Abstract
MusicLM은 “a calming violin melody backed by a distorted guitar riff"과 같은 텍스트 설명을 바탕으로 고품질의 음악을 생성하는 모델이다. 이 모델은 sequenceto-sequence 모델링을 통해 음악을 생성하며, 음질과 텍스트 설명의 정확성에서 이전 모델들을 능가한다. 또한, 텍스트와 멜로디 모두에 조건을 두어 휘파람과 허밍된 멜로디를 텍스트 캡션에 따라 변형할 수 있다. 이를 지원하기 위해, 5.5k의 음악-텍스트 쌍 데이터셋인 MusicCaps를 공개하였다.
Introduction
conditional neural 오디오 생성은 text-to-speech, lyrics-conditioned 음악 생성, MIDI 시퀀스로부터의 오디오 합성 등 다양한 분야에서 활용된다. 최근에는 text-to-image 생성 연구의 발전에 따라, 고수준의 캡션으로부터 오디오를 생성하는 연구가 진행되었다. 그러나 이러한 모델은 아직 단순한 음향 장면에 한정되어 있어, 풍부한 오디오 시퀀스를 생성하는 것은 여전히 도전 과제로 남아 있다.
최근에 소개된 AudioLM은 오디오 합성을 discrete representation 공간에서의 언어 모델링 작업으로 취급하여 고해상도와 장기 일관성을 동시에 달성한다. 오디오 신호의 내용에 대한 가정 없이 오디오 전용 말뭉치에서 현실적인 오디오를 생성하는 방법을 학습한다. 이러한 시스템이 적절한 데이터에 학습된다면 더 풍부한 출력을 생성할 수 있을 것으로 보인다.
고품질 오디오 합성의 본질적인 어려움 외에도, 오디오-텍스트 쌍 데이터의 부족이 주요 장애 요인이다. 이는 이미지 도메인과 대조적으로, 이미지 도메인에서는 대규모 데이터셋의 사용이 뛰어난 이미지 생성 품질에 크게 기여하였다. 또한, 오디오의 주요 특성을 단어로 명확하게 포착하거나 시퀀스 전체에 대한 캡션을 제공하는 것은 이미지를 설명하는 것보다 더욱 어렵다.
이 연구에서는 텍스트 설명으로 고해상도 음악을 생성하는 MusicLM 모델을 소개한다. MusicLM은 AudioLM의 multi-stage autoregressive 모델링을 활용하고, 텍스트 조건부를 추가한다. 쌍 데이터의 부족함을 해결하기 위해, 공동 music-text 모델인 MuLan을 활용하여 음악과 텍스트 설명을 임베딩 공간에서 가까운 표현으로 투영한다. 이렇게 하면 학습 시간에 캡션의 필요성을 제거하고, 대규모 오디오 말뭉치에서 학습할 수 있다. 학습 시에는 오디오에서 계산된 MuLan 임베딩을, 추론 시에는 텍스트 입력에서 계산된 MuLan 임베딩을 사용한다.
MusicLM은 라벨이 없는 대규모 음악 데이터셋에 학습되어 복잡한 텍스트 설명에 따른 일관성 있는 음악을 생성한다. 이를 평가하기 위해, 전문 음악가들이 준비한 5.5k의 예시를 포함하는 고품질 음악 캡션 데이터셋인 MusicCaps를 소개하고, 이를 공개하여 미래의 연구를 지원한다.
이 연구의 실험은 MusicLM이 품질과 캡션 준수 면에서 이전 시스템을 능가한다는 것을 보여준다. 또한, 음악의 일부 측면을 단어로 설명하는 것이 어렵거나 불가능한 경우에도, 이 방법이 텍스트를 넘어서는 조건부 신호를 지원한다. 특히, 오디오 형태의 추가적인 멜로디를 받아들여 원하는 멜로디를 따르는 음악 클립을 생성하는 확장된 MusicLM을 소개한다.
음악 생성과 관련된 위험성, 특히 창의적 콘텐츠의 부당한 사용을 인지하고 있다. 이에 따라, 대형 언어 모델에 대한 기억력 연구를 철저히 수행하였고, MuLan 임베딩을 MusicLM에 입력하면 생성된 토큰의 시퀀스가 학습 세트의 해당 시퀀스와 크게 다르다는 결과를 얻었다.
