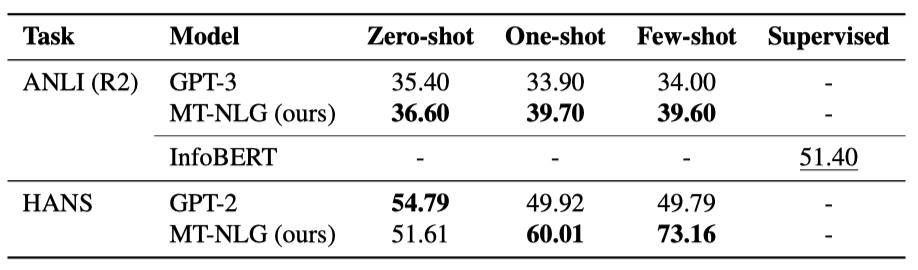
HANS 데이터셋을 주로 few-shot 학습에서 모델의 행동을 분석하는 도구로 사용한다. 이전에 이 데이터셋에 대한 프롬프트 기반 생성 기준선은 없어, 비교를 위해 GPT-2를 평가하였다. zero-shot 성능은 모델의 고유한 편향에 의해 주도되며, 충분히 학습된 큰 모델은 컨텍스트 내 예시를 활용해 성능을 크게 향상시킬 수 있다. 반면, 약한 모델은 추가적인 컨텍스트 내 예시에 혼란스러울 수 있으며, GPT-2는 무작위 선택보다 훨씬 더 좋지 않았다.
Word Sense Disambiguation
WiC Word-in-Context 데이터셋은 맥락 속에서 다의어의 의도된 의미를 파악하는 작업을 제시한다. 이 작업은 두 문장에서 동일한 다의어가 같은 의미를 가지고 있는지 아닌지를 식별하는 것이다.
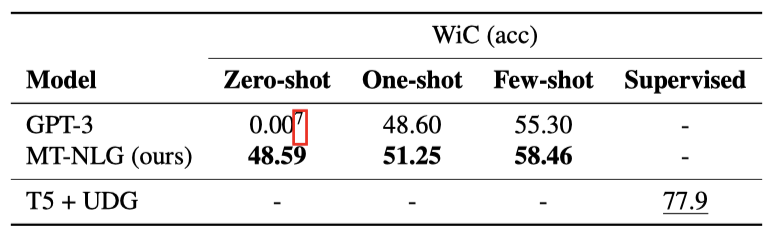
이 작업에서는 문제를 질문 응답 형식으로 변환하여 zero-shot/few-shot 평가를 수행한다. “yes"와 “no"의 가능성을 조사하고, 더 높은 가능성을 가진 답변을 선택한다. 결과는 zero-shot에서는 모델의 성능이 우연보다 약간 낮지만, few-shot으로 전환하면 우연을 초과한다. 반면, 감독된 T5 + UDG 모델은 우연 수준을 크게 초과한다.
Exploring Social Biases
Introducing the Challenge of Social Bias in NLP Models
자연어 모델은 다양한 검열되지 않은 소스에서 수집된 대량의 데이터셋을 학습한다. 하지만 인터넷 상의 커뮤니케이션과 글쓰기는 심한 편향을 포함하고 있다. 이러한 편향은 모델이 데이터를 학습하면서 배울 수 있으며, 이는 대규모 언어 모델의 활용을 제한하는 요인이 된다.
이 논문의 주요 초점이 아니지만, 이러한 편향을 완화하기 위해 여러 분야에서 진행 중인 연구가 있다는 점을 언급하고자 한다.
a) Training set filtering – 학습 데이터셋의 요소들이 분석되고, 편향의 증거를 보이는 요소들이 학습 데이터에서 제거된다. b) Training set modification – 학습 데이터셋의 요소들이 성별이나 인종과 같이 주제와 중립적이어야 하는 변수에 대해 무작위화된다. c) Prompt engineering – 각 쿼리에 대한 모델의 입력이 편향으로부터 모델을 이끌어내기 위해 수정된다. d) Fine tuning – 학습된 모델이 편향된 경향을 잊도록 재훈련된다. e) Output steering – 추론 절차에 필터링 단계가 추가되어 출력값을 재조정하고 편향된 응답으로부터 출력을 이끌어낸다.
