Abstract
conditional music generation을 위한 “MusicGEN"이라는 언어 모델을 개발하였다. 이 모델은 여러 스트림의 압축된 이산 음악 표현을 다루며, 효율적인 토큰 교차 패턴과 single-stage transformer를 사용해 여러 모델을 계층적으로 구성하거나 업샘플링할 필요가 없다. 이 방법을 통해 텍스트 설명이나 멜로디 특징에 따라 높은 품질의 음악 샘플을 생성할 수 있음을 입증하였다. 실증적 평가를 통해 제안된 접근법이 기존 벤치마크보다 우수하다는 것을 보여주었다.
Introduction
text-to-music은 텍스트 설명을 바탕으로 음악을 생성하는 작업이다. 이 과정은 long range sequence를 모델링하고 full frequency spectrum을 사용해야 하므로 어렵다. 또한, 다양한 악기의 하모니와 멜로디를 포함하는 음악은 복잡한 구조를 가지며, 이로 인해 음악 생성 과정에서는 멜로디 오류를 범할 여지가 거의 없다. 키, 악기, 멜로디, 장르 등 다양한 요소를 제어할 수 있는 능력은 음악 창작자에게 필수적이다.
self-supervised audio representation, sequential modeling, audio synthesis 등의 최근 연구 진보가 새로운 모델 개발을 가능하게 한다. 최근 연구들은 오디오 신호를 같은 신호를 표현하는 여러 이산 토큰의 스트림으로 나타내는 것을 제안하였는데, 이를 통해 고품질의 오디오 생성과 효과적인 오디오 모델링이 가능해졌다. 그러나 이는 여러 parallel dependent stream을 동시에 모델링해야한다는 비용을 수반한다.
Kharitonov et al. 과 Kreuk et al. 은 음성 토큰의 다중 스트림을 병렬로 모델링하는 지연 접근법을 제안하였다. Agostinelli et al. 은 음악 세그먼트를 다양한 세부성의 이산 토큰 시퀀스로 표현하고 이를 autoregressive 모델로 모델링하는 방식을 제안하였다. Donahue et al. 은 비슷한 접근법을 가요 생성 작업에 적용했고, Wang et al. 은 문제를 두 단계로 해결하는 방법을 제안하였다: 첫 번째 토큰 스트림만 모델링한 후, non-autoregressive 방식으로 나머지 스트림을 모델링한다.
이 연구에서는 텍스트 설명에 따른 고품질 음악을 생성하는 “MusicGEN"이라는 단순하고 조절 가능한 모델을 소개한다. 이 모델은 음향 토큰의 병렬 스트림을 모델링하는 프레임워크를 제안하며, 스테레오 오디오 생성을 추가 비용 없이 확장할 수 있다. 또한, 비지도 멜로디 조건 설정을 통해 생성된 샘플의 제어력을 향상시키고, 주어진 조화와 멜로디 구조에 맞는 음악을 생성할 수 있다. MusicGEN은 평가에서 100점 만점에 84.8점의 높은 점수를 받았으며, 이는 최고 기준선의 80.5점보다 우수한 성능을 보여준다. 마지막으로, 인간 평가에 따르면 MusicGEN은 주어진 조화 구조에 잘 맞는 멜로디를 가진 고품질 샘플을 생성하며, 텍스트 설명을 충실히 따른다.
Our contribution: 32 kHz에서 고품질 음악을 생성하는 간단하고 효율적인 모델, MusicGEN을 제안한다. 이 모델은 효율적인 코드북 교차 전략을 통해 일관된 음악을 생성하며, 텍스트와 멜로디 조건에 모두 부합하는 단일 모델을 제공한다. 생성된 오디오는 제공된 멜로디와 일치하고 텍스트 조건 정보에 충실하다. 또한, 주요 설계 선택에 대한 광범위한 객관적 평가와 인간 평가를 제공한다.
