Abstract
few-shot learning 예제를 사용하는 대형 언어 모델은 다양한 자연어 작업에서 뛰어난 성능을 보여준다. 이를 더 깊이 이해하기 위해, 540B parameter의 densely activated transformer 언어 모델인 Pathways Language Model(PaLM)을 학습시켰다.
새로운 ML 시스템인 Pathways를 사용해 PaLM을 학습시키고, 수백 개의 언어 이해 및 생성 벤치마크에서 state-of-the-art의 few-shot learning 결과를 달성하였다. PaLM 540B는 다단계 추론 작업과 BIG-bench 벤치마크에서 인간 평균 성능을 능가하는 성과를 보여주었다. 모델 규모가 커짐에 따라 성능이 급격히 향상된 작업도 있었다. 또한 PaLM은 다국어 작업과 소스 코드 생성에서도 강력한 능력을 가지고 있다. bias와 toxicity 대한 분석과 함께, 거대 언어 모델과 관련된 윤리적 고려 사항에 대해 논의하였다.
Introduction
언어 이해와 생성을 위한 대규모 신경망들은 다양한 작업에서 놀라운 결과를 보여주고있다. BERT나 T5 같은 모델들은 대량의 텍스트를 통해 사전 학습되고, 특정 작업에 맞게 미세 조정된다. 이들 모델은 다양한 자연어 작업에서 state-of-the-art를 보여주지만, 모델을 미세 조정하는 데 많은 수의 작업 특정 학습 예제가 필요하고, 일부 모델 parameter를 작업에 맞게 업데이트하는 복잡성이 증가한다는 단점이 있다.
GPT-3는 극도로 큰 autoregressive 언어 모델이 소수의 예측을 위해 사용될 수 있음을 보여주었다. 이 모델은 자연어 작업 설명과 작업 완료 방법을 보여주는 몇 가지 예시만 제공받아 학습된다. 대규모 작업 특정 데이터 수집이나 모델 parameter 업데이트 없이도 매우 강력한 결과를 달성하였다.
GPT-3 이후에도 GLaM, Gopher, Chinchilla, Megatron–Turing NLG, LaMDA와 같은 강력한 대규모 autoregressive 언어 모델들이 개발되어 state-of-the-art를 계속 밀어내고 있다. 이들 모델은 모두 transformer 아키텍처의 변형이며, 모델의 크기 확대, 학습된 토큰 수 증가, 더 깨끗한 데이터셋 사용, 희소 활성화 모듈을 통한 계산 비용 없는 모델 용량 증가 등의 방법으로 개선되었다.
이 연구에서는 780B 개의 고품질 텍스트 토큰에 대해 540B 개의 parameter를 가진 densely activated autoregressive transformer를 학습시키는 언어 모델링 개선을 계속하였다. 이는 새로운 ML 시스템인 Pathways를 사용하여 수천 개의 accelerator chip에서 매우 큰 신경망을 효율적으로 학습시키는 데 성공하였다. 이 새로운 모델인 PaLM은 수백 개의 자연어, 코드, 수학적 추론 작업에서 breakthrough performance를 달성하였다.
이 연구에서 주요 결론은 다음과 같다:
- Efficient scaling 이 연구에서는 새로운 ML 시스템인 Pathways를 대규모로 처음 사용하였다. 이를 통해, 6144개의 TPU v4 칩에서 540B parameter 언어 모델을 이전에는 도달할 수 없었던 효율 수준에서 학습시켰다. 이전의 대부분의 대규모 언어 모델들은 단일 TPU 시스템에서 학습되거나 GPU 클러스터 또는 여러 TPU v3 pods에 걸쳐 확장되었다. 두 개의 TPU v4 Pods에 걸쳐 6144개의 칩으로 PaLM 540B의 학습을 확장하면서 매우 높은 효율성을 달성하였다.
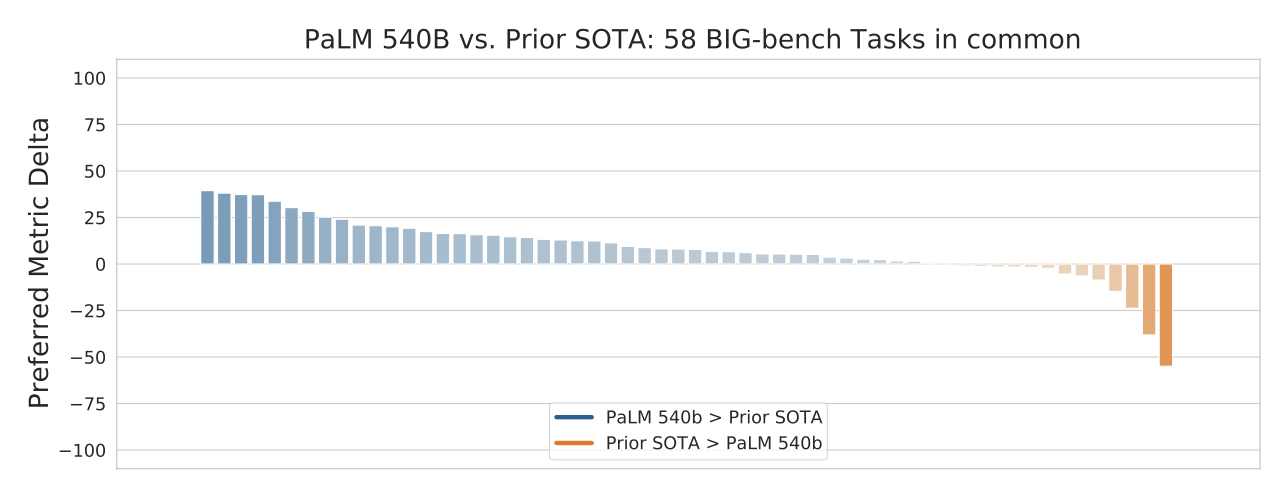
- Continued improvements from scaling 자연어, 코드, 수학적 추론 작업 등 수백 가지 작업에 대해 PaLM을 평가하고, 대부분의 벤치마크에서 상당한 차이로 state-of-the-art를 달성하였다. 이는 대규모 언어 모델로부터의 scaling 개선이 아직도 정체되지 않았음을 보여준다. 가장 널리 평가된 29개의 영어 언어 이해 벤치마크 중 28개에서 최고 작업별 결과에 비해 state-of-the-art를 보여주었다.
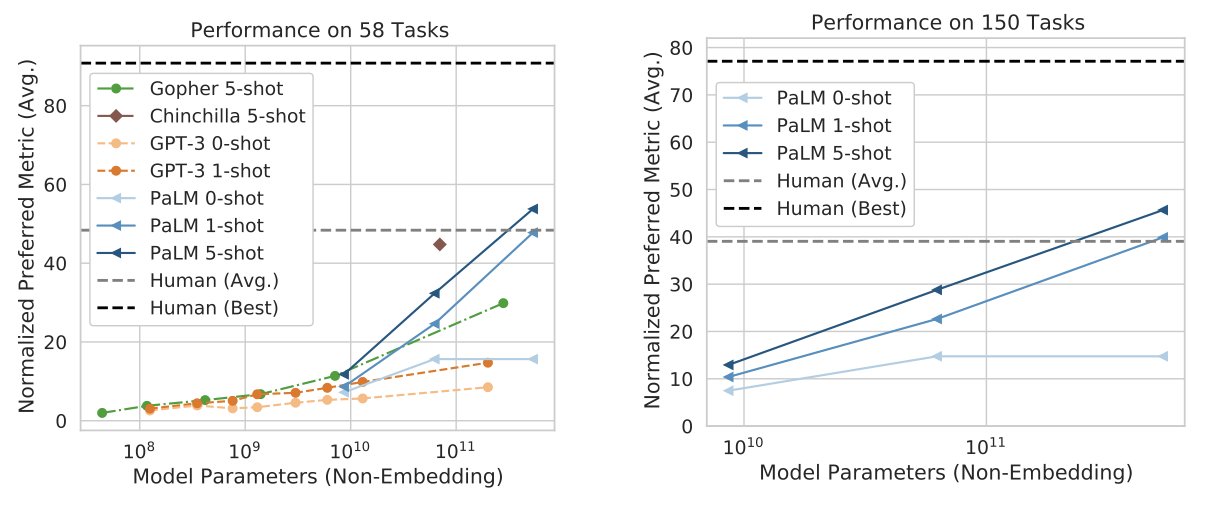
- Breakthrough capabilities 이 연구에서는 다양한 어려운 작업에 대해 언어 이해와 생성에서 breakthrough capabilities를 보여준다. 특히, multi-step 수학적 또는 상식적 추론이 필요한 일련의 추론 작업에 대해 평가하였다. 모델 scaling과 사슬 형태의 생각 유도를 결합하면, 간단한 소수 평가가 넓은 범위의 추론 작업에서 state-of-the-art를 능가하거나 매치할 수 있음을 보여주었다. 또한, 최근 출시된 150개 이상의 새로운 언어 이해와 생성 작업을 포함하는 BIG-bench에서 breakthrough performance을 보여주었다. PaLM이 복잡한 추론 체인을 명확하게 해석하고 설명하는 능력을 탐색하였다.
- Discontinuous improvements 8B, 62B, 540B의 세 가지 다른 parameter 규모에서의 결과를 제시하여 scaling 행동을 이해한다. 일반적으로, 62B에서 540B로의 scaling은 8B에서 62B로의 scaling과 유사한 성능을 가져온다. 그러나 특정 작업에 대해서는, 62B에서 540B로의 scaling이 정확도에서 drastic jump를 가져오는 것을 관찰하였다. 이는 대규모 언어 모델의 새로운 능력이 충분한 규모를 달성하면 나타날 수 있음을 제안한다.
- Multilingual understanding 이 연구에서는 다양한 언어에서의 기계 번역, 요약, 그리고 질문 응답을 포함한 다국어 벤치마크에 대한 철저한 평가를 수행하였다. 비영어 데이터의 비율이 상대적으로 작음에도 불구하고, PaLM 모델은 비영어 요약 작업에서 이전에 미세 조정된 state-of-the-art와의 격차를 메우며, 번역 작업에서 이전의 state-of-the-art를 능가하였다. 다국어 데이터 비율 증가의 영향을 이해하기 위해 추가적인 연구가 필요하다.