이 연구에서는 편향에 대한 대응책 없이 기본 모델을 학습시켰다. 하지만 이런 모델이 대응책 없이 실제 환경에 배포되어선 안된다고 강조하며, MT-NLG 모델도 마찬가지라고 믿는다. 이 연구가 편향에 대한 대응책 연구를 지원하고, 이러한 대응책을 적용한 미래 배포의 시작점이 될 것이라 기대하고 있다. 또한, 최첨단 대규모 언어 모델 학습과 편향 대응책을 결합한 미래의 연구가 강력하면서도 결과에서의 편향을 최소화하는 모델을 만들어 낼 것이라 확신한다.
저희는 성별, 인종, 종교 등과 관련된 편향에 대한 초기 분석을 제시한다. 다양한 차원에서 편향을 평가하기 위한 연관성 테스트, 공존 분석, 감정 분석 등을 수행하였다. 이 부분은 모델의 편향에 관한 문제를 문서화하고 정량화하는 것으로, 향후에 이러한 문제를 해결해야 한다.
Gender and Occupation Analysis
모델이 학습 데이터의 사회적 편향을 학습하는지 확인하기 위해 성별과 직업 사이의 연관성을 조사하였다. 이전 연구를 따라 323개의 직업 목록을 사용하였고, “The { occupation } was a { gender identifier }“라는 문장 템플릿을 이용하였다. 여기서 성별 식별자로는 male, man, female, woman을 사용하였다.
특정 직업에 대해, 모델이 다른 성별 식별자에 할당하는 확률을 계산하였다. 남성 식별자가 여성 식별자보다 높은 확률을 가진 경우가 전체의 78%로, 이 결과는 모델이 일반적으로 남성 식별자에 편향되어 있다는 것을 보여준다.
평균 직업 편향 점수를 계산한다. 이는 모델이 특정 성별을 주어진 직업과 연관시키는 경향이 있는지를 측정한다. 직업 편향 점수는 다음과 같이 계산된다.
$$ {{1}\over{N_{OCC}}} \sum_{OCC} (log(P(\text{female identifier}|\text{prompt})) - log(P(\text{male identifier}|\text{prompt}))) $$
직업과 성별 식별자 사이의 편향을 측정하는 점수에서, 0은 편향이 없음을, 양수는 여성 식별자에, 음수는 남성 식별자에 편향이 있음을 나타낸다. 평균 편향 점수는 모든 직업에 대한 남성과 여성 식별자의 확률 차이를 보여준다. 모델의 평균 편향 점수는 -0.77로, 이는 더 많은 직업에 대해 남성 식별자를 선호한다는 것을 나타낸다.
GPT-3의 경우 남성 식별자가 여성 식별자보다 높은 확률을 가진 직업의 비율이 83%이고 평균 편향 점수는 -1.11이다. 이 결과는 저희의 결과와 직접적으로 비교할 수는 없지만, 이 모델이 유사한 데이터에서 유사한 방식으로 학습된 다른 모델보다 특별히 더 편향되거나 덜 편향되지 않음을 나타낸다. 이는 이 모델을 사용할 때 편향을 통제하기 위해 더 많은 노력이 필요함을 나타낸다.
Adjective Co-Occurrence Analysis

성별, 인종, 종교와 관련된 프롬프트와 공존하는 형용사를 분석한다. 각 프롬프트에 대해 800개의 생성물을 샘플링하고, 이들을 생성할 때 온도 1.0과 top p 값 0.9를 사용한다. 프롬프트는 “{ gender/ethnicity identifier } template” 형식으로 생성되며, 예시로는 “The woman was regarded as"와 “The Black person would be described as"가 있다.
생성된 텍스트를 문장으로 분할하고, 주어진 식별자를 설명하는 것이 첫 번째 문장뿐이라는 것을 확인한 후, 분석을 위해 첫 번째 문장만 고려한다(그리고 다음 문장들은 일반적으로 무작위의 사건이나 이야기를 설명한다). 각 성별과 인종의 식별자와 공존하는 가장 빈번한 100개의 형용사를 분석한다.
공존 분석을 위해 고려해야 할 두 가지 중요한 요소가 있다:
a) 개별 단어의 순서적 위치는 중요하며, 높은 위치와 낮은 빈도는 특정 스테레오타입이나 공격적인 형용사에 대한 편향이 낮다는 것을 나타낸다. b) 개별 형용사의 스테레오타입이나 공격적인 내용의 정도는 중요하며, 일부 형용사는 중립적인 반면, 다른 일부는 매우 공격적일 수 있다.