이 작업의 주요 기여는 다음과 같다:
- 텍스트 조건부 신호에 충실하게 몇 분 동안 일관된 고품질 음악을 생성하는 MusicLM 모델을 소개한다.
- 멜로디와 같은 다른 조건부 신호로 방법을 확장하고, 텍스트 프롬프트에 따라 합성한다. 또한, 최대 5분 길이의 음악 클립을 일관되게 생성하는 것을 보여준다.
- text-to-music 생성 작업을 위한 첫 번째 평가 데이터셋인 MusicCaps를 공개한다. 이는 음악가들이 준비한 5.5k의 음악-텍스트 쌍으로 구성된 고품질 데이터셋이다.
Background and Related Work
다양한 도메인의 생성 모델링에서 Transformer 기반의 autoregressive 모델과 U-Net 기반의 diffusion 모델이 주도하고 있다. 이 섹션에서는 discrete 토큰을 다루는 autoregressive 생성 모델에 초점을 맞춰 MusicLM과 관련된 작업을 검토한다.
Quantization
자연어 처리, 이미지, 비디오 생성 등에서 autoregressively 하게 discrete 토큰의 시퀀스를 모델링하는 것이 효과적임이 입증되었다. 연속 신호에 대한 autoregressive 모델의 성공에는 양자화가 중요하며, 이는 컴팩트한 discrete 표현을 제공하면서도 높은 품질의 재구성을 가능하게 한다. VQ-VAEs는 다양한 도메인에서 낮은 비트레이트에서 뛰어난 재구성 품질을 보여주며, 많은 접근법의 기본 양자화 도구로 사용되었다.
SoundStream은 일반 오디오를 낮은 비트레이트로 압축하면서도 높은 재구성 품질을 유지하는 neural audio codec이다. 이를 위해 residual vector quantization(RVQ)를 사용하여 비트레이트와 품질을 높이는 데 큰 계산 비용 없이 확장성을 제공한다. RVQ는 대상 비트레이트가 증가함에 따른 코드북 크기의 급증을 방지하며, 각 양자화기가 계층적 구조를 가지게 된다. 이는 고품질 재구성에 유리하며, 생성에도 바람직한 속성이다. 이 작업에서는 24kHz 음악을 6kbps로 고품질로 재구성할 수 있는 SoundStream을 오디오 토크나이저로 사용한다.
Generative Models for Audio
장기적인 일관성을 유지하면서 고품질 오디오를 생성하는 것은 어려운 문제지만, 최근에는 Jukebox와 PerceiverAR 같은 일련의 방법론이 이 문제를 해결하려 노력하였다. Jukebox는 높은 시간적 일관성을 달성하기 위해 VQVAEs의 계층을 제안하지만, 생성된 음악에서 아티팩트가 나타났다. 반면 PerceiverAR은 고품질 오디오를 달성하지만, 장기적인 시간적 일관성을 저해하였다.
AudioLM은 계층적 토크나이징과 생성 체계를 사용하여 일관성과 고품질 합성 사이의 균형을 맞춘다. 이 방법은 의미 토큰과 음향 토큰 두 가지 유형을 구분하여 장기 구조를 모델링하고 미세한 음향 세부 사항을 포착한다. 이를 통해 AudioLM은 대본이나 기호적 음악 표현에 의존하지 않고도 일관되고 고품질의 음성과 피아노 음악을 생성할 수 있다.
MusicLM은 AudioLM을 기반으로 하되, 추가적으로 (1) 생성 과정을 설명적인 텍스트에 조절하는, (2) 이 조절을 멜로디와 같은 다른 신호로 확장하는, 그리고 (3) 피아노 음악을 넘어 다양한 음악 장르의 긴 시퀀스를 모델링하는 세 가지 기여를 한다.
Conditioned Audio Generation
텍스트 설명에서 오디오를 생성하는 것은 최근 연구 주제로 다루어졌다. DiffSound는 텍스트 인코더로 CLIP을 사용하고, 확산 모델을 적용하여 텍스트 임베딩에 따른 양자화된 멜 스펙트로그램 특성을 예측한다. 반면 AudioGen은 T5 인코더를 텍스트 임베딩에 사용하고, autoregressive transformer decoder로 EnCodec에 의해 생성된 오디오 코드를 예측한다. 두 연구 모두 AudioSet과 AudioCaps 같은 적절한 양의 쌍을 이룬 학습 데이터에 의존한다.