Method
MusicGEN은 텍스트나 멜로디에 의존하는 autoregressive transformer-based decoder이다. 이 모델은 양자화된 오디오 토큰을 사용하며, 이는 고해상도 복구를 가능하게 한다. 병렬 스트림은 Residual Vector Quantization (RVQ)를 통해 생성되며, 각 스트림은 다양한 코드북에서 생성된 이산 토큰으로 구성된다. 이 연구에서는 다양한 코드북 교차 패턴에 적용 가능한 새로운 모델링 프레임워크를 소개하며, 이를 통해 양자화된 오디오 토큰의 내부 구조를 활용한다. MusicGEN은 텍스트나 멜로디를 기반으로 한 조건부 생성을 지원한다.
Audio tokenization
Residual Vector Quantization (RVQ)를 사용하여 양자화된 latent space와 adversarial reconstruction 손실을 가진 EnCodec을 사용한다. 이는 오디오 무작위 변수를 연속 텐서로 인코딩하고, 이를 다시 양자화하여 병렬 이산 토큰 시퀀스를 생성한다. RVQ에서는 각 양자화기가 이전 양자화기의 양자화 오류를 인코딩하므로, 다른 코드북의 양자화 값은 일반적으로 독립적이지 않다. 이 과정에서 첫 번째 코드북이 가장 중요하게 작용한다.
Codebook interleaving patterns
Exact flattened autoregressive decomposition. autoregressive 모델은 일정한 길이 $S$를 가진 이산 랜덤 시퀀스 $U$가 필요하며, 이 시퀀스는 {$1, …, N$}$^S$에서 선택된다. 관례적으로 시퀀스의 시작은 $U_0 = 0$, 즉 특별 토큰으로 표현된다. 이를 통해 분포를 모델링한다.
$$ \forall t > 0, p_t (U_{t−1}, …, U_0) \triangleq \mathbb{P} [U_t | U_{t−1}, …, U_0] $$
auto-regressive density $p$를 이용해 랜덤 변수의 두 번째 시퀀스인 $\tilde{U}$를 만든다. 이때, $\tilde{U}_0 = 0$으로 초기화하고, $t > 0$인 모든 경우에 대해 재귀적으로 정의한다.
$$ \forall t > 0, \mathbb{P} \big[\tilde{U}_t | \tilde{U}_{t−1}, …, \tilde{U}_0 \big] = p_t (\tilde{U}_{t−1}, …, \tilde{U}_0) $$
$U$와 $\tilde{U}$가 같은 분포를 가진다는 것이 바로 확인된다. 이는 딥러닝 모델로 $p$의 완벽한 추정치 $\tilde{p}$를 맞출 수 있다면, $U$의 분포도 정확히 맞출 수 있다는 것을 의미한다.
EnCodec 모델로부터 얻은 $Q$ 표현의 문제는 각 시간 단계마다 $K$개의 코드북이 있다는 점이다. 이를 해결하기 위해 $Q$를 펼쳐 $S = d \cdot f_r \cdot K$로 설정할 수 있다. 이 방식은 첫 번째 시간 단계의 각 코드북을 순차적으로 예측한다. 이론적으로 $Q$의 분포를 정확하게 모델링할 수 있지만, 복잡성이 증가하고 가장 낮은 샘플 속도 $f_r$에서 얻는 이익이 일부 손실된다.
여러 가지 flattening 방법이 가능하며, 모든 $\hat{p_t}$ 함수를 한 모델로 추정할 필요는 없다. 예를 들어, MusicLM은 두 개의 모델을 사용해 첫 번째 $K/2$ 코드북과 나머지 $K/2$ 코드북을 각각 모델링한다. 이렇게 해도 autoregressive step의 수는 $df_r \cdot K$로 동일하다.
Inexact autoregressive decomposition. 일부 코드북이 병렬로 예측되는 autoregressive 분해를 고려하는 것이 가능하다. 즉, $V_0 = 0$을 정의하고, 모든 $t$와 $k$에 대해 $V_{t, k} = Q_{t, k}$로 시퀀스를 설정한다. 이때, 코드북 인덱스 $k$를 생략하면, 시간 $t$에서 모든 코드북이 연결된 것을 의미한다.
$$ p_{t, k} (V_{t−1}, …, V_0) \triangleq \mathbb{P} [V_{t, k} | V_{t−1}, \dot, …, V_0] $$
재귀적으로 $\tilde{V}_0 = 0$을 다시 정의하고, 모든 $t > 0$에 대해 이를 정의한다.