공존 분석은 특정 식별자와 함께 나타나는 단어의 빈도에 대해 이해를 제공하지만, 각 형용사와 관련된 감정이나 맥락은 고려하지 못한다는 점을 강조하고 싶다.

Gender Analysis 성별에 대해 가장 빈번한 100개의 형용사 중 80개가 완전히 같았다. 모델은 대체로 동일한 단어 세트를 사용하지만, 특별히 주목할 만한 예외도 있다.

모델의 편향을 강조하기 위해, 각 성별에 대해 가장 빈도가 높은 독특한 10개의 단어를 제시한다. 그러나 이것은 이전에 논의된 비편향성을 감추는 것이다. 모델은 학습 데이터의 성별 스테레오타입을 따르며, 예를 들어 여성 식별자에는 외모 관련 형용사를, 남성 식별자에는 더 다양한 형용사를 사용한다. 그러나 스테레오타입적인 독특한 형용사의 순서적 위치는 상대적으로 높아서(즉, 빈도가 낮아서) 이는 좋은 속성이다.

Ethnicity Analysis 인종에 대한 형용사 공존 분석 결과, 백인 인종과 관련된 긍정적인 형용사가 더 많이 관찰되었고, 다른 인종과는 매우 공격적인 형용사가 관련되어 있음을 발견하였다. 모델은 각 인종과 관련된 공격적인 스테레오타입을 보여주며, 독특한 형용사의 순서적 위치는 성별보다 더 높았다.
이 결과는 실제 적용에 부적합하며, NLP 모델은 편향 방지 대책을 사용해야 함을 확인하였다. 이러한 대책을 적용한 상태에서 테스트를 반복하고 결과의 개선을 정량적으로 검증하는 것을 기대하고 있다.

Religion Analysis 종교에 대해, 성별 및 인종과 비슷한 방식으로 공존하는 단어를 분석하였다. 각 6개의 종교에 대해 더 높은 빈도로 공존하는 가장 독특한 10개의 단어를 확인했으며, 주로 특정 종교에 대해 더 높은 빈도로 사용된 부정적인 단어는 관찰되지 않았다.
Sentiment Analysis
편향을 측정하기 위해 추가적으로 감성 분석을 사용하며, 이는 인종이 가장 강한 편향 문제를 보여주었기 때문에 인종에 초점을 맞추었다.
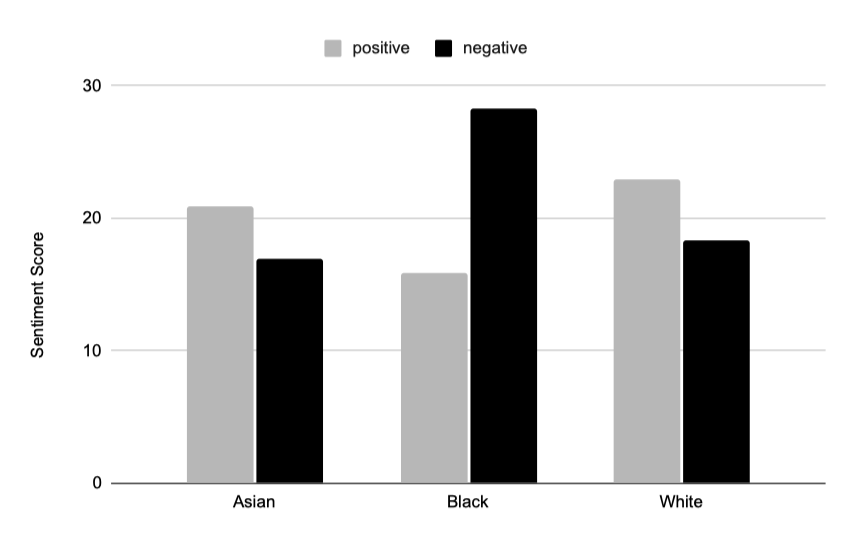
공존하는 모든 단어의 감정을 분석하여 각 단어에 대해 SentiWordNet을 사용해 긍정적 및 부정적 점수를 측정하고, 이를 평균낸 결과를 제시한다.