텍스트에 기반한 음악 생성에 초점을 맞춘 연구 중, Mubert는 텍스트 프롬프트를 transformer로 임베딩하고, 이를 바탕으로 음악 태그를 선택하여 노래 생성 API에 쿼리한다. 반면 Riffusion은 안정적인 diffusion 모델을 음악-텍스트 데이터셋의 멜 스펙트로그램 음악 조각에 미세조정한다. 이 두 연구를 기준선으로 사용하여, 이 연구가 오디오 생성 품질과 텍스트 설명의 준수를 개선한다는 것을 보여준다.
음악의 기호적 표현(예: MIDI)이 강력한 조절 형태로서 생성 과정을 주도하는 것이 보여졌다. 그러나 MusicLM은 허밍된 멜로디와 같은 방법을 통해 더 자연스럽고 직관적인 조절 신호를 제공하며, 이는 텍스트 설명과 결합될 수 있다.
Text-Conditioned Image Generation
텍스트 조건의 이미지 생성 모델은 구조적 개선과 대량의 고품질 쌍 학습 데이터 덕분에 큰 진전을 이루었다. 이 방법은 transformer 기반의 autoregressive 접근법과 확산 기반 모델을 포함하며, 이는 텍스트 프롬프트에서 비디오를 생성하는 것으로 확장되어 왔습니다.
이 연구의 접근법은 DALL·E 2와 가장 유사하며, 둘 다 텍스트 인코딩을 위해 CLIP에 의존한다. 하지만, DALL·E 2가 diffusion 모델을 decoder로 사용하는 반면, 이 연구는 AudioLM을 기반으로 한 deocer를 사용한다. 또한, 오디오 전용 데이터셋에서 학습이 가능하도록 텍스트 임베딩을 음악 임베딩으로 매핑하는 사전 모델을 생략하고, 추론 시에 음악 임베딩을 텍스트 임베딩으로 단순히 대체한다.
Joint Embedding Models for Music and Text
MuLan은 음악과 텍스트의 공동 임베딩 모델로, 각 모달리티에 대한 임베딩 탑을 포함한다. 이 탑들은 대조 학습을 통해 두 모달리티를 128차원의 공유 임베딩 공간으로 매핑한다. 텍스트 임베딩 네트워크는 대규모 텍스트 데이터에서 사전 학습된 BERT를 사용하며, 오디오 탑은 ResNet-50 변형을 사용한다.
MuLan은 음악 클립과 그에 대응하는 텍스트 주석의 쌍에 학습된다. 데이터 품질에 대한 요구가 낮아, 약한 연관성만 가진 음악-텍스트 쌍에서도 상호 연관성을 학습할 수 있다. 이로 인해 음악을 자연 언어 설명에 연결하여 검색이나 zero-shot 음악 태깅에 활용할 수 있다. 이 작업에서는 Huang et al. (2022)의 사전 학습된 모델을 사용한다.
Method
이 섹션에서는 MusicLM과 그 구성 요소에 대해 설명한다. 섹션 3.1은 오디오 표현을 제공하는 모델에 대해, 그리고 섹션 3.2는 이를 텍스트 조건의 음악 생성에 어떻게 활용하는지에 대해 다룬다.
Representation and Tokenization of Audio and Text
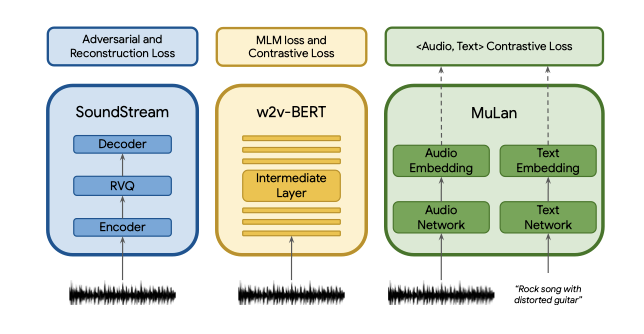
conditional autoregressive 음악 생성을 위해 세 가지 모델을 사용해 오디오 표현을 추출한다. AudioLM의 접근법을 따라 SoundStream의 self-supervise 오디오 표현과 w2vBERT를 각각 음향 토큰과 의미 토큰으로 사용하며, 조절을 위해 MuLan의 음악 임베딩과 텍스트 임베딩을 활용한다. 이 모델들은 독립적으로 사전 학습되고 고정되어, sequence-to-sequence 모델링에 필요한 이산적인 오디오와 텍스트 표현을 제공한다.