$$ \forall t > 0, \mathbb{P} \big[\tilde{V}_{t, k} \big] = p_{t, k} (\tilde{V}_{t−1}, …, \tilde{V}_0) $$
일반적으로 정확한 분포 $p_{t,k}$를 가정하더라도 $\tilde{V}$는 $V$와 동일한 분포를 따르지 않는다. 실제로, 모든 $t$에 대해 $(V_{t,k})$ $k$가 $V_{t−1}, …, $V_0$에 조건부로 독립인 경우에만 적절한 생성 모델을 가진다. $t$가 증가함에 따라 오류가 누적되고 두 분포는 점점 멀어진다. 이 분해법은 부정확하지만 원래의 프레임 속도를 유지하므로, 학습과 추론이 특히 긴 시퀀스에 대해 크게 가속화된다.
Arbitrary codebook interleaving patterns. 다양한 분해 실험을 진행하고, 부정확한 분해의 영향을 측정하기 위해 코드북 교차 패턴을 사용한다. 모든 시간 단계와 코드북 인덱스의 쌍을 나타내는 $\Omega$ 집합을 고려하며, 코드북 패턴은 $P_0 = \emptyset$으로 시작해 $P_s$가 $\Omega$ 의 부분집합인 시퀀스이다. 이 패턴은 $\Omega$를 모델링하는 데 사용되며, 모든 위치를 병렬로 예측합니다. 실용적으로, 각 $P_s$에서 코드북 인덱스가 최대 한 번만 나타나는 패턴으로 제한한다.
“parallel” 패턴과 같은 여러 분해를 쉽게 정의할 수 있다. 이 패턴은 다음과 같이 주어진다.
$$ P_s = \lbrace (s, k) : k \in \lbrace 1, …, K \rbrace \rbrace $$
코드북 사이에 “delay"를 도입하는 것도 가능하다.
$$ P_s = \lbrace (s − k + 1, k) : k \in \lbrace 1, …, K \rbrace , s − k \geq 0 \rbrace $$
다양한 코드북 패턴의 장단점을 실증적으로 평가하여, 병렬 코드북 시퀀스 모델링의 중요성을 강조한다.
Model conditioning
Text conditioning. 입력 오디오에 대응하는 텍스트를 표현하는 세 가지 주요 방법에 대해 실험하였다: T5 인코더를 사용하는 Kreuk et al. 의 방법, 지시기반 언어 모델을 사용하는 Chung et al. 의 방법, 그리고 공동 텍스트-오디오 표현인 CLAP을 사용하는 방법이다. 이 세 가지 방법 모두 조건부 오디오 생성 테스트에서 사용되었다.
Melody conditioning. 텍스트보다는 다른 오디오 트랙이나 휘파람, 허밍 등에서 얻은 멜로디 구조를 조건으로 삼는 것이 음악에 더 적합하다. 이를 위해 입력의 chromagram과 text description에 동시에 조건을 부여하여 멜로디 구조를 제어하는 실험을 진행하였다. 하지만 raw chromagram에 조건을 부여하면 과적합이 발생해 원본 샘플이 재구성되는 문제가 발생하였다. 이를 해결하기 위해 각 시간 단계에서 주요 time-frequency 빈도를 선택하는 정보 병목 방법을 도입하였다. 이는 supervised proprietary 데이터가 필요 없는 unsupervised 학습 방법으로, 데이터 수집 비용을 줄이는 효과가 있다.
Model architecture
Codebook projection and positional embedding. 코드북 패턴에 따라 각 패턴 단계에서는 일부 코드북만 사용된다. 각 코드북은 최대 한 번만 사용되거나 아예 사용되지 않는다. 코드북이 사용되면, 해당 값은 학습된 임베딩 테이블을 통해 표현되고, 사용되지 않으면 특별 토큰으로 표시된다. 이렇게 변환된 각 코드북의 기여를 합산하며, 첫 번째 입력은 모든 특별 토큰의 합이 된다. 마지막으로, 현재 단계를 인코딩하기 위해 사인 임베딩을 합산한다.