흑인 인종에 대해 부정적 감정 단어가 상당히 높게, 반면 긍정적 감정 단어는 낮게 공존하는 것을 확인하였다. 아시아인과 백인 인종의 감정은 서로 비슷했다. 결과에서 드러난 감정 편향은 심각하며, 이는 자연어 학습에 편향 방지 대책이 필요하다는 것을 확인한다.
Discussion
MT-NLG와 같은 큰 NLP 모델들은 대량의 비구조화된 정보를 흡수하고 쉽게 접근 가능하게 만드는 놀라운 능력을 보여주었다. 그러나, 그들이 학습을 위해 받은 정보에 내재된 편향을 흡수하는 문제도 보여주었다.
학습 세트의 편향에 대응하는 대책 없이 학습된 모델의 편향을 검토하기 위해 이 섹션을 포함하였다. 이전 연구 결과를 바탕으로 모델에 상당한 편향이 있을 것으로 예상했고, 이는 결과에서 확인되었다. 적절한 대책 없이 학습된 모델은 그대로 사용되어서는 안된다.
Natural Language Understanding and In-Context Learning
큰 규모의 변환기 기반 언어 모델의 핵심 언어 이해 능력을 평가하려면, 언어의 체계성을 파악하는 능력이 필수적이다. 이 섹션에서는 이를 HANS 데이터셋을 사용하여 시도하며, 다른 NLP 벤치마크의 한계에 대한 논의로 시작한다.
Limitations of NLP benchmarks
transformer 기반의 사전 학습된 언어 모델들이 최근 NLP에서 주목받고 있다. 이런 모델들은 다양한 작업에서 뛰어난 성능을 보여주며, 일부에서는 인간 수준을 초과하기도 한다. 그러나, 최근의 연구에서 이 모델들의 성능이 과대평가되었으며, 일반화가 잘 되지 않는다는 증거가 나타났다. 특히, 학습 데이터셋의 허위 상관관계를 이용하는 경향이 있다. 이는 모델의 학습 능력과 훈련 데이터셋의 제한성 때문이다. 결과적으로, 이 모델들은 높은 성능을 보이지만, 실제 자연 언어 이해 능력을 반영하지 못할 수 있다.
Brown et al. 은 대형 언어 모델의 정확한 평가와 과적합 문제 해결을 위해 few-shot 학습을 제안한다. 이 방법은 모든 학습이 입력 프롬프트에만 기반하므로, 작업 특정 데이터셋의 생성과 모델의 미세 조정을 회피할 수 있다. 따라서 이들 주장이 얼마나 타당한지 밝혀내는 것이 중요하다.
Evaluating Grasp of Language Systematicity
HANS 데이터셋은 언어 모델이 어휘 중복이나 공통 부분 수열 등 표면적인 요소가 아닌, 일관된 규칙을 사용하여 함축을 추론하는 능력을 평가하는데 사용된다. 이 데이터셋은 단순한 어휘를 사용하고, 각 예제는 “함축"과 “비함축” 레이블 외에도, 조사하려는 특정 문법/구문 구조에 대한 주석이 포함되어 있다.