- Bias and toxicity distributional bias와 toxicity에 대한 모델 성능을 평가하였다. 성별과 직업에 대한 bias에서, 모델 규모가 커짐에 따라 성능이 개선되었다. 인종/종교/성별 프롬프트 연속성에서는 모델이 스테레오타입을 거짓으로 확증하는 가능성을 보여주었다. toxicity 분석에서는 62B와 540B 모델이 8B 모델에 비해 약간 더 높은 toxicity 수준을 보여주었다. 모델이 생성한 연속성의 toxicity은 프롬프트 텍스트의 toxicity과 높게 상관되었다. 향후 연구에서는 이러한 벤치마크를 비영어 언어로 확장하고 잠재적 위험을 더 철저히 고려할 계획이다.
Model Architecture
PaLM은 다음과 같은 수정을 가진 표준 Transformer 모델 아키텍처의 decoder-only setup으로 사용한다:
SwiGLU Activation MLP 중intermediate activation에 SwiGLU activation을 사용한다. 이는 표준 ReLU, GeLU, Swish activation에 비해 품질을 크게 향상시키기 때문이다. 이는 MLP에서 세 개의 행렬 곱셈이 필요하다는 것을 의미하지만, 이는 품질 개선을 보여준다.
Parallel Layers 각 Transformer block에서 표준 “serialized” 형식 대신 “parallel” 형식을 사용한다. 특히, 표준 serialized 형식은 다음과 같이 작성할 수 있다:
$$ y = x + \text{MLP}(\text{LayerNorm}(x + \text{Attention}(\text{LayerNorm}(x)))) $$
반면에, parallel 형식은 다음과 같이 작성할 수 있다:
$$ y = x + \text{MLP}(\text{LayerNorm}(x)) + \text{Attention}(\text{LayerNorm}(x)) $$
parallel 형식은 MLP와 Attention 입력 행렬 곱셈이 융합될 수 있어 대규모 규모에서 학습 속도를 약 15% 더 빠르게 한다. 실험에서는 8B 규모에서는 약간의 품질 저하가 있었지만, 62B 규모에서는 품질 저하가 없었으므로, 540B 규모에서 parallel layer의 효과는 품질에 영향을 주지 않을 것으로 추정하였다.
Multi-Query Attention 표준 Transformer 형식은 $k$개의 attention head를 사용하며, 각 타임스텝의 입력 벡터는 “query”, “key”, “value” 텐서로 선형적으로 투영된다. 이 방식은 모델 품질과 학습 속도에 중립적인 효과를 가지지만, decoding 시간에 비용 절약을 가져온다. 이는 standard multi-headed attention이 auto-regressive decoding 시에 accelerator 하드웨어에서 낮은 효율성을 보이기 때문이다.
RoPE Embeddings 긴 시퀀스 길이에서 더 나은 성능을 보이는 RoPE 임베딩을 사용한다. 이는 절대적 또는 상대적 포지션 임베딩 대신에 사용되었다.
Shared Input-Output Embeddings 입력과 출력 임베딩 행렬을 공유한다.
No Biases 어떤 dense kernel이나 layer norm에서도 bias를 사용하지 않았다. 이는 큰 모델의 학습 안정성을 증가시키는 것으로 나타났다.
Vocabulary 256k 토큰의 SentencePiece 어휘를 사용하여 학습 말뭉치의 많은 언어를 지원한다. 이 어휘는 학습 데이터에서 생성되었으며, 학습 효율성을 향상시킨다. 어휘는 완전히 손실 없이 되돌릴 수 있으며, 공백을 완전히 보존하고, 어휘 외의 유니코드 문자를 UTF-8 바이트로 분할한다. 숫자는 항상 개별 숫자 토큰으로 분할된다.
Model Scale Hyperparameters

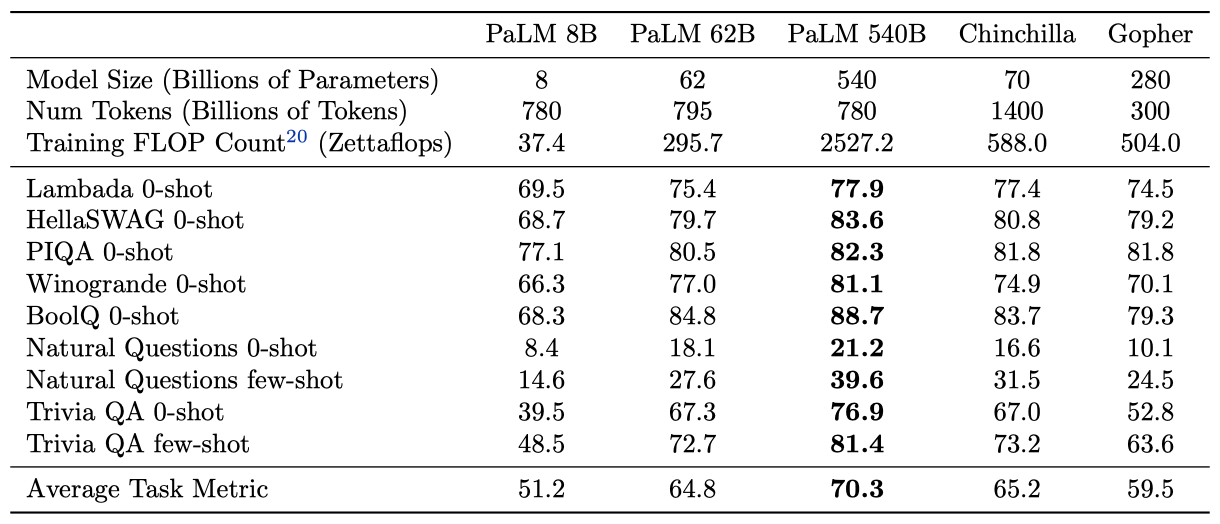
이 연구에서는 540B, 62B, 8B parameter의 세 가지 다른 모델 규모를 비교한다. 이 모델들은 standard dense transformer이므로, 토큰 당 FLOP 수는 parameter 수와 대략적으로 동일하다. 이 모델들은 같은 데이터와 어휘를 사용하여 동일하게 학습되었다.
Training Dataset
PaLM 사전 학습 데이터셋은 다양한 자연어 사용 사례를 대표하는 7800억 토큰의 말뭉치로 구성되어 있다. 이 데이터셋은 웹페이지, 책, 위키백과, 뉴스 기사, 소스 코드, 소셜 미디어 대화를 섞어 만들었다. 모든 모델을 데이터의 1 epoch 학습시키고, 데이터를 반복하지 않도록 혼합 비율을 선택하였다.
사전 학습 데이터셋은 자연어 데이터뿐만 아니라 코드도 포함한다. 이 코드는 GitHub의 오픈 소스 저장소에서 얻은 것이며, 라이선스에 따라 필터링하였다. 또한 파일 이름 확장자에 따라 24개의 일반적인 프로그래밍 언어 중 하나로 제한하였고, 중복 파일을 제거하였다. 이 결과, 196GB의 소스 코드가 생성되었다.

최종 PaLM 데이터셋 혼합물을 생성하는 데 사용된 다양한 데이터 소스의 비율을 보여주며, 데이터 오염을 확인하고, 학습 데이터셋과 평가 데이터 사이의 중복을 분석한다.
Training Infrastructure
학습 및 평가 코드베이스는 JAX와 T5X를 기반으로 하며, 모든 모델은 TPU v4 Pods에서 학습된다. PaLM 540B는 데이터 센터 네트워크를 통해 연결된 두 개의 TPU v4 Pods에서 학습되며, 이는 모델과 데이터 병렬성의 조합을 사용한다. 이 시스템은 파이프라인 병렬성 없이 학습을 6144개의 칩으로 효율적으로 확장할 수 있게 해준다.
이전의 비슷한 규모에서 모델 학습은 두 가지 접근법을 사용했다. LaMDA와 GLaM은 파이프라인 병렬성이나 DCN을 활용하지 않고 단일 TPU 시스템에서 학습되었고, Megatron-Turing NLG 530B는 여러 가지 병렬성을 사용하여 A100 GPU에서, Gopher는 파이프라이닝을 사용하여 DCN-연결된 TPU v3 Pods에서 학습되었다.
파이프라이닝은 일반적으로 DCN과 함께 사용되며, 추가적인 병렬화를 제공한다. 그러나 이는 학습 배치를 “micro-batches"로 분할하지만, 중요한 단점이 있다. 첫째, 많은 장치가 유휴(idle) 상태인 동안 발생하는 시간 오버헤드가 있다. 둘째, 미니 배치 내의 각 마이크로 배치에 대해 메모리에서 가중치를 다시 로드해야 하므로 높은 메모리 대역폭이 필요하다. 이러한 문제를 해결하기 위한 전략을 통해 PaLM 540B의 학습을 6144 칩으로 효율적으로 확장할 수 있었다.
각 TPU v4 Pod는 모델 parameter의 전체 복사본을 포함하며, 각 가중치 텐서는 모델 병렬성과 완전분할 데이터 병렬성을 사용하여 칩으로 분할된다. forward pass에서 가중치가 모두 모아지고, 각 layer에서 activation 텐서가 저장된다. backward pass에서는 나머지 activation이 rematerialized되며, 이는 더 큰 배치 크기에서 더 높은 학습 처리량을 결과로 내기 때문이다.
Pathways 시스템을 사용하여 단일 TPU v4 Pod를 넘어서 학습을 확장한다. PaLM 540B는 Pathways의 클라이언트-서버 아키텍처를 사용하여 pod 레벨에서 데이터 병렬성을 달성한다. Python 클라이언트는 배치의 절반을 각 pod에 할당하고, 각 pod는 gradient를 계산하기 위해 병렬로 계산을 수행한다. 그 후, pod들은 gradient를 원격 pod에 전송하고, 각 pod는 gradient를 누적하고 parameter를 업데이트하여 다음 타임스텝에 대한 parameter를 얻는다.