Transformer decoder. 입력값은 여러 layer와 차원을 가진 transformer를 통해 처리된다. 각 layer는 causal self-attention block으로 구성되고, 조건부 신호 $C$에 따라 cross-attention block을 사용한다. 멜로디 조건을 사용할 경우, 조건부 텐서 $C$를 transformer 입력의 접두어로 사용한다. layer는 fully connected block으로 끝나며, 이 block은 linear layer, ReLU, 그리고 다시 linear layer로 구성된다. 각 block은 residual skip 연결로 래핑되고, 각 block에는 layer normalization가 적용된다.
Logits prediction. transformer decoder의 출력은 패턴 단계에서 $Q$의 값에 대한 logit 예측으로 변환된다. 코드북이 존재하면, 코드북 특정 linear layer를 적용하여 logit 예측을 얻는다.
Experimental setup
Models and hyperparameters
Audio tokenization model. 32 kHz 단음 오디오를 위한 비인과적인 5층 EnCodec 모델을 사용하며, 이는 50 Hz의 frame rate와 initial hidden size 64를 가진다. 4개의 양자화기를 가진 RVQ로 임베딩을 양자화하고, 오디오 시퀀스에서 무작위로 잘린 1초 오디오 세그먼트로 모델을 학습시킨다.
Transformer model. 300M, 1.5B, 3.3B parameter의 크기를 가진 autoregressive transformer 모델을 학습시킨다. 이 모델들은 긴 시퀀스의 처리 속도와 메모리 사용량을 개선하기 위해 memory efficient Flash attention을 사용한다. 이 기술은 xFormers 패키지에서 구현되어 있다.
이 모델들은 전체 음악 트랙에서 무작위로 샘플링된 30초 오디오 클립을 학습 데이터로 사용한다. 각 모델은 1M 단계 동안 AdamW optimizer를 사용하여 학습되며, batch size는 192, $\beta_1$은 0.9, $\beta_2$는 0.95, weight decay는 0.1, 그리고 gradient clipping은 1.0의 값을 가진다.
300M parameter 모델의 경우, D-Adaptation 기반의 automatic step-size를 사용하여 모델의 수렴을 개선한다. 이 방법은 모델의 크기가 더 큰 경우에는 별다른 효과가 없었다.
모델의 learning rate은 4000 step의 warmup을 가진 cosine learning rate을 따르며, 이동 평균은 0.99의 decay를 사용하여 계산된다.
각 모델은 각각 32, 64, 96의 GPU를 사용하여 학습되며, mixed precision 방식을 사용한다. 더욱이, bfloat16이 시스템에서 불안정성을 초래하므로 float16을 사용한다.
마지막으로, 샘플링 과정에서는 top-k 샘플링 방법을 사용하여 상위 250개의 토큰만을 유지하고, 이 토큰들의 확률 분포를 이용하여 샘플링을 진행한다. 이때의 temperature 값은 1.0이다.
Text preprocessing. Kreuk et al. 은 불용어를 제거하고 텍스트를 표제어화하는 텍스트 정규화 방법을 제안하였다. 음악 데이터셋에서는 음악 키, 템포, 악기 유형 등의 추가 정보를 텍스트 설명에 병합하는 실험을 진행하였다. 또한, 단어 dropout을 텍스트 augmentation 전략으로 사용하였다. 최종 모델에서는 0.25 확률로 정보 병합, 0.5 확률로 텍스트 dropout, 0.3 확률로 단어 dropout을 적용하였다.
Codebook patterns and conditioning. 30초의 오디오를 1500개의 autoregressive step으로 변환하는 “delay” 교차 패턴을 사용한다. 텍스트 조건 부여에는 T5 텍스트 encoder를 사용하며, 필요에 따라 멜로디 조건 부여를 추가한다. FLAN-T5와 CLAP를 실험하고, 각 텍스트 encoder의 성능을 비교하였다. 멜로디 조건 부여에는 chromagram을 계산하고 양자화하는 방법을 사용하였다. 학습 중에는 조건을 일정 확률로 드롭하고, 추론 시에는 가이드 스케일을 적용한다.