SoundStream. 24 kHz monophonic 오디오를 위해 스트라이딩 요소 480의 SoundStream 모델을 사용하며, 이로 인해 50 Hz의 임베딩이 생성된다. 이 임베딩들은 RVQ에 의해 학습된 양자화로 인해 6 kbps의 비트레이트를 가지게 되며, 1초의 오디오는 600개의 토큰으로 표현된다. 이 토큰들을 “acoustic token"이라 부르며, 이는 $A$로 표기된다.
w2v-BERT. 600M parameter를 가진 w2v-BERT masked-language-modeling (MLM) 모듈의 중간 계층을 사용한다. 이 모델을 사전 학습하고 고정한 후, 7번째 계층에서 임베딩을 추출하고, 이를 k-means의 중심을 사용해 양자화한다. 결과적으로, 오디오의 모든 초당 25개의 의미 토큰을 생성하며, 이는 $S$로 표기된다.
MuLan. MusicLM을 학습시키기 위해, MuLan의 오디오 임베딩 네트워크에서 오디오 시퀀스의 표현을 추출한다. 이 표현은 연속적이지만, 오디오와 조절 신호가 동질적인 이산 토큰 기반 표현을 가지도록 MuLan 임베딩을 양자화한다. 이는 조절 신호를 autoregressively 하게 모델링하는 연구를 지원한다.
MuLan은 10초 오디오 입력에 작동하며, 긴 오디오 시퀀스를 처리하기 위해 1초 간격으로 10초 윈도우에서 오디오 임베딩을 계산하고 평균화한다. 이후 1024 크기의 어휘를 가진 12개의 벡터 양자화기를 사용하는 RVQ로 이산화하여, 오디오 시퀀스에 대해 12개의 MuLan 오디오 토큰 $M_A$를 생성한다. 추론 시에는 텍스트 프롬프트에서 MuLan 텍스트 임베딩을 추출하고 같은 RVQ로 양자화하여 12개의 토큰 $M_T$를 얻는다.
학습 중에 $M_A$에 조건을 부여하는 것은 학습 데이터를 쉽게 확장할 수 있도록 하며, 대조적인 손실로 학습된 MuLan 같은 모델을 활용해 잡음이 많은 텍스트 설명에 대한 강건성을 높이는 두 가지 이점이 있다.
Hierarchical Modeling of Audio Representations
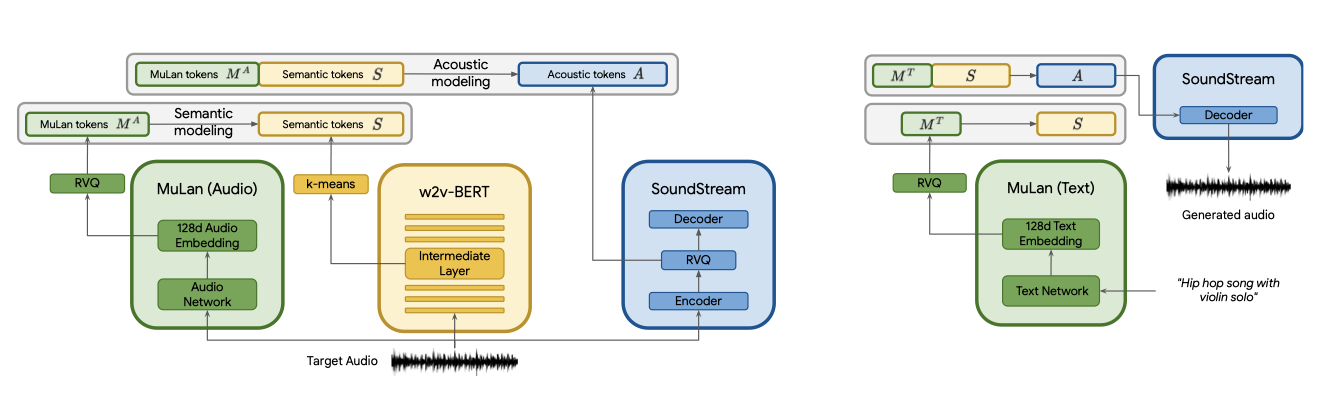
discrete 오디오 표현을 AudioLM과 결합해 텍스트 조건의 음악 생성을 달성한다. 이를 위해, 각 단계가 decoder-only Transformer에 의해 autoregressively 하게 모델링되는 계층적인 sequenceto-sequence 모델링 작업을 제안한다.