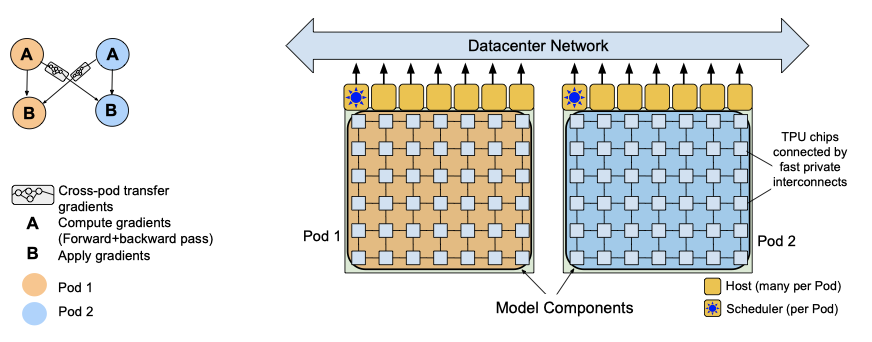
Python 클라이언트는 분할된 데이터플로우 프로그램을 구성하고, 이 프로그램은 각 pod에서 계산과 최적화 업데이트를 수행하고, gradient를 다른 pod로 전송한다. Pathways 시스템의 디자인은 프로그램 실행을 수천 개의 accelerator 칩으로 확장할 수 있게 한다. 이는 원격 서버로 작업을 발송하는 데 걸리는 지연 시간을 감추고, 데이터 전송의 관리 비용을 분산시킨다.
two-way pod-level 데이터 병렬성의 도전적인 측면은 cross-pod gradient 전송에 대한 높은 학습 처리량을 달성하는 것이다. 이는 데이터 센터 네트워크를 통해 모든 호스트가 gradient를 동시에 전송하는 매우 폭발적인 작업량을 초래한다. 이로 인한 도전을 극복하기 위해, 데이터를 작은 청크로 분해하고 다양한 DCN 링크를 통해 라우팅하는 등의 최적화를 수행한다. 이러한 최적화를 통해, 학습 중 단일 pod에 비해 약 1.95배의 처리량을 달성하였다. 이론적인 2배 처리량에 비한 성능 차이는 backward pass와 cross-pod gradient 축소 사이의 중첩이 부족하기 때문에 발생하며, 이 문제는 향후 작업에서 해결할 예정이다.
Training Efficiency
언어 모델의 accelerator 효율성은 대게 hardware FLOPs utilization(HFU)로 측정된다. 이는 주어진 장치에서 관찰된 FLOPs와 이론적인 최대 FLOPs 사이의 비율을 나타낸다. 하지만 이 방법에는 문제가 있다. 첫째, 실행된 하드웨어 FLOPs의 수는 시스템과 구현에 따라 달라진다. 둘째, 하드웨어 FLOPs 측정은 그것들을 세거나 추적하는 방법에 의존적이다. 결국, 학습 시스템의 목표는 가능한 많은 하드웨어 FLOPs를 사용하는 것이 아니라 초당 토큰의 높은 처리량을 달성하는 것이다.
HFU는 LLM 학습 효율성에 대한 일관된 척도가 아니라는 문제점을 인식하였다. 따라서, model FLOPs utilization(MFU)이라는 새로운 효율성 척도를 제안한다. MFU는 관찰된 처리량이 피크 FLOPs에서 운영하는 시스템의 이론적 최대 처리량에 대한 비율이다. 이 척도는 다양한 시스템에서의 학습을 공정하게 비교할 수 있게 해준다.
PaLM 540B 모델의 model FLOPs utilization(MFU)을 제시하고, 이전의 큰 모델들과 비교하였다. MFU는 다양한 모델 parameter 수, 아키텍처, 모델 품질의 맥락에서 모델과 시스템을 비교하는데 유용하다.
GPT-3의 MFU는 21.3%, Gopher는 32.5%, Megatron–Turing NLG 530B는 self-attention 없이 29.7%, 있으면 30.2%이다. 반면, PaLM 540B는 self-attention 없이 45.7%, 있으면 46.2%의 MFU를 달성하였다.
PaLM은 병렬성 전략과 XLA TPU 컴파일러 최적화, 그리고 “parallel layers"의 사용 등으로 인해 높은 accelerator 이용률을 달성하였다. 이로써 PaLM은 LLM 학습 효율성에서 중요한 진전을 나타내는 것으로 보여진다.
Training Setup
모델 학습은 large transformer 언어 모델에 대한 상당히 표준적인 설정을 따랐다:
Weight initialization 커널 가중치는 “fan-in variance scaling"을 사용하여 초기화하며, 입력 임베딩은 layer normalization가 적용되지 않기 때문에 $E ∼ N(0, 1)$으로 초기화된다. 입력과 출력 임베딩 레이어가 공유되므로, pre-softmax 출력 logit은 임베딩 크기의 제곱근의 역수로 스케일링된다.
Optimizer 이 모델은 Adafactor optimizer를 사용하여 학습되었으며, 이는 parameter 행렬의 평균 제곱근으로 learning rate을 조정하는 Adam과 사실상 동일하다. 가중치 초기화가 ${{1}\over{\sqrt{n}}}$에 비례하기 때문에, 이는 learning rate를 수동으로 축소하는 것과 비슷한 효과를 가진다. 하지만, 다른 스케일에서 작동하는 parameter 행렬들이 동일한 비율로 learning rate을 축소하지 않게 하는 이점이 있다.
Optimization hyperparameters 처음 10,000 단계에는 $10^{-2}$의 Adafactor learning rate을 사용하고, 이후에는 단계 번호에 따라 learning rate을 감소시킨다. 모멘텀은 $\beta_1 = 0.9$로 설정하고, 두 번째 순서 모멘트 보간 값은 $\beta_2 = 1.0 - k^{-0.8}$로 계산된다. 이 방법은 희귀 임베딩 토큰의 두 번째 순간을 더 정확하게 추정할 수 있어 안정적이다. 그리고, 모든 모델에서 1.0의 global norm gradient clipping을 사용하며, 학습 중에는 현재 learning rate의 2배에 해당하는 dynamic weight decay를 사용한다.
Loss function 이 모델은 표준 언어 모델링 손실 함수, 즉 모든 토큰의 average log probability를 사용하여 학습된다. 또한, softmax normalizer 값인 $log(Z)$가 0에 가깝게 만드는 auxiliary loss인 $z$ 손실을 사용하며, 이는 학습 안정성을 높이는 데 도움이 된다.
Sequence length 모든 모델은 2048 토큰의 시퀀스 길이로 작동하며, 입력 예제들은 이 길이에 맞춰 연결되고 분할된다. 각 예제는 특별한 [eod] 토큰으로 구분되며 패딩 토큰은 사용되지 않는다.
Batch size 학습 도중 모든 모델의 배치 크기를 점진적으로 증가시킨다. 큰 모델의 경우, 초기에는 배치 크기를 512로 설정하고, 학습이 진행됨에 따라 이를 2048까지 늘린다. 이런 방식은 학습 초기에는 작은 배치 크기가, 후반에는 큰 배치 크기가 더 효율적이기 때문이며, 또한 큰 배치 크기는 TPU 효율성을 높이는데 도움이 된다.
Bitwise determinism 이 모델은 체크포인트에서 완전 재현이 가능하며, 이는 JAX+XLA+T5X가 제공하는 비트 단위 결정적 모델링 프레임워크와, 단계 번호만으로 학습 배치의 내용을 결정하는 결정적 데이터셋 파이프라인 덕분이다. 따라서 모델이 한 번의 실행에서 특정 단계까지 학습되었다면, 그 체크포인트에서 다시 시작해도 동일한 결과를 보장한다.
Dropout 이 모델은 드롭아웃 없이 학습되었지만, 대부분의 경우에는 0.1의 드롭아웃을 사용하여 미세조정 한다.
Training Instability
가장 큰 모델을 학습하면서 gradient clipping이 적용되어 있음에도 불구하고, 불규칙한 간격으로 20번가량 손실이 급증하는 현상을 관찰하였다. 이는 작은 모델에서는 발견되지 않았으며, 큰 모델의 학습 비용 때문에 이 문제를 완화하기 위한 명확한 전략을 세우지 못하였다.
손실 증가 문제를 완화하기 위해, 손실 증가가 시작되기 전 체크포인트에서 학습을 재시작하고, 손실 증가가 관찰된 데이터 배치를 건너뛰는 전략을 사용했다. 이 방법은 손실 증가가 특정 데이터 배치와 모델 파라미터의 특정 상태의 조합으로 발생한다는 것을 보여주며, “bad data” 때문이 아님을 확인하였다.