Datasets
Training datasets. 20K 시간의 라이선스 음악, 내부 데이터셋의 10K 고품질 음악 트랙, 그리고 ShutterStock과 Pond5 음악 데이터 컬렉션을 사용하여 MusicGEN을 학습시킨다. 이 데이터셋들은 모두 텍스트 설명, 장르, BPM, 태그 등의 메타데이터와 함께 32 kHz로 샘플링된 전체 길이의 음악을 포함하며, 오디오는 모노로 다운믹스된다.
Evaluation datasets. MusicCaps 벤치마크에서 평가하였다. 이 벤치마크는 전문 음악가들이 준비한 5.5K의 샘플과 장르별로 균형을 이루는 1K의 샘플로 구성되어 있다. 균형되지 않은 샘플에서 객관적 지표를 보고하고, 질적 평가를 위해 장르 균형 샘플에서 예제를 추출하였다. 또한, 멜로디 평가와 소거 연구를 위해 학습 세트와 아티스트가 중복되지 않는 528개의 음악 트랙으로 구성된 평가 세트를 사용하였다.
Evaluation
Baselines. Riffusion과 Mousai, 두 가지 text-to-music 생성 모델과 MusicGEN을 비교한다. 오픈소스 Riffusion 모델을 이용해 추론을 실행하고, Mousai의 경우 저자들이 제공한 오픈소스를 이용해 이 연구의 데이터셋으로 모델을 학습시켜 비교하였다. 가능한 경우, MusicLM과 Noise2Music과도 비교하였다.
Evaluation metrics. 객관적인 지표인 Fréchet Audio Distance(FAD), Kullback-Leiber Divergence(KL), 그리고 CLAP 점수를 이용하여 제안한 방법을 평가한다. FAD 점수는 생성된 오디오의 타당성을 나타내며, KL-Divergence는 원본 음악과 생성된 음악 사이의 레이블 확률을 비교한다. 이때, KL이 낮을수록 생성된 음악이 원본 음악과 유사한 개념을 가지고 있다고 판단한다. 마지막으로, CLAP 점수는 트랙 설명과 생성된 오디오 사이의 정렬을 정량화한다.
인간 평가자들을 활용하여 overall quality(OVL)과 relevance to the text input(REL)을 평가하는 연구를 진행하였다. 평가자들은 제공된 오디오 샘플의 품질과 텍스트와의 일치도를 각각 1에서 100의 범위로 평가하였다. 이 평가는 Amazon Mechanical Turk 플랫폼에서 모집한 평가자들을 통해 진행되었고, 각 샘플은 최소 5명의 평가자에 의해 평가되었다. 잡음 주석과 이상치는 CrowdMOS 패키지를 통해 필터링하였으며, 모든 샘플은 공정성을 위해 -14dB LUFS에서 정규화되었다.
Results
text-to-music 생성 작업에 대한 제안된 방법의 결과를 제시하며, 이전의 연구와 비교한다. 또한, 멜로디 특징에 기반한 음악 생성 능력을 평가하고, 스테레오 오디오 생성을 위해 코드북 패턴을 확장하는 방법을 설명한다.
Comparison with the baselines
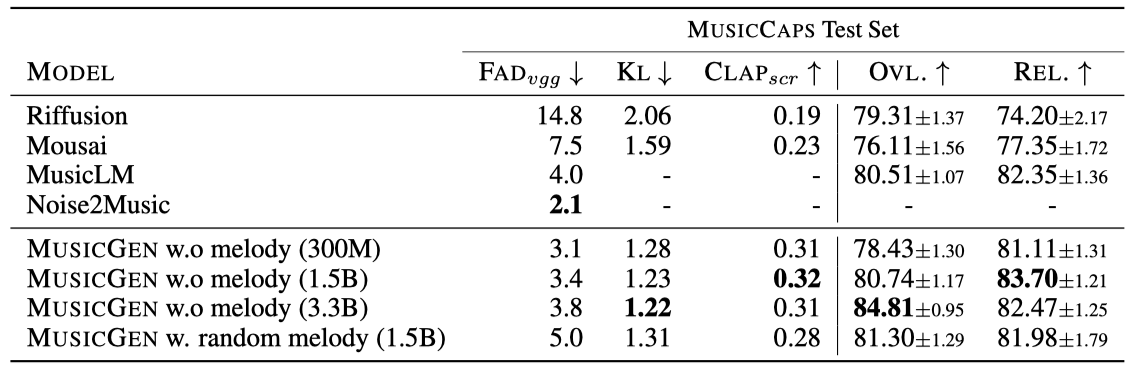
제안된 방법과 Mousai, Riffusion, MusicLM, 그리고 Noise2Music와의 비교 한다. Noise2Music과 MusicLM의 공식 구현이 없으므로, 각각의 원고에서 보고된 FAD만을 보고한다. 인간 연구에서는 MusicCaps의 악기만을 사용한 40개 샘플을 사용하였으며, MusicGEN의 chromagram 학습에서 누수를 방지하기 위해 테스트 시간 동안 보류된 세트에서 무작위로 chromagram을 샘플링하였다.