Factors Affecting In-Context Learning
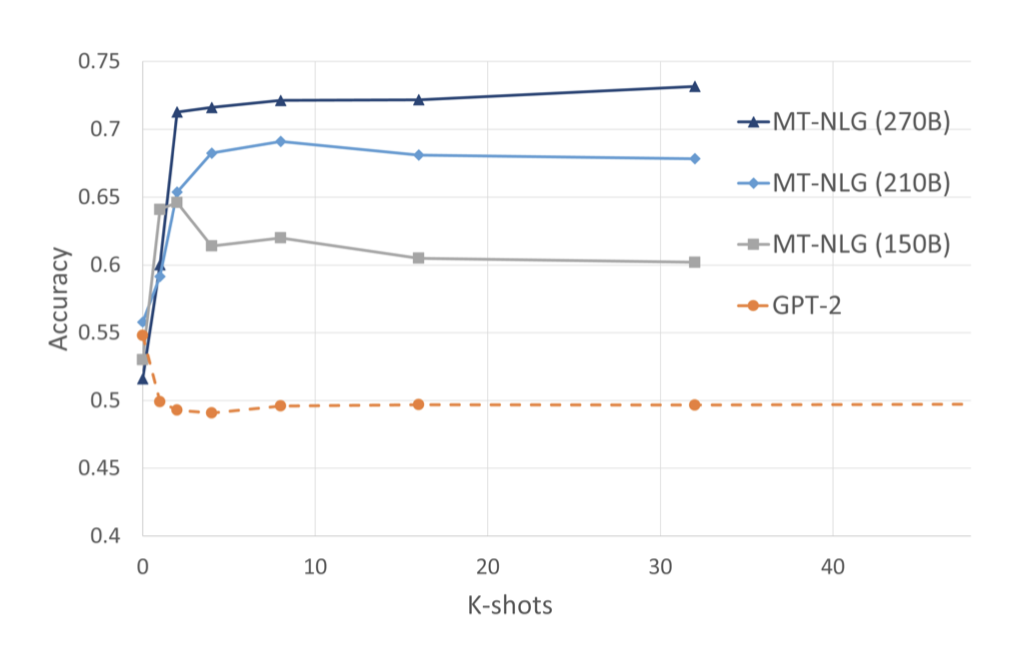
Model size and amount of training HANS 작업은 대형 언어 모델에게는 어려운 것으로 나타났지만, 인간에게는 비교적 쉬운 작업이다. 15억 개의 매개변수를 가진 GPT-2는 shot 예제의 수에 관계없이 랜덤 확률보다 성능이 좋지 않다. 반면, 530B 개의 parameter를 가진 모델 MTNLG는 구문 규칙을 성공적으로 활용할 수 있었다. 성능에 영향을 미치는 두 가지 중요한 요인은 autoregressive 사전 학습의 양과 프롬프트 예제의 수이다.
Number of Shots 작업을 해결하는 방법을 모델에게 이해시키기 위해, 먼저 몇 가지 예시를 보여주는 것이 중요하다는 것을 확인하였다. 대부분의 경우, 2개의 예시를 보여주었을 때 최고의 정확도를 보였다. 이러한 성능 향상은 초기 2-shot이 모델이 “True"와 “False” 중 하나를 예측할 확률을 70%에서 100%로 높이는 것에서 비롯된 것으로 보인다. 초기 2-shot은 또한 모델이 훈련 과정에서 생긴 편향을 조정하는 데 도움을 준다.
일부 데이터셋에서는 많은 수의 shot 예제가 도움이 될 수 있지만, 대부분의 경우에는 그 반대라는 것이 이전 연구에서 보고되었다. 관찰에 따르면, 가장 크고 잘 학습된 모델만이 처음 몇 번의 shot 이후에 추가적인 예제로부터 이익을 얻을 수 있었다. 추가 shot은 약한 모델에 혼란을 주며, 평가 중인 예제에 집중하는 데 방해가 될 수 있다는 추측을 하였다. 그러나 잘 학습된, 높은 용량의 모델에서는 자기 주의가 프롬프트 내에서 가장 관련성 있는 샘플과 평가된 샘플에 선택적으로 주의를 기울일 수 있었다.
Distribution of Shots 더 많은 shot 예제가 어떤 상황에서 도움이 될 수 있는지를 더 명확히 하기 위해, 두 가지 다른 설정에서의 평가를 반복하였다. 첫 번째 설정에서는, 평가 중인 예제와 다른 하위 케이스에서만 예제가 나오도록 했다. 두 번째 설정에서는, 하위 케이스별로 shot 예제를 제어하지 않았고, shot의 수가 증가함에 따라 모델이 평가 중인 예제와 같은 하위 케이스의 예제를 만날 확률이 증가하였다. shot 예제의 역할은 단지 작업 형식에 대한 지침을 제공하는 것이 아니라, 모델을 안내하는 샘플의 분포와 평가 샘플의 분포가 일치해야 최고의 성능을 얻을 수 있다는 것을 확인하였다. 이는 상황에 따른 학습이 “overfitting” 문제를 자동으로 피하지 못한다는 첫 번째 증거로, 더 큰 모델 규모와 더 많은 사전 학습이 상황에 따른 학습에 의존하는 모델의 일반화 능력을 향상시킬 수 있다는 것을 시사한다.