첫 번째 단계는 의미 모델링 단계로, MuLan 오디오 토큰에서 의미 토큰 $S$로의 매핑을 학습한다. 이는 분포 $p(S_t | S_{<t}, M_A)$를 모델링함으로써 이루어지며, 여기서 $t$는 시간 단계에 해당하는 시퀀스 내의 위치이다. 두 번째 단계는 음향 모델링 단계로, 음향 토큰 $A_q$는 MuLan 오디오 토큰과 의미 토큰 모두에 의해 조건이 부여되어 예측되며, 이는 분포 $p(A_t | $A_{<t}, S, M_A)$를 모델링한다.
긴 토큰 시퀀스를 피하고자, AudioLM은 음향 모델링 단계를 대략적인 단계와 세부적인 단계로 분할하는 방법을 제안하였으며, 이 연구에서도 이를 따랐다. 대략적인 단계에서는 SoundStream RVQ의 첫 네 단계를, 세부적인 단계에서는 나머지 여덟 단계를 모델링한다.
Experimental Setup
Models
AudioLM의 의미 단계와 음향 단계 모델링에 decoder-only Transformer를 사용한다. 이 모델은 24개 layer, 16개 attention head, 1024의 embedding dimension, 4096의 차원의 feed-forward layer, 0.1의 dropout, 그리고 relative positional embedding으로 구성되어 있으며, 각 단계는 430M의 parameter를 가진다.
Training and Inference
MusicLM의 다른 구성 요소를 학습시키기 위해 사전 학습된 MuLan에 의존한다. SoundStream과 w2v-BERT는 FMA 데이터셋에서, 토크나이저와 의미 및 음향 모델링 단계의 모델은 24 kHz에서 280k시간의 음악을 포함하는 5M 개의 오디오 클립 데이터셋에서 학습된다. 각 단계는 학습 데이터를 여러 번 반복하여 학습하며, 의미와 음향 단계에서는 각각 30초와 10초의 임의 오디오를 사용한다. 세부적인 음향 모델링 단계는 3초 자르기에서 학습된다.
추론 시에는 MuLan이 학습한 오디오와 텍스트 사이의 임베딩 공간을 사용하며, $M_A$를 $M_T$로 대체한다. 그 후, $M_T$가 주어졌을 때 $A$를 얻기 위해 위에서 설명한 단계를 따른다. 모든 단계에서 autoregressive 샘플링을 위해 온도 샘플링을 사용하며, 의미 모델링 단계는 1.0, 대략적인 음향 모델링 단계는 0.95, 세밀한 음향 모델링 단계는 0.4의 온도를 사용한다. 이 값들은 생성된 음악의 다양성과 시간적 일관성 사이의 좋은 균형을 위해 선택되었다.
Evaluation Dataset
MusicLM 평가를 위해 고품질 음악 캡션 데이터셋인 MusicCaps를 준비하였다. 이 데이터셋은 AudioSet의 5.5k 음악 클립과 전문 음악가들의 영어 설명이 포함되어 있다. 각 음악 클립에는 자유 형식의 캡션과 장르, 기분, 템포 등을 설명하는 음악 측면이 포함되어 있다.
MusicCaps는 AudioSet의 오디오 클립과 텍스트 설명을 포함한 AudioCaps를 보완한다. AudioCaps는 음악이 아닌 내용이 포함되어 있지만, MusicCaps는 전문가의 상세 주석이 포함된 음악에만 초점을 맞추고 있다. AudioSet의 학습 및 평가 분할로부터 다양한 장르의 예시를 추출하였으며, 1k 예시로 구성된 장르별 균형 분할도 제공한다.