결과적으로 MusicGEN은 오디오 품질과 텍스트 설명 준수 측면에서 인간 청취자들에게 더 높은 평가를 받았다. Noise2Music은 MusicCaps에서 FAD 측면에서 가장 우수했으며, 텍스트 조건부로 학습된 MusicGEN이 뒤를 이었다. 멜로디 조건을 추가하면 객관적 지표가 저하되지만, 인간 평가에는 큰 영향을 미치지 않았다.
낮은 평가를 받은 모델에 대해서는 FAD가 주관적 평가와 상관관계가 있지만, 높은 평가를 받은 모델에는 그러지 않았다. 또한, MusicCaps의 많은 샘플이 “noisy” 녹음이라는 설명을 포함하고 있어, 오디오 품질 향상이 일정 수준을 넘어설 경우 FAD가 악화될 수 있다는 사실을 발견하였다.
Melody evaluation

텍스트와 멜로디를 동시에 고려하는 MusigGEN을 객관적, 주관적 지표로 평가하였다. 이를 위해 새로운 지표인 chroma cosine-similarity를 도입하였으며, 이는 참조 샘플과 생성된 샘플의 chroma 사이의 average cosine-similarity를 측정한다. 또한, 인간 연구를 통해 생성된 음악과 멜로디 사이의 관계를 평가하였다. 결과적으로 MusigGEN은 주어진 멜로디를 따르는 음악을 성공적으로 생성하며, chroma를 떨어뜨려도 성능이 유지되는 것으로 나타났다.
Fine-tuning for stereophonic generation
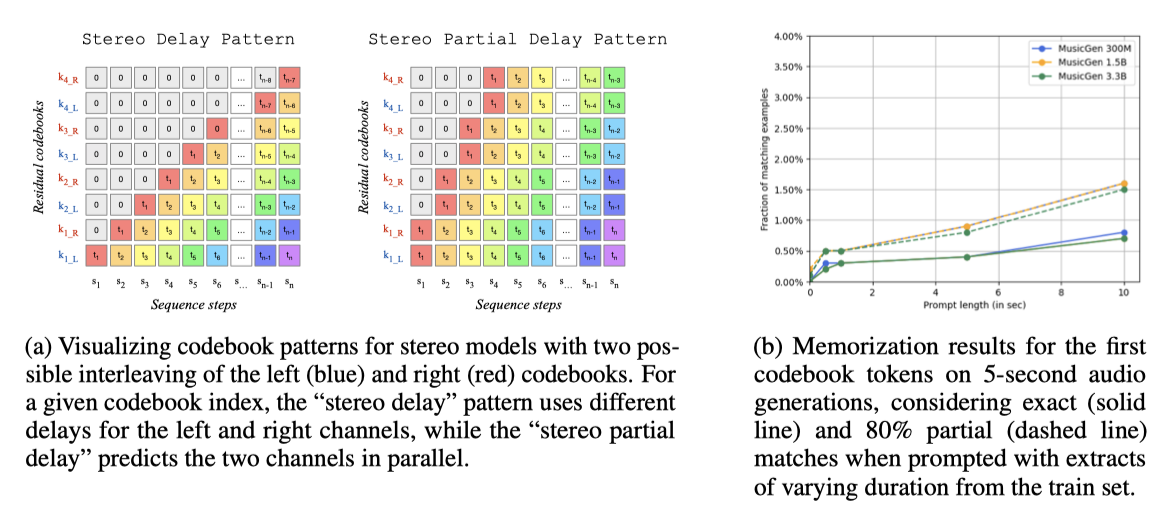
스테레오 데이터로의 생성을 확장하려는 실험을 진행하였다. 동일한 EnCodec 토크나이저를 사용하여 왼쪽과 오른쪽 채널에 독립적으로 적용하였고, 사전 학습된 단일 음향 MusicGEN 모델을 스테레오 오디오를 포함하는 데이터셋으로 미세 조정하였다. “delay” 패턴을 재사용하고, “stereo delay"과 “stereo partial delay” 두 가지 변형을 도입하였다. 이 간단한 전략을 통해 추가적인 계산 비용 없이 스테레오 오디오를 생성할 수 있었다. 스테레오 출력을 모노로 다운믹싱하면, 모노 모델과 거의 동등한 품질을 느낄 수 있었다. 전반적으로 스테레오 오디오가 모노보다 높게 평가되었으며, “stereo partial delay"이 “stereo delay"에 비해 전반적인 품질과 텍스트 관련성에서 약간의 향상을 보였습니다.