Evaluation
English NLP tasks
PaLM 모델은 이전 연구와 동일한 29개의 영어 벤치마크를 이용하여 평가한다:
- Open-Domain Closed-Book Question Answering tasks: TriviaQA, Natural Questions, Web Questions
- Cloze and Completion tasks: LAMBADA, HellaSwag, StoryCloze
- Winograd-style tasks: Winograd, WinoGrande
- Common Sense Reasoning: PIQA, ARC, OpenBookQA
- In-context Reading Comprehension: DROP, CoQA, QuAC, SQuADv2, RACE
- SuperGLUE
- Natural Language Inference (NLI): Adversarial NLI
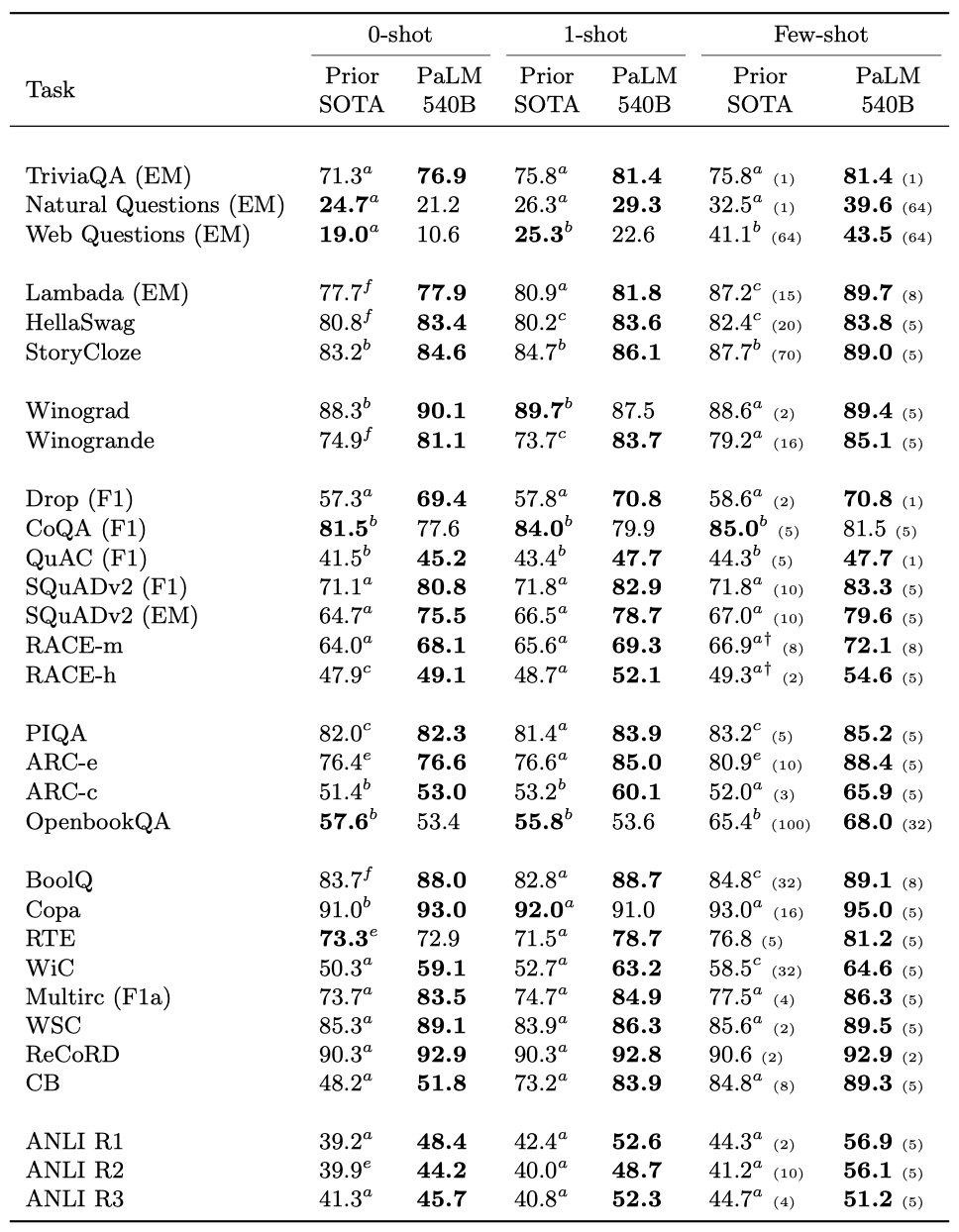
PaLM 540B는 대부분의 작업에서 이전 state-of-the-art를 능가하였다. 특히, 읽기 이해와 NLI 작업에서 더욱 두드러졌다. 이는 모델 크기 뿐 아니라, 사전 학습 데이터셋, 학습 전략, 학습 중 관찰된 토큰 수 등이 중요하게 작용했음을 보여준다.
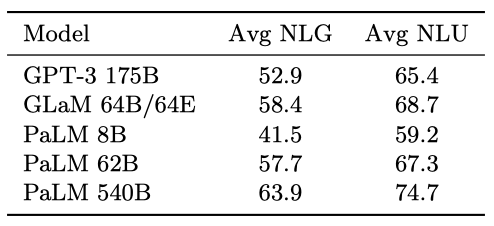
PaLM 540B가 자연어 이해와 자연어 생성 작업에서 평균 점수를 5점 이상 향상시켰다. 특히, PaLM 62B는 GPT-3 175B를 두 카테고리에서 모두 능가하였다.
Massive Multitask Language Understanding

PaLM 모델은 다양한 주제를 다루는 대규모 다중작업 언어 이해 벤치마크에서 평가되었고, 평균 점수를 약 2점 향상시켰다. PaLM 540B는 “Other"을 제외한 모든 카테고리에서 Chinchilla 모델을 능가하였다.
Finetuning
SuperGLUE 벤치마크에서 PaLM 모델을 미세조정하는 실험을 진행했고, 일반적으로 15K 단계 이내에 수렴했다. 이 과정에서는 Adafactor optimizer를 사용하고 batch size는 32였다.

PaLM이 가장 뛰어난 성능을 보여주는 모델과 경쟁력 있게 성능을 내는 것을 보여준다.

또한 few-shot과 미세조정 결과 사이에 여전히 큰 차이가 있다는 것을 보여준다.

PaLM이 최첨단 모델과 경쟁력 있으며, 리더보드에서 가장 뛰어난 성능을 내는 decoder-only autoregressive 언어 모델을 크게 능가하는 것을 보여준다.
BIG-bench
BIG-bench는 대규모 언어 모델에 대한 도전적인 작업을 목표로 하는 벤치마크로, 다양한 언어 모델링 작업을 포함한다. 이 벤치마크에서 PaLM 모델 계열은 few-shot 평가를 수행하였고, 텍스트 작업에 초점을 두었다. 인간의 성능도 같은 지표로 측정되었으며, 이를 통해 “best"와 “average” 인간 성능이 계산되었다.
PaLM 모델 계열은 BIG-bench에서 상당한 성능을 나타냈으며, GPT-3, Gopher, Chinchilla를 크게 능가하였다. 특히, 5-shot PaLM 540B는 동일한 작업을 수행한 인간의 평균 점수보다 높은 점수를 얻었다. 또한, 규모에 따른 PaLM 모델의 성능은 log-linear 행동을 보였으며, 이는 추가적인 스케일링이 성능 향상을 가져올 가능성을 보여준다.
BIG-bench에서 PaLM이 특별히 눈에 띄는 성능을 보인 몇 가지 작업을 강조한다.
goal step wikihow 목표는 이벤트 간의 목표-단계 관계에 대해 추론하는 것이다. Input: ”clean silver,” which step should be done first? (a) dry the silver (b) handwash the silver. Answer: (b) handwash the silver.
logical args 목표는 문단에서 올바른 논리적 추론을 예측하는 것이다. Input: Students told the substitute teacher they were learning trigonometry. The substitute told them that instead of teaching them useless facts about triangles, he would instead teach them how to work with probabilities. What is he implying? (a) He believes that mathematics does not need to be useful to be interesting. (b) He thinks understanding probabilities is more useful than trigonometry. (c) He believes that probability theory is a useless subject. Answer: (b) He thinks understanding probabilities is more useful than trigonometry.
english proverbs 목표는 어떤 속담이 텍스트 구절을 가장 잘 설명하는지 추측하는 것이다. Input: Vanessa spent lots of years helping out on weekends at the local center for homeless aid. Recently, when she lost her job, the center was ready to offer her a new job right away. Which of the following proverbs best apply to this situation? (a) Curses, like chickens, come home to roost. (b) Where there is smoke there is fire (c) As you sow, so you shall reap. Answer: (c) As you sow, so you shall reap.
logical sequence 목표는 논리적인 순서대로 배열하는 것이다. Input: Which of the following lists is correctly ordered chronologically? (a) drink water, feel thirsty, seal water bottle, open water bottle (b) feel thirsty, open water bottle, drink water, seal water bottle (c) seal water bottle, open water bottle, drink water, feel thirsty. Answer: (b) feel thirsty, open water bottle, drink water, seal water bottle.
navigate 목표는 간단한 네비게이션 지시를 따르고, 어디에 도착할지 파악하는 것이다. Input: If you follow these instructions, do you return to the starting point? Always face forward. Take 6 steps left. Take 7 steps forward. Take 8 steps left. Take 7 steps left. Take 6 steps forward. Take 1 step forward. Take 4 steps forward. Answer: No.
mathematical induction 목표는 실제 세계의 수학과 상충하더라도 수학적 귀납법 규칙에 따라 논리적 추론을 수행하는 것이다. nput: It is known that adding 2 to any odd integer creates another odd integer. 2 is an odd integer. Therefore, 6 is an odd integer. Is this a correct induction argument (even though some of the assumptions may be incorrect)? Answer: Yes.
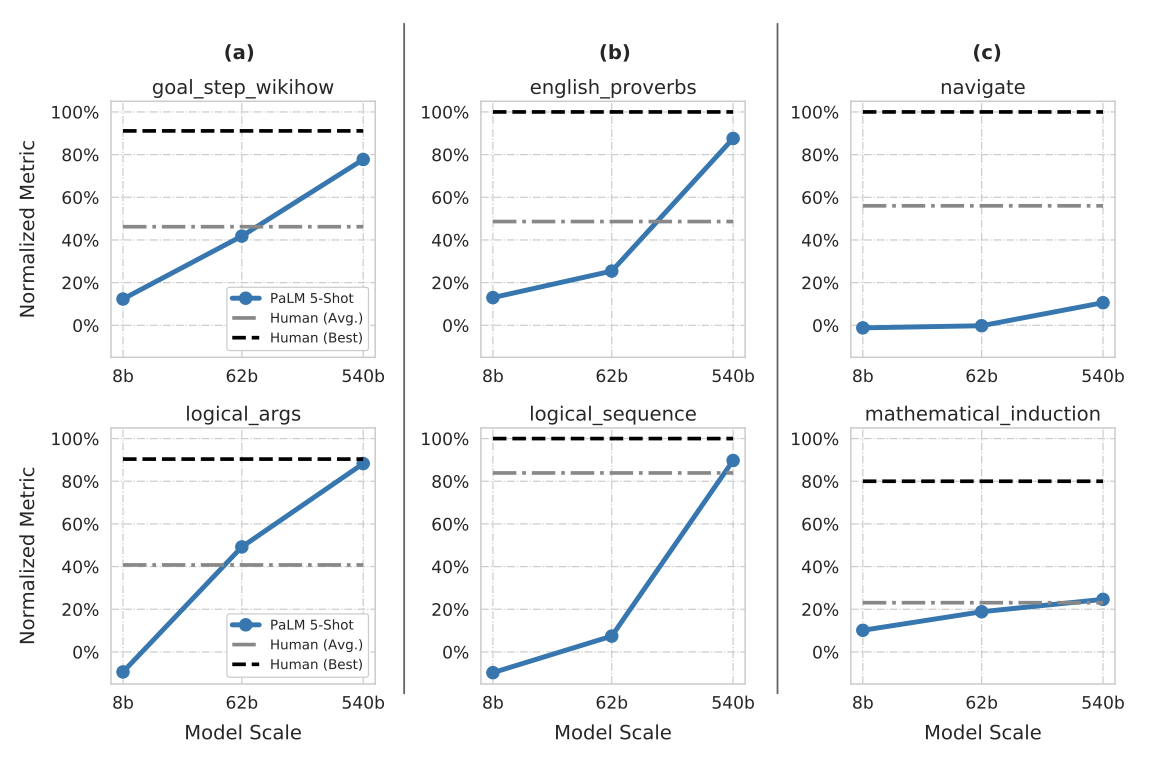
goal step wikihow와 logical args에 대한 성능은 log-linear 스케일링 곡선을 따르며, PaLM 540B 모델은 최고의 인간 성능에 가까워진다. 영어 속담과 논리적 순서에 대한 성능도 강력하지만, 개선 곡선은 불연속적이다. 특히, 특정 규모에 도달하면서만 특정 능력이 나타나는 것이 확인되었다. PaLM 62B에서 25%에서 PaLM 540B의 87%로 크게 개선된 영어 속담 성능은 매우 흥미로운 결과이다.