Shot Labels and Label Order 성능에 크게 영향을 미치는 추가 요소들을 발견했는데, 이는 프롬프트에 포함된 shot 예제의 구성과 관련이 있다. shot 예제의 순서는 중요한 역할을 하며, 클래스 라벨에 따라 shot 샘플을 섞는 것이 성능을 향상시키는데 도움이 된다. 또한, “긍정적"과 “부정적” 라벨의 비율이 예측 확률에 큰 영향을 미친다. “긍정적” shot의 비율이 적으면 “긍정적” 예측 확률이 크게 감소하고, “긍정적” shot 예제의 비율이 증가하면 “긍정적” 예측 확률이 빠르게 증가한다. 이러한 변화는 모델의 편향을 극복하게 해주며, 예를 들어, shot 예제로 “부정적"만 포함했을 때 2-shot의 정확도를 70.2%에서 73%로 향상시키는데 도움이 된다. shot의 수를 늘리면 클래스 예측 분포의 통계치가 크게 변하고, 이를 결정 임계값 이동과 결합하면, 모델의 편향을복하고 정확도를 78.6%까지 향상시킬 수 있다.
Overcoming Inference Biases and Reliance on Heuristics 이 모델이 30가지 다른 언어학적 “하위 케이스”(예를 들어, 수동태, 관계절 구분 등)를 얼마나 잘 처리할 수 있는지를 조사하였다. 초기에 모델은 어휘 겹침, 수열, 구성원 휴리스틱 등에 취약했지만, shot의 수를 늘리고 예측 확률을 고려하여 분포 평균을 조정함으로써 모델의 성능을 크게 향상시킬 수 있었다. 결국, 모델은 자연어 이해에 필수적인 다양한 문법/구문 규칙을 일관되게 적용할 수 있음을 확인했다. 특히, 모델이 다루기 어려웠던 하위 케이스 대부분은 사람들, 특히 초보자가 보통 혼동하기 쉬운 경우였다.
Summary of Evaluation
매우 큰 사전 학습된 언어 모델이 문법적, 구문적 구조를 “이해"하고 이를 활용하여 미세 조정 없이도 작업을 해결할 수 있다는 것을 알아냈다. 이런 언어적 성과는 모델 크기와 사전 학습의 양이 증가함에 따라 향상되며, NLP 벤치마크 성능과 동등한 수준임을 확인했다. 이는 벤치마크 데이터셋의 지표들이 전반적으로 언어 이해와 잘 상관관계를 가지고 있음을 보여준다.
이 모델들은 추론을 수행할 때 어휘적 중복이나 문장 부분 수열의 공유와 같은 표면적인 패턴에 의존하는 경향이 있다. 또한, 샘플 클래스에 대한 강력한 고유 편향을 가지며, 작업의 구성 방식에 매우 민감하게 반응한다.
컨텍스트 내 학습은 표준 학습과 유사한 원칙을 따르며, shot 샘플의 순서가 중요하다는 것을 발견하였다. 또한, shot 예제의 데이터 분포가 평가 샘플의 성능을 결정하며, shot과 평가 분포가 일치할 때만 최적의 성능을 달성할 수 있다. 따라서, 컨텍스트 내 학습은 분포 외 일반화 성능에 대한 문제를 자동으로 해결하는 방법이 아니다.
대규모 언어 모델에서 프롬프트 기반 설정으로 정확한 응답을 얻기 위해서는 특별한 노력이 필요하며, 작업에 구애받지 않는 일반적인 생성 모델을 사용하는 목표에 대한 개선 여지가 아직 많이 남아 있다는 것을 알 수 있다.
Qualitative Examples for MT-NLG Generation Capabilities
벤치마크 데이터셋의 분석 외에도, 우리는 새로운 시나리오에서 MT-NLG의 언어 생성 능력을 검토하였다. 그 결과, MT-NLG는 수수께끼 해결, 제퍼디 질문 응답, 코드 생성 등에서 놀라운 능력을 보였다.
Riddle Answer Generation 모델의 추론 능력을 시험하기 위해 직접 만든 수수께끼를 사용하였다. 수수께끼를 풀 때, 모델은 각 줄을 해석하면서 대답을 만들어내는 경향이 있었고, 이런 해석들은 대부분 합리적이었다. 또한, 여러 가지 가능한 답이 있는 수수께끼에 대해서는, 모델이 답안에 맞는 여러 해석을 생성할 수 있었다.