Ablation
다양한 코드북 패턴의 제거 연구와 모델 크기, 기억 연구 결과를 소개한다. 이 모든 연구는 보류된 평가 세트에서 임의로 샘플링된 30초 분량의 1K 샘플을 사용하여 수행되었다.
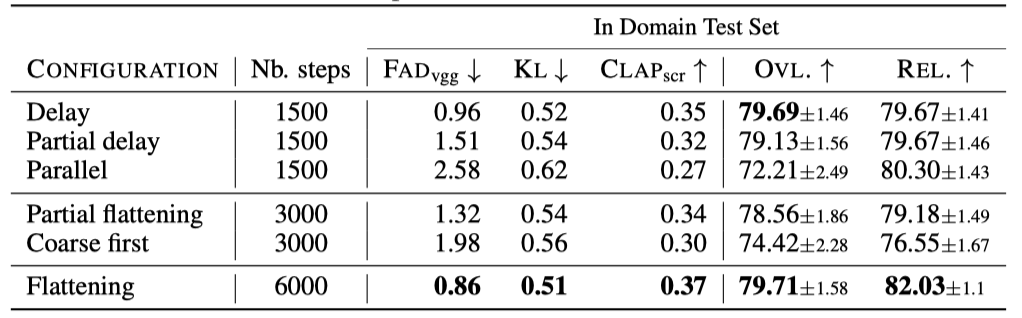
The effect of the codebook interleaving patterns. 여러 코드북 패턴을 평가하였다. 이는 “delay”, “partial delay”, “parallel”, “coarse first”, “Partial flattening”, “flattening” 등의 패턴을 포함한다. 이 중 “flattening” 패턴은 생성을 개선하지만 높은 계산 비용이 들며, 간단한 “delay” 방식을 사용하면 비슷한 성능을 더 적은 비용으로 달성할 수 있음을 발견하였다.

The effect of model size. 다양한 모델 크기(300M, 1.5B, 3.3B parameter)에 대한 결과를 보고하였다. 모델 크기를 크게하면 성능이 향상되지만, 학습과 추론 시간이 더 길어진다. 주관적인 품질은 1.5B에서 최적이며, 더 큰 모델은 텍스트 프롬프트를 더 잘 이해한다.
Memorization experiment. 우리는 MusicGEN의 기억능력을 분석하였다. 학습 세트에서 20,000개의 예제를 무작위로 선택하고, 각각에 대해 원본 오디오에 해당하는 프롬프트를 모델에 입력하였다. greedy decoding을 사용하여 5초 길이의 오디오를 생성하고, 생성된 오디오와 원본 오디오가 일치하는 비율을 보고하였다. 또한, 80% 이상 일치하는 경우의 비율도 보고하였다.