불연속성에 대한 예로, PaLM의 논리적 순서 작업에서 8b, 62b, 540b 모델에 대한 정확도가 각각 13%, 25%, 87%였다. 이에 따라, 540b에 대한 예상 정확도는 37%였지만, 실제 정확도는 87%로, 불연속성은 +50%였다. 전체 150개 작업 중 25%의 작업에서 불연속성이 +10% 이상, 15%의 작업에서 +20% 이상 나타났으며, 이는 스케일에서의 불연속적인 개선이 일반적인 현상임을 보여준다.
모든 작업에서 규모가 이익을 가져다주는 것은 아니다. 네비게이션과 수학적 귀납 작업에서 PaLM 540B는 PaLM 62B를 살짝 능가하지만, 두 모델 모두 최고의 인간 성능에서는 아직 멀리 떨어져 있다. 이는 작업의 예제 수준의 난이도에 큰 변동성이 있다는 것을 나타낸다. 특히, 수학적 귀납 작업에서는 올바른 가정과 잘못된 가정을 가진 예제들이 있어, 모델들이 가정의 정확성에 대한 문제를 해결하는데 어려움을 겪는 것으로 보인다.
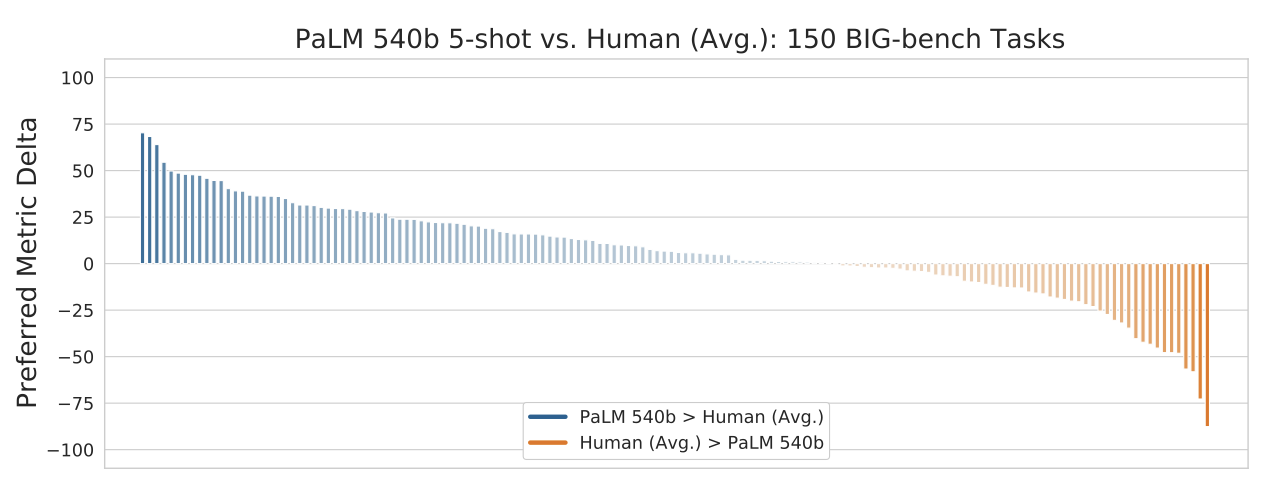
PaLM 540B가 전반적으로 인간 평가의 평균 성능을 능가하지만, 개별 작업의 35%에서는 인간의 평균 성능이 더 높다는 것을 보여준다. 이는 BIG-bench에서 아직도 상당한 개선 여지가 있다는 것을 의미한다.
PaLM 540B는 여러 언어의 표현 및 큰 양의 정보를 기억하는 능력 등을 통해 인간의 평균 성능을 능가하는 일부 작업에서 뛰어난 성과를 보여준다. 그 중에는 원인과 결과를 판단하는 작업도 포함되어 있다.
cause and effect (one sentence no prompt) 하나의 문장으로 된 서브태스크에서, 이벤트들은 두 가지 다른 순서로 하나의 문장으로 결합되며, 각 문장의 log-likelihood는 모델로 점수화된다. 프롬프트는 제공되지 않는다. Input A: I washed the car because my car got dirty. Input B: My car got dirty because I washed the car. Higher-Likelihood Sentence: I washed the car because my car got dirty.
cause and effect (two sentence) 두 문장의 서브태스크에서는, 모델에게 두 가지 이벤트가 보여지고, 어떤 문장이 다른 이벤트를 일으킨 원인에 해당하는지 선택해야 한다. Input: For each example, two events are given. Which event caused the other? (a) My car got dirty. (b) I washed the car. Correct Prediction: (a) My car got dirty.
모든 PaLM 모델이 한 문장 프롬프트 없는 작업에서 잘 수행되었고, 특히 8B 모델은 80% 이상의 정확도를 보여주었다. 그러나 두 문장 버전의 작업에서는 작은 모델의 성능이 떨어졌다. 대신 540B 모델은 이 작업에서 90% 이상의 높은 정확도를 보여, 대규모 모델이 언어 모델링 능력을 향상시킬 수 있음을 입증하였다.

24개의 BIG-bench 작업 중 가벼운 평가 대상인 BIG-bench Lite의 상세 평가 결과를 보여준다. 일부 작업들은 해결되었거나 거의 해결된 상태이지만, 인간 평가의 최고 성능 점수에 비해 다른 일부 작업은 아직 해결되지 않았다.
BIG-bench 데이터를 모델이 암기하여 성과를 달성한 것이 아닌지 확인하기 위해 여러 단계를 거쳤다. BIG-bench 작업 파일의 고유한 canary 문자열이 PaLM 학습 데이터에 없음을 확인했고, BIG-bench 데이터셋은 학습 데이터 수집 시점에 인터넷에 없었다. 대부분의 BIG-bench 작업들은 새로운 벤치마크이며, 모델의 우수한 성능을 보인 작업들을 임의로 점검하여 정보 유출이 없음을 확인하였다.
Reasoning
PaLM은 여러 단계의 산술이나 상식적인 논리적 추론을 필요로 하는 추론 작업에서 평가된다. 언어 모델은 다양한 작업을 수행할 수 있지만, 여러 단계의 추론을 필요로 하는 작업을 수행하는 데에는 어려움이 있다. 이 작업에서는 두 가지 주요 추론 벤치마크 카테고리를 평가한다.
Arithmetic reasoning 이 작업들은 대부분 초등학교 수준의 자연어 수학 문제를 포함하며, 여러 단계의 논리적 추론이 필요하다. 수학은 대체로 간단하며, 어려운 부분은 자연어를 수학식으로 변환하는 것이다. 이 연구에서는 모델 자체가 수학을 수행하는 계산기 형태와 직접 추론 형태를 모두 평가했하였다. Input: Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? Answer: The answer is 11.
Commonsense reasoning 이 작업들은 강한 세계 지식을 필요로 하는 질문 응답 작업이며, 세계에 대한 여러 논리적 추론을 연결하는 것을 필요로 한다. 이는 단순히 사실에 기반한 질문 응답이 아니다. Input: Q: Sean was in a rush to get home, but the light turned yellow and he was forced to do what? Answer Choices: (a) take time (b) dawdle (c) go slowly (d) ocean (e) slow down Answer: The answer is (e) slow down.
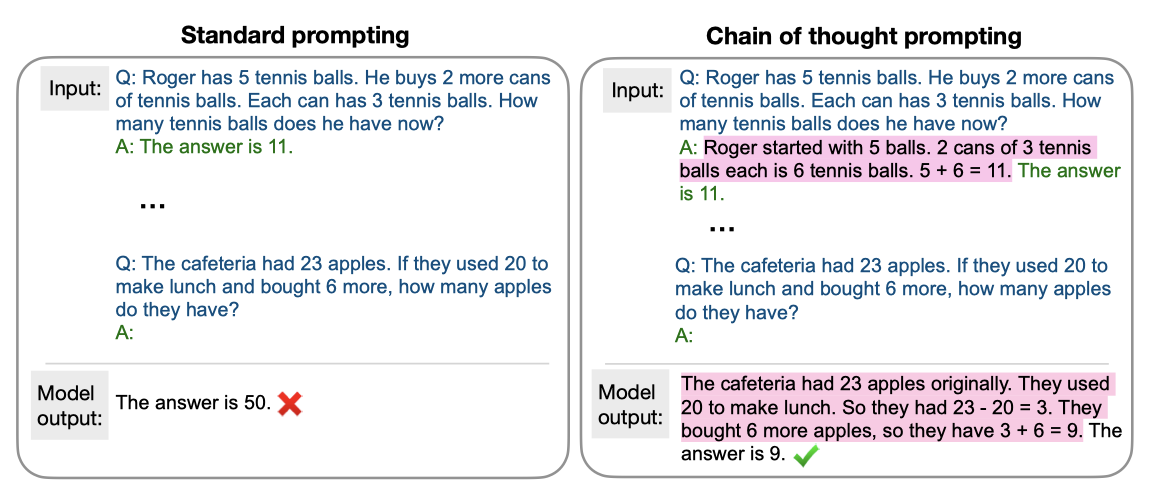
최근 연구들은 대형 언어 모델이 최종 답변을 생성하기 전에 중간 추론 단계를 생성하면 정확도가 크게 향상될 수 있음을 보여주었다. 이 기술을 “chain-of-thought” 프롬프팅이라고 부릅니다. few-shot 설정에서, 중간 추론 단계는 수동으로 작성되고, 모델은 테스트 예시에 대한 자신의 “chain-of-thought"을 생성한다. 생성된 “chain-of-thought"은 오류 분석과 모델 해석에 유용할 수 있지만, 평가에는 최종 답변만 사용된다.