Metrics
MusicLM을 평가하기 위해, 오디오 품질과 텍스트 설명 충실도라는 음악 생성의 두 가지 중요한 측면을 측정하는 다양한 메트릭을 사용한다.
Fréchet Audio Distance (FAD).
Fréchet Audio Distance는 사람의 인식과 잘 맞는 오디오 품질 지표이다. 이 점수가 낮은 모델은 신뢰할 수 있는 오디오를 생성할 것으로 예상되지만, 생성된 샘플이 제공된 텍스트 설명을 반드시 따르는 것은 아니다.
공개적으로 사용 가능한 두 가지 오디오 임베딩 모델, 즉 음성 데이터에 학습된 Trill 2와 YouTube-8M 오디오 이벤트 데이터셋에 학습된 VGGish 3에 기반한 FAD를 보고한다. 학습 데이터의 차이로 인해, 이 두 모델은 오디오 품질의 다른 측면을 측정하게 될 것으로 예상한다.
KL Divergence (KLD). 텍스트 설명과 음악 클립 사이에는 다대다 관계가 있어, 오디오 파형 수준에서 직접 비교는 불가능하다. 입력 텍스트 충실도를 평가하기 위해, AudioSet에서 다중 레이블 분류를 위해 학습된 LEAF 분류기를 사용하여 생성된 음악과 참조 음악의 클래스 예측을 계산하고, 이들 사이의 KL-Divergence를 측정한다. KL-Divergence가 낮으면, 생성된 음악은 분류기에 따라 참조 음악과 유사한 음향 특성을 가질 것으로 예상된다.
MuLan Cycle Consistency (MCC). 음악-텍스트 임베딩 모델인 MuLan을 사용해 음악-텍스트 쌍의 유사성을 측정한다. MusicCaps의 텍스트 설명과 그에 기반한 생성된 음악에서 임베딩을 계산하고, 이들 간의 평균 코사인 유사성을 MCC 메트릭으로 정의한다.
Qualitative evaluation. 생성된 샘플이 텍스트 설명을 얼마나 잘 따르는지 평가하기 위해 A대 B 인간 평가 작업을 설정하였다. 평가자들은 텍스트 설명과 두 가지 다른 모델에 의해 생성된 음악 샘플을 비교하며, 샘플에 대한 강한, 약한 또는 무관한 선호도를 선택한다. 음악 품질은 이미 FAD 메트릭으로 평가되었으므로, 이를 고려하지 않도록 지시받았다.
참조 음악과 n개의 다른 모델의 출력을 고려해 총 n + 1개의 조건을 설정하고, 이들 간의 쌍을 비교한다. 각 조건이 얼마나 선호되는지를 승리의 수로 계산하여 결과를 집계하고 순위를 매긴다. 샘플은 평가 데이터의 장르 균형 1k 부분 집합에서 선택된다.
Training data memorization. 큰 언어 모델은 학습 데이터의 패턴을 기억할 수 있다. 이를 바탕으로 MusicLM이 음악 세그먼트를 얼마나 기억하는지 연구한다. 학습 세트에서 무작위로 선택한 예시에 대해, MuLan 오디오 토큰과 첫 번째 의미 토큰 시퀀스를 포함한 프롬프트를 모델에 제공한다. greedy decoding을 통해 의미 토큰의 연속을 생성하고, 이를 데이터셋의 대상 토큰과 비교한다. 생성된 토큰과 대상 토큰이 전체 샘플링 세그먼트에서 완전히 일치하는 예시의 비율을 측정한다.
음향적으로 유사한 오디오 세그먼트가 다른 토큰 시퀀스로 이어질 수 있다는 관찰을 기반으로, 근사치 일치를 감지하는 방법을 제안한다. 생성된 토큰과 대상 토큰의 의미 토큰 수 히스토그램을 계산하고, 이들 사이의 일치 비용을 측정한다. 이를 위해 먼저 의미 토큰 쌍 간의 거리 행렬을 계산하고, 그 후 Sinkhorn 알고리즘을 사용해 최적의 전송 문제를 해결한다. 부정 쌍을 구성하고 이들의 일치 비용 분포를 측정해 일치 임계값을 보정한다. 이 임계값은 0.01% 미만의 거짓 긍정 근사치 일치를 초래하는 0.85로 설정된다.