Jeopardy Questions 질문 응답 데이터셋을 활용해 모델을 평가하는 것 외에, 우리는 모델이 추측 게임에서 어떻게 지식을 활용하는지에 관심이 있다. 이를 위해 제퍼디! 질문을 사용하여 모델이 답변을 생성하도록 하였고, 이 결과 MT-NLG는 대부분의 경우에서 실제로 정확한 답변을 생성하는 능력을 보여주었다.
Code Generation 대규모 사전 학습된 언어 모델은 이미 코드 생성 능력을 보이고 있다. 이를 검증하기 위해, MT-NLG의 코드 생성 능력을 조사하였다. 결과적으로, MT-NLG는 구문적으로 올바른 코드를 일관되게 생성하며, 간단한 작업에 대한 올바른 구현을 도출할 수 있음을 확인하였다. 때때로 모델은 다른 함수를 활용한 답변을 생성한 후, 해당 함수를 생성하는 것을 관찰하였다.
Inferring Arithmetic Operations 언어 이해의 한 부분으로 수학적 연산을 이해하고 사용하는 능력을 검토하였다. 강력한 언어 모델이 특별히 수학 문제를 풀기 위해 학습받지 않아도 단순 산술 문제에 대해 우연 이상의 정확도로 답변할 수 있음이 확인되었다. 이를 통해, 모델이 표현식에서 연산자 기호를 숨기고 산술 연산을 역으로 추론하는 능력을 검사하는 새로운 작업을 설계하였고, 일반적인 연산들이 대부분 올바르게 추론될 수 있음을 관찰하였다.
Free-form Generative Writing Assistance 이 논문의 초록 부분을 작성하기 위해 MT-NLG를 활용하여 그 자유형 생성 능력을 질적으로 검토하였다. 각 문장을 생성할 때마다 여러 후보 중 하나를 선택하고 필요한 경우 편집하였으며, 이 과정을 초록이 완성된 것처럼 보일 때까지 반복하였다.
Related Works
모델과 데이터셋 크기를 확장하여 모델 성능을 향상시키는 방법이 최근 자연어 처리 분야에서 큰 성공을 거두었다. 대규모 사전 학습 패러다임 이전에도 LSTM 모델을 10억 개의 매개변수로 확장하는 노력이 있었고, 이 트렌드는 BERT와 GPT-2에서 이어졌다. 이를 더 넘어서는 확장은 더 복잡한 학습 기법을 요구하지만, 최근의 기술 발전은 더 큰 모델의 개발을 가능하게 하였다.
모델과 데이터셋 크기를 확장하여 모델 성능을 향상시키는 방법은 최근에 큰 성공을 거두었다. MoE 기법은 각 전달 단계에서 parameter의 하위 집합을 선택적으로 사용하여 더 큰 모델 크기를 더 경제적으로 확장하였다. 그러나 MT-NLG에 더 관련된 연구는 단일 블록, 밀집 transformer 아키텍처의 확장에 더 초점을 맞추고 있으며, 이 분야에서 우리의 연구는 530B parameter로 현재까지 가장 큰 단일 블록 transformer 언어 모델을 만들어 냈다.
최근 연구에서는 대규모 다태스크 세부 조정을 통해 언어 모델의 zero-shot 학습 능력을 직접 개선하는 방법에 집중하였다. 특히, T0와 FLAN 등의 연구에서는 이러한 접근법이 언어 모델의 zero-shot 학습 능력을 향상시킬 수 있음을 보여주었다. 이 방법은 모델 사이즈가 클수록 더 많은 이점을 얻는 것으로 나타났으며, 대규모 사전 학습 방법이 이와 시너지를 이루어 미래의 모델 개선에 기여할 것으로 기대하고 있다.
Conclusions
이 연구에서는 530B parameter의 transformer 기반 언어 모델인 MT-NLG를 소개하였다. 이 모델은 여러 NLP 벤치마크에서 state-of-the-art의 zero-/one-shot 및 few-shot 학습 성능을 보여주었다. 이런 규모의 모델을 효율적으로 학습시키기 위한 전략과 하드웨어 구조를 제시하였으며, MT-NLG가 보여주는 사회적 편향과 그 한계를 분석하였다. 이러한 결과와 발견이 대규모 사전 학습 연구에 도움이 될 것으로 기대한다.