Results
이 연구에서는 모델 규모와 “chain-of-thought” 프롬프팅만으로도 다양한 산술 및 상식 추론 작업에서 최첨단의 정확도를 달성할 수 있음을 보여준다. 이전의 많은 연구들은 도메인 특정 아키텍처, 작업 특정 미세조정, 작업 특정 검증자를 결합했지만, 이 연구에서는 단순히 few-shot 프롬프팅을 통해 작업들을 표현했다. 산술 추론 데이터셋의 경우, 사후 외부 계산기를 사용해 모델 예측을 보강했지만, 이는 어떤 데이터셋에서도 성능을 5% 이상 향상시키지 않았다.
“chain-of-thought” 프롬프팅을 사용해, PaLM의 성능을 산술 데이터셋인 GSM8K, SVAMP, MAWPS, AQuA와 상식 추론 데이터셋인 CommonsenseQA와 StrategyQA에서 평가하였다. 이 프롬프팅 설정은 오직 8-shot 예시만을 사용한다.

GSM8K에서 PaLM의 결과를 강조하며, 이전 state-of-the-art인 Cobbe et al. (2021)이 모델 미세조정, “chain-of-thought” 프롬프팅, 외부 계산기, 작업 특정 검증자를 사용하였다. 외부 계산기와 결합된 8-shot “chain-of-thought” 프롬프팅을 사용한 PaLM 540B는 58%의 성능을 달성해 이전 state-of-the-art인 55%를 능가하였다. 이는 “chain-of-thought” 없는 PaLM 540B와 “chain-of-thought"이 있는 PaLM 62B를 크게 능가하였다. PaLM 62B 모델이 잘못 처리한 문제들은 대체로 의미 이해, 한 단계 누락, 그리고 다른 오류들에 속하며, 540B 모델 크기로 확장하면 이러한 오류들의 대부분이 수정되었다.
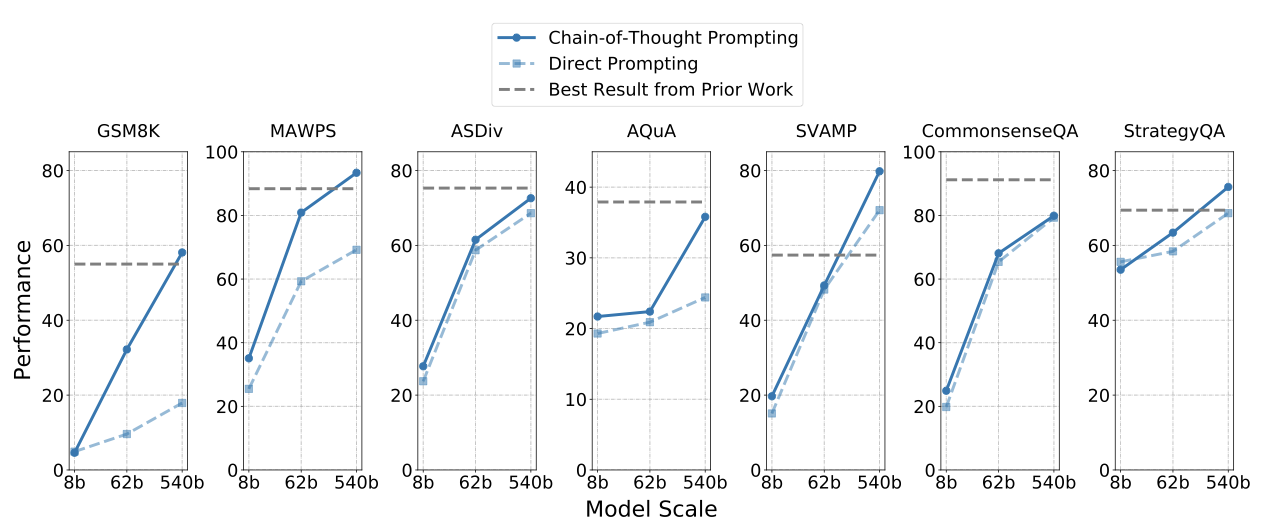
7개의 추론 데이터셋에서, PaLM 540B+“chain-of-thought"을 이용한 8-shot 예측은 4개의 작업에서 최고의 정확도를 달성하였으며, 나머지 3개의 작업에서는 state-of-the-art에 근접한 결과를 보여주었다. GSM8K에는 중간 추론 단계가 포함되었지만 다른 벤치마크에는 포함되지 않았다. state-of-the-art과 모델 확장이 모든 작업에서 크게 도움이 되었으며, 두 기술 없이는 PaLM이 한 가지 작업에서만 최고 수준을 달성했을 것이다. 데이터 오염이 없었음을 n-gram 겹침 분석을 통해 확인하였다.
Code Tasks
최근 연구에서 대형 언어 모델이 경쟁 프로그래밍, 코드 완성, 자연어 명세에서 프로그램 합성 등의 코딩 작업에 유용함이 보여졌다. 이번 섹션에서는 PaLM 모델이 다양한 코딩 작업에서 뛰어난 결과를 달성하는 것을 보여준다.
Text-to-code. 자연어 설명이 주어진 상태에서 코드를 작성하는 세 가지 작업을 고려한다. HumanEval과 MBPP 데이터셋에서는, 모델에게 몇 문장의 영어 설명과 소량의 입력-출력 예시가 주어지며, 주로 단일 함수인 짧은 파이썬 프로그램을 생성하는 것이 목표이다. 또한, GSM8K 데이터셋에서 파생된 GSM8K-Python 작업을 소개한다. 이 작업에서는 올바른 답을 제공하는 대신 올바른 해결책을 반환하는 파이썬 프로그램을 생성하는 것이 목표이다. 데이터셋의 문제 중 네 개를 few-shot 예시로 사용하기 위해 수동으로 파이썬 프로그램으로 변환하였다.
Code-to-code. TransCoder는 C++ 프로그램을 파이썬으로 번역하는 작업이다. 데이터셋에서 Python과 C++ 모두에 나타나는 함수들을 수집하고, 이 중 세 가지 다른 유형의 함수를 few-shot 프롬프트로 사용하며, 나머지는 테스트 세트를 만드는 데 사용하였다. 또한, 컴파일에 실패하는 C 프로그램을 성공적으로 컴파일할 수 있도록 수정하는 DeepFix 코드 수리 작업에서도 평가하였다. 결함 있는 코드에 대한 컴파일러 오류를 모델에 제공하고, 1260개의 프로그램에 대해 테스트하였다.
pass@k 메트릭을 사용해 결과를 보고하며, 이는 모델이 $k$개의 코드 샘플을 제공하고 그 중 하나라도 문제를 해결하면 문제가 해결된 것으로 간주한다. 간단히 문제를 해결하는 샘플의 비율을 보고하며, 이를 측정하기 위해 MBPP와 GSM8K의 테스트 데이터를 사용한다. 1개의 샘플일 경우 greedy decoding을, 그 이상일 경우 nucleus sampling을 사용한다.
PaLM 모델을 LaMDA 137B 파라미터 모델과 초기 Codex 모델 12B와 비교한다. LaMDA는 GitHub의 코드에 대해 학습되지 않았지만, 코드 관련 웹 문서를 일부 포함하여 프로그램 합성 능력을 가지며, Codex 모델은 HumanEval 데이터셋에서의 결과만을 보고한다.
다른 데이터셋에서 Codex 결과를 얻기 위해, OpenAI Davinci Codex API를 사용했다. 이는 2021년 9월 1일부터 2022년 3월 10일까지 진행되었고, 가장 최신 버전인 Davinci 모델 버전 1을 사용했다. Davinci Codex 모델에 대한 많은 정보는 공개되지 않아 성능 차이의 원인을 이해하는 것은 어렵지만, 이 비교는 고려하는 작업의 본질적인 어려움을 이해하는 데 유용하다.