Related work
Audio representation. 최근 연구는 음악 신호를 압축된 표현으로 변환하고 이를 기반으로 생성 모델을 적용하는 방식을 주로 사용하고 있다. Lakhotia et al. 은 k-means를 사용한 음성 표현의 양자화를, Défossez et al. 과 Zeghidour et al. 은 residual vector quantization를 사용한 원시 파형에 대한 VQ-VAE 적용을 제안하였다. 이러한 방법들은 텍스트에서 오디오로의 생성에 활용되고 있다.
Music generation. 음악 생성은 다양한 방법으로 연구되어 왔다. Dong et al. 은 GAN을 사용한 심볼symbolic릭 음악 생성을, Bassan et al. 은 symbolic 음악의 비지도학습 분할을 제안하였다. Ycart et al. 은 RNN을 이용한 polyphonic 음악 모델링을, Ji et al. 은 음악 생성에 대한 딥러닝 방법들을 포괄적으로 조사하였다.
Dhariwal et al. 은 hierarchical VQ-VAE를 사용하여 음악 샘플을 discrete representation으로 변환하고, 이를 통해 음악을 생성하는 방법을 제안하였다. Gan et al. 은 주어진 비디오에 대한 음악을 생성하면서 미디 노트를 예측하는 방법을, Agostinelli et al. 은 의미 토큰과 음향 토큰을 사용하여 음악을 표현하는 방법을 제안하였다. Donahue et al. 은 이러한 접근법을 노래 동반 생성 작업에 적용하였다.
diffusion 모델을 사용하는 것은 대안적인 접근법이다. Schneider et al., Huang et al., Maina, Forsgren and Martiros는 이를 텍스트에서 음악으로 변환하는 작업에 적용하였다. Schneider et al.과 Huang et al. 은 오디오 생성과 샘플링 비율 증가에 diffusion 모델을 사용하였다. Forsgren et al. Martiros는 5초 오디오 세그먼트 생성과 장기 시퀀스 생성을 위해 spectrogram을 이용한 diffusion 모델을 미세조정하였다.
Audio generation. 텍스트에서 오디오로 변환하는 연구가 다양하게 진행되었다. Yang et al. 은 오디오 spectrogram을 VQ-VAE를 이용해 표현하고, 이를 기반으로 텍스트 CLIP 임베딩에 조건화된 diffusion 모델을 적용하였다. Kreuk et al. 과 Sheffer와 Adi는 각각 transformer 언어 모델과 이미지-오디오 생성을 위한 접근법을 제안하였다. 또한, Huang et al. 과 Liu et al. 은 텍스트-오디오 작업을 위해 latent diffusion 모델을 사용하면서 이를 다양한 작업에 확장하는 방법을 제안하였다.
Discussion
텍스트와 멜로디에 따라 조절 가능한 음악 생성 모델인 MusicGEN을 소개하였다. 이 모델은 단순한 코드북 교차 전략을 통해 고품질의 음악 생성을 가능하게 하고, autoregressive 시간 단계를 줄일 수 있다. 또한 모델 크기, 조건화 방법, 텍스트 전처리 기법의 영향에 대한 포괄적인 연구를 제공하며, 생성된 오디오의 멜로디를 제어하는 chromagram 기반 조건화를 소개하였다.
Limitations 이 모델의 생성 방법은 조건에 따른 세밀한 제어를 허용하지 않아 CF guidance에 주로 의존한다. 텍스트 조건에 대한 데이터 augmentation은 상대적으로 간단하지만, 오디오 조건에 대한 데이터 augmentation와 guidance에 대해 추가 연구가 필요하다.
Broader impact. 대규모 생성 모델은 윤리적 도전을 제시한다. 모든 학습 데이터가 권리 소유자와 합의 하에 이루어지며, 데이터셋의 다양성 부족 문제를 인지하고 있다. 이 문제를 해결하기 위해 단순화된 모델을 사용하여 새로운 데이터셋에 대한 응용을 확대하고 있다. 또한, 이러한 모델이 아티스트에 대한 불공정한 경쟁을 일으킬 수 있음을 인지하며, 이 문제를 해결하기 위해 열린 연구를 통해 모든 참가자가 모델에 동등하게 접근할 수 있도록 노력하고 있다. 고급 제어 기법을 통해, 모델이 음악 애호가와 전문가 모두에게 도움이 될 수 있도록 하고 있다.