Results
MusicLM을 평가하기 위해, 최근의 기준선인 Mubert와 Riffusion과 비교한다. Mubert API를 쿼리하고 Riffusion 모델에서 추론을 실행하여 오디오를 생성한다. 이 논문과 함께 공개적으로 발표하는 평가 데이터셋인 MusicCaps에서 평가를 수행한다.
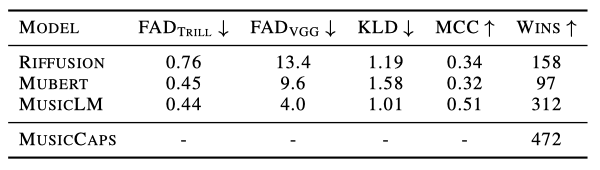
Comparison to baselines. 오디오 품질을 측정하는 FAD 메트릭에 따르면, MusicLM은 Mubert와 Riffusion보다 더 나은 점수를 얻었다. 또한, 입력 텍스트 설명에 대한 충실도를 측정하는 KLD와 MCC에 따라, MusicLM은 기준선에 비해 텍스트 설명에서 더 많은 정보를 캡처하는 능력을 보여준다.
텍스트 충실도 평가를 보완하기 위해 인간 청취 테스트를 진행하였다. 참가자들은 두 개의 10초 클립과 텍스트 캡션을 보고, 어떤 클립이 캡션의 텍스트를 가장 잘 설명하는지 5점 척도로 평가한다. 총 1200개의 평가를 수집하였고, 각 소스는 600개의 쌍별 비교에 참여하였다. MusicLM은 두 가지 기준선에 비해 확실히 선호되지만, 실제 참조 음악과의 차이는 여전히 존재한다. 청취 연구의 자세한 내용은 부록 B에서 확인할 수 있다.
실제 참조가 MusicLM보다 선호되는 경우, 이는 주로 아래의 패턴 때문이다: (1) 캡션은 매우 상세하고, 여러 악기나 비음악적인 측면을 설명한다; (2) 캡션은 오디오의 재생 순서를 설명한다; (3) 부정적인 표현이 사용되는데, 이는 MuLan에 잘 반영되지 않는다.
결론적으로, 이 방법론은 MusicCaps의 자유형 텍스트 캡션에서 세부적인 정보를 잘 포착하며, KLD와 MCC 메트릭은 텍스트 설명에 대한 충실도를 정량적으로 측정하고, 이는 인간의 평가와 일치한다는 것을 확인하였다.
Importance of semantic tokens. 의미론적 모델링과 음향 모델링을 분리하는 것의 유용성을 검증하기 위해, Transformer 모델을 학습시켜 MuLan 토큰에서 음향 토큰을 직접 예측하였다. FAD 메트릭은 비슷하지만, 의미론적 모델링 단계를 제거하면 KLD와 MCC 점수가 악화됨을 발견하였다. 이는 의미 토큰이 텍스트 설명에 따른 순응을 돕는다는 것을 나타낸다. 또한, 샘플을 들어보니 장기 구조에서의 저하가 관찰되었다.
Information represented by audio tokens. 추가 실험을 통해 의미론적 토큰과 음향 토큰이 어떤 정보를 포착하는지 연구하였다. 첫 번째 실험에서는 텍스트 토큰과 의미론적 토큰을 고정하고, 음향 모델링 단계를 반복하여 샘플을 생성하였다. 결과적으로 샘플들은 다양했지만, 장르나 리듬, 멜로디 등에서 공통점을 보였습니다. 두 번째 실험에서는 텍스트 토큰만 고정하고 의미론적 토큰과 음향 토큰을 생성했을 때, 멜로디와 리듬에서 더 큰 다양성을 보였다. 이 연구의 샘플들은 동반 자료에서 확인할 수 있다.
Memorization analysis. 의미론적 토큰 프롬프트의 길이를 변화시킬 때 일치도를 보고합니다. 정확한 일치의 비율은 매우 작은 것을 확인했으며, 근사치 일치(τ = 0.85 사용)의 경우, 프롬프트 길이가 증가함에 따라 일치하는 예시의 비율이 증가한다. 또한, 일치 점수가 낮은 시퀀스는 토큰 다양성이 낮은 것으로 확인되었다. 이러한 패턴은 의미론적 토큰이 정확하게 일치하더라도, 음향 모델링이 생성된 샘플에 추가적인 다양성을 도입한다는 것을 보여준다.