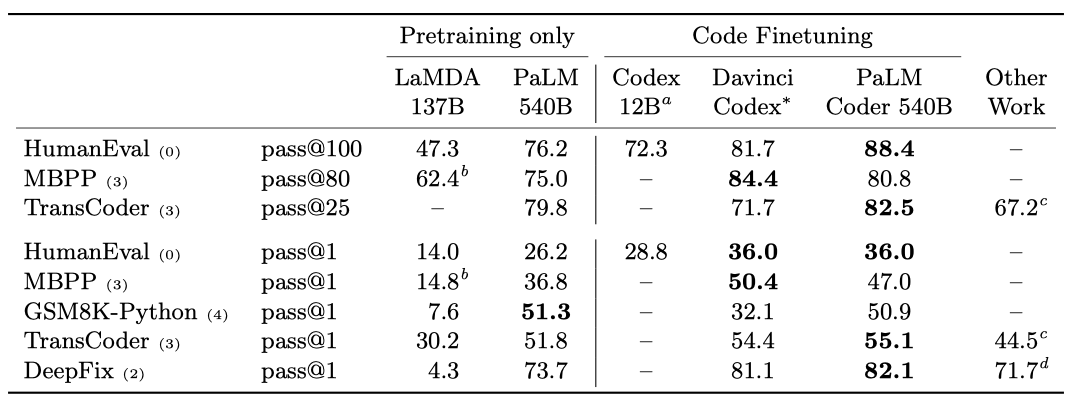
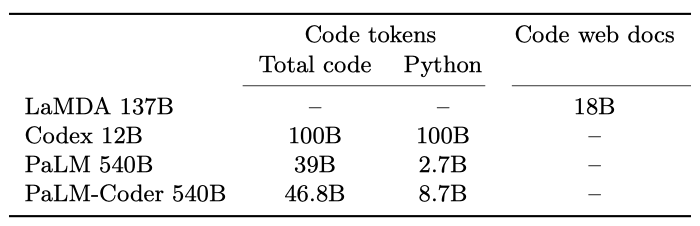
Datasets PaLM 모델은 학습 세트에 GitHub 코드를 포함하며, 총 39B 개의 코드 토큰이 사전 학습 데이터셋에 있다. Python 프로그래밍을 테스트하는 평가를 위해, ExtraPythonData라는 추가 데이터셋을 수집했고, 이는 사전 학습에 사용되지 않은 GitHub에서 5.8B 개의 토큰을 수집한 것이다. 이 데이터는 Java, HTML, Javascript, Python, C, PHP, C#, C++ 등의 언어를 포함하고 있다.
PaLM 540B PaLM 모델은 모든 작업에서 LaMDA보다 높은 성능을 보여주며, HumanEval에서는 Codex 12B와 비슷한 수준이다. 이는 동일한 모델이 코드와 자연어 작업 모두에서 뛰어난 성능을 보여주는 첫 번째 큰 언어 모델이라는 점에서 중요하다. PaLM은 Python 코드 토큰 약 2.7B 개로 학습되었는데, 이는 Codex 모델의 Python 토큰 1000억 개에 비해 50배 적다. 그럼에도 불구하고 PaLM은 비슷한 성능을 보여주어, 다른 프로그래밍 언어와 자연어 데이터로부터의 전이와 큰 모델이 작은 모델보다 효율적일 수 있다는 것을 보여준다.
PaLM-Coder PaLM 모델을 Python 코드와 다양한 언어의 코드, 그리고 자연어에 대해 미세 조정한 결과, PaLM-Coder 540B의 성능이 크게 향상되었다. 이는 미세 조정을 하지 않은 모델에 비해 HumanEval에서 +12%, MBPP에서 +5%의 절대적인 성능 향상을 보여주었다. 또한, 모델의 규모가 증가함에 따라 성능이 계속 향상되는 것을 확인하였다.
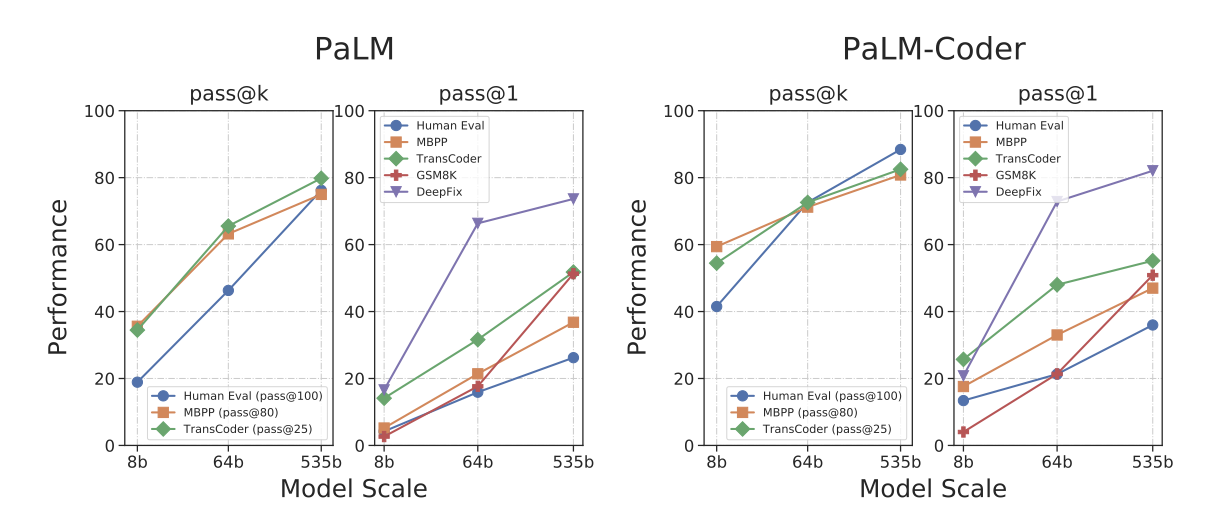
GSM8K-Python 데이터셋에 대해, PaLM-Coder 540B는 8-shot 프롬프트에서 pass@1 점수 57.5를 얻었고, 반면에 PaLM 540B 모델은 pass@1 점수 58.1을 달성하였다.
DeepFix Code Repair PaLM-Coder 540B 모델은 DeepFix 코드 수정 작업에서 82.1%의 컴파일률을 달성하여 뛰어난 성능을 보여주었다. 이는 이전 작업에서 달성한 71.7%보다 높은 결과이다. 프롬프트는 다양한 일반적인 오류를 포함한 두 쌍의 깨진 및 수정된 C 프로그램을 손으로 작성하였으며, 이후 모델이 수정된 전체 코드를 예측하게 하였다.
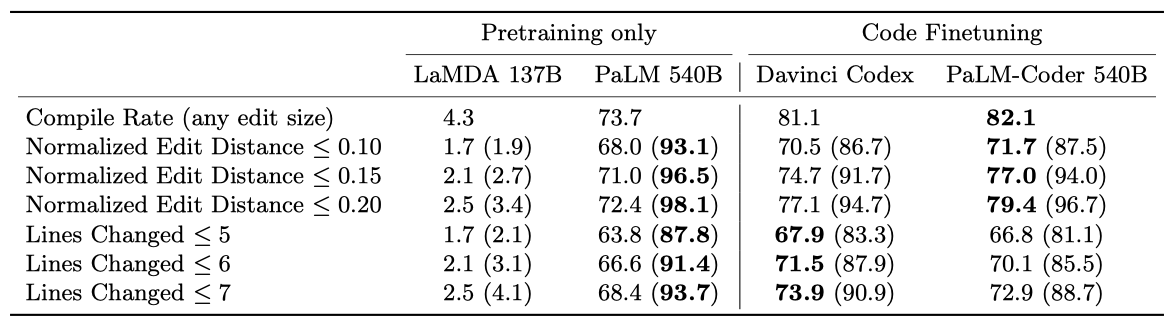
코드 수정에서는 이상적으로 깨진 코드의 작은 부분만 수정하고 싶기 때문에 모델이 변경한 코드의 양을 평가하는 것이 중요하다. PaLM은 가장 작은 편집을 생성하는 반면, PaLM-Coder는 작은 정규화된 편집 거리를 가진 편집에 대해 가장 높은 성공률을 보여주었다. 반면에 Davinci Codex는 변경된 라인 수가 적은 편집에서 가장 높은 성공률을 보였다. 이는 PaLM-Coder가 더 많은 라인에 대해 적은 수의 문자를 변경하는 경향이 있음을 의미한다.
Discussion 소프트웨어 개발에서 언어 모델 기반 시스템을 사용할 때, 생성된 코드가 잘못되거나 미묘한 버그를 도입할 위험이 있다. 개발자들은 제안된 코드를 프로그램에 추가하기 전에 검토해야 하지만, 항상 미묘한 버그를 찾을 수는 없다. 코드 제안은 테스트 스위트로 확인할 수 있지만, 소수의 테스트 케이스로부터 솔루션이 기능적으로 올바르다는 것을 추론하는 것은 항상 안전하지 않다. 이에 따라, 기능적 정확성에 대한 더 철저한 테스트가 필요하다.
기능적 정확성은 소스 코드 품질의 한 가지 측면일 뿐이며, 언어 모델이 생성한 코드 제안은 읽기 쉽고, 견고하고, 빠르고, 안전해야 한다. DeepFix는 PaLM-Coder의 현재 예측과 관련된 문제를 보여주는데, 수정된 프로그램은파일되지만 입력의 형식과 크기에 대한 가정에 의존하기 때문에 반드시 안전한 것은 아니다. 이러한 제안은 더 일반적인 상황에서는 원치 않을 수 있다. 개발자가 제안된 코드를 이해하고 신뢰하는 것은 여전히 해결되지 않은 문제이며, 가독성과 보안성을 평가하는 이전의 연구가 있지만, 이 분야는 아직 초기 단계에 있다.
Translation
기계 번역은 텍스트를 한 언어에서 다른 언어로 변환하는 작업이다. GPT-3 같은 거대 언어 모델들은 병렬 텍스트에 대해 명시적으로 학습받지 않았음에도 불구하고 번역 능력을 보여주었다. 이번 섹션에서는 다양한 언어 쌍에 대해 PaLM의 번역 능력을 평가하며, 이 과정에서 WMT에서 제공하는 언어 쌍을 주로 사용할 예정이다.
English-centric language pairs 이전 모델들이 주로 다루었던 전통적인 언어 쌍은 영어를 포함하고, 병렬 데이터의 양에 따라 고자원, 중자원, 저자원으로 구분한다. 이번 분석에서는 WMT'14의 영어-프랑스어(고자원), WMT'16의 영어-독일어(중자원), 그리고 WMT'16의 영어-루마니아어(저자원)를 언어 쌍으로 사용한다.
Direct language pairs 번역 시스템이 영어를 거치지 않고 어떤 언어 쌍이든 직접 번역하는 능력이 점점 중요해지고 있다. 이를 테스트하기 위해, 프랑스어와 독일어 사이의 직접 번역 능력을 WMT'19 데이터를 사용해 확인한다.