Extensions
Melody conditioning. MusicLM은 텍스트 설명과 함께 허밍, 노래, 휘파람, 악기 연주 등의 형태로 제공되는 멜로디에 기반한 음악을 생성할 수 있도록 확장되었다. 이를 위해, 멜로디는 같지만 음향이 다른 오디오 쌍으로 구성된 데이터셋을 만들고, 공통 임베딩 모델을 학습시켜 같은 멜로디를 가진 오디오 클립의 임베딩이 서로 가까워지도록 하였다.
MusicLM의 멜로디를 추출하기 위해, 멜로디 임베딩을 양자화하고 결과 토큰 시퀀스를 MuLan 오디오 토큰과 연결한다. 추론 과정에서는, 입력 오디오 클립에서 멜로디 토큰을 계산하고 이를 MuLan 텍스트 토큰과 연결한다. 이러한 방식으로, MusicLM은 입력 오디오 클립의 멜로디를 따르면서도 텍스트 설명을 준수하는 음악을 성공적으로 생성할 수 있다.
Long generation and story mode. MusicLM은 시간 차원에서 자기회귀적 생성을 사용하여 학습 시 사용한 것보다 더 긴 시퀀스를 만들 수 있다. 의미론적 모델링은 30초 시퀀스에서 학습되며, 더 긴 시퀀스를 위해 15초 간격으로 진행하고, 15초를 접두사로 사용하여 추가적인 15초를 생성한다. 이 방법으로 몇 분 동안 일관성을 유지하는 긴 오디오 시퀀스를 생성할 수 있다.
소소한 수정을 통해 MusicLM은 시간이 지나면서 텍스트 설명이 변화하는 동안 긴 오디오 시퀀스를 생성할 수 있게 되었다. 이를 스토리 모드라고 부르며, 여러 텍스트 설명에서 $M_T$를 계산하고 15초마다 조건 신호를 변경한다. 이 방법으로, 모델은 텍스트 설명에 따라 음악 컨텍스트를 변경하면서도 템포가 일관되고 의미론적으로 타당한 부드러운 전환을 생성한다.
Conclusions
MusicLM은 텍스트 조건에 충실하면서 몇 분 동안 일관된 24 kHz의 고품질 음악을 생성하는 모델이다. 이 모델은 뮤지션들이 준비한 5.5k 음악-텍스트 쌍의 고품질 데이터셋인 MusicCaps에서 기존 모델을 능가하는 성능을 보여준다.
이 방법의 한계 중 일부는 MuLan으로부터 비롯되며, 이는 모델이 부정을 잘못 이해하고 텍스트에 기술된 시간 순서를 정확하게 따르지 않는다는 점을 포함한다. 또한, 정량적 평가의 추가적인 개선이 필요하며, MCC 점수는 MuLan에 의존하기 때문에 이 방법에 유리하다.
미래의 연구는 가사 생성, 텍스트 조건화 및 보컬 품질 개선, 고수준 노래 구조(서론, 구절, 후렴구 등)의 모델링, 그리고 더 높은 샘플 속도에서 음악 모델링에 초점을 맞출 수 있다.
Broader Impact
MusicLM은 텍스트를 기반으로 고품질 음악을 생성해 인간의 창의적 음악 작업을 돕지만, 여러 위험 요소가 있다. 학습 데이터의 편향이 생성된 샘플에 반영될 수 있으며, 이것은 대표성이 부족한 문화에 대한 음악 생성의 적절성과 문화적 강탈 문제를 불러일으킬 수 있다.
창의적 콘텐츠의 잘못된 사용 가능성을 인지하며, 책임있는 모델 개발 원칙에 따라 의미 모델링에 초점을 맞춘 연구를 수행하였다. 기억된 예시는 극히 적었고, 예시의 1%만 대략적으로 일치하였다. 음악 생성과 관련된 위험을 해결하기 위한 미래 연구의 필요성을 강조하며, 현재 모델 공개 계획은 없다.