Extremely-low resource language pairs 모든 언어 쌍은 병렬 데이터가 없어 제로-리소스 상태이다. 그러나 단일 언어 데이터가 적은 언어, 예를 들어 이 연구에서 선택한 카자흐스탄어는 흥미로운 점이 있다. 프랑스어와 독일어는 각각 240억, 260억의 토큰을 가지고 있는 반면, 카자흐스탄어는 1.34억 토큰만 가지고 있다. 이를 평가하기 위해 WMT'19의 영어-카자흐스탄어를 사용하였다.
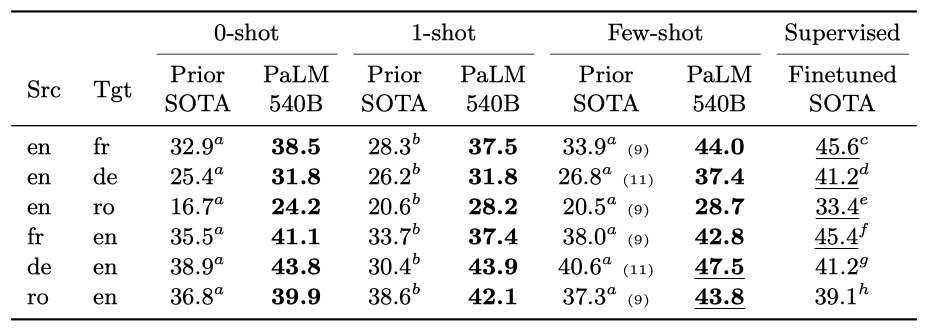
- Evaluation on English-centric language pairs 전통적인 영어 중심 언어 쌍에서 0-shot, 1-shot, few-shot 설정에서 PaLM을 평가하였다. 이 모델은 GPT-3와 FLAN과 같은 다른 모델들을 능가하며, 때때로 최대 13 BLEU 점수 차이를 보여주었다. 독일어-영어와 루마니아어-영어에서는 감독된 기준선을 능가했지만, 이 기준들이 최근 변경된 WMT 작업에 따라 오래되었을 수 있음을 인정한다.
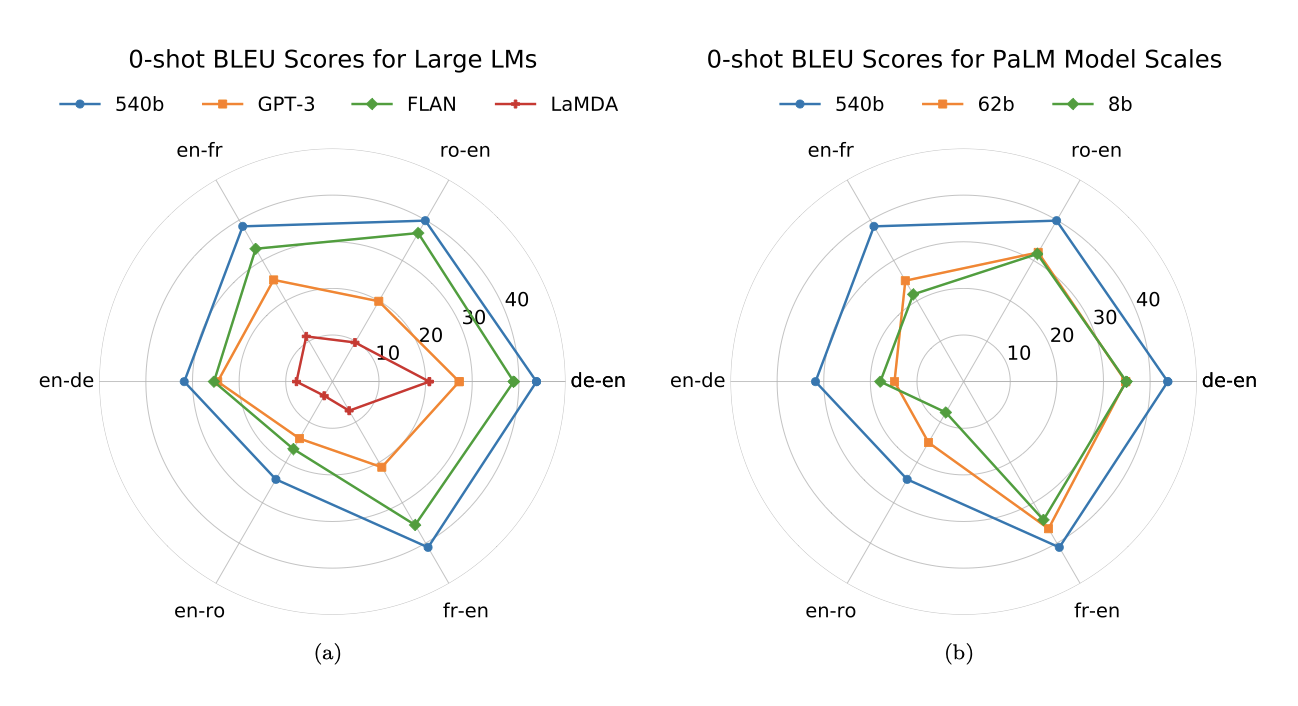
모델 크기를 8B에서 62B, 그리고 540B로 확대하면서 0-shot 번역의 결과에서 급격한 BLEU 점수 상승이 관찰되었다. 특히, 영어-독일어는 13 BLEU, 영어-프랑스어는 17 BLEU 증가를 보였습니다. 이는 “power law” 법칙에 따르지 않는 현상이다.
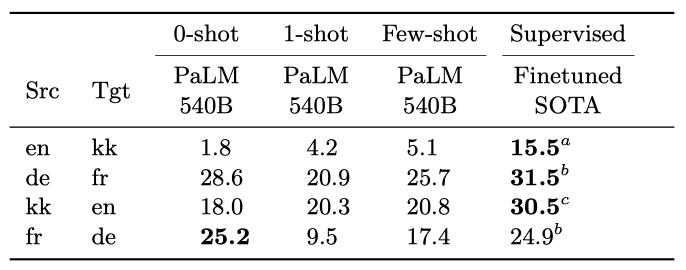
- Evaluation on direct and extremely-low resource language pairs PaLM은 직접적이고 극도로 저자원 언어 쌍에서의 성능을 평가하였다. WMT'19에서 가장 높은 점수를 받은 제출물을 활용하였다. 이 도전적인 상황에서 PaLM은 프랑스어-독일어에서만 지도 성능을 맞출 수 있었지만, 독일어-프랑스어와 카자흐스탄어-영어에서는 강력한 성능을 보여주었다.
Further findings and analysis
결과는 다음과 같은 관찰로 정리할 수 있다:
Translation quality is better when translating into English rather than out of English. 모든 영어 중심 언어 모델에서 관찰되는 공통적인 패턴이며, PaLM의 성능을 살펴보면서 비슷하게 나타난다. 다국어 데이터를 우선시하면 이 효과가 완화될 것으로 추정한다.
Prompts can deliver even more value than a single example. 대부분의 경우, 언어 이름을 사용하여 번역을 유도하는 0-shot 설정이 입력-출력 예시만을 사용하는 1-shot 및 few-shot 설정보다 더 높은 성능을 보여주었다.
Generalist models relying solely on self-supervision can match specialized models at smaller scales. 대부분의 전용 번역 기준은 parameter가 1B개 미만으로, 가장 큰 PaLM 설정보다 두 자릿수가 작다. 그러나, 대형 번역 모델이 다양한 작업에 적응할 수 있음을 확인했으므로, specialist도 generalist로 활용될 수 있다. 이로 인해, 자원이 풍부한 상황에서는 specialist를 학습시킬지, 아니면 generalist를 학습시킬지에 대한 질문이 제기된다.
Multilingual Natural Language Generation
자연어 생성은 텍스트나 비언어적 정보를 입력으로 받아 이해하기 쉬운 텍스트를 자동 생성하는 과제이다. 그러나 과거에는 비슷한 크기의 모델들에 대해 few-shot 조건부 자연어 생성에 대한 탐구가 없었다. 대형 언어 모델들(GPT-3, GLaM, Gopher, LaMDA, Megatron-Turing NLG) 중 어느 것도 이런 과제에 대한 결과를 보고하지 않았다.
이 연구는 few-shot 모델링을 위한 첫 번째 대형 언어 모델 벤치마크를 제시하며, 비교 대상으로 LaMDA 137B를 사용하였다. 이 모델은 이전 연구에서 벤치마크 결과를 보고하지 않았지만 테스트는 할 수 있었다.
미세 조정을 위한 이전 최고 성능은 주로 T5, mT5, BART 등의 encoder-decoder 모델에서 나왔다. 이들 모델은 PaLM보다 작지만, 채우기를 위해 학습된 모델들은 종종 더 큰 decoder-only 언어 모델을 능가한다. 따라서, 이 연구에서는 대규모 모델이 decoder-only 언어 모델의 약점을 보완할 수 있는지를 중요하게 비교하고 있다.
Data 우리는 PaLM을 GEM 벤치마크의 여섯 가지 작업(세 가지 요약, 세 가지 데이터-텍스트 생성)으로 평가하였다. 이는 체코어, 영어, 독일어, 러시아어, 스페인어, 터키어, 베트남어 등의 언어를 포함한 데이터셋을 사용하였다.
- MLSum 다중 문장으로 뉴스 기사를 요약 [독일어/스페인어]
- WikiLingua WikiHow의 단계별 지시사항을 매우 간결한 문장으로 요약 [영어/스페인어/러시아어/터키어/베트남어 → 영어]
- XSum 한 문장으로 뉴스 기사를 요약 [영어]
- Clean E2E NLG 주어진 키-값 속성 쌍을 바탕으로, 레스토랑을 한 두 문장으로 설명 [영어]
- Czech Restaurant response generation 대화 맥락과 대화 행동 표현을 바탕으로, 스마트 어시스턴트가 제공할 응답 생성 [체코어]
- WebNLG 2020 주어-동사-목적어 삼중체를 문법적이고 자연스럽게 한 문장 이상으로 표현 [영어/러시아어]
모델의 추론 시간을 줄이기 위해, 테스트 세트가 5,000개를 초과하면 균일하게 샘플링한다.
Metrics Gehrmann et al. 의 제안에 따라 ROUGE-2, ROUGE-L, BLEURT-20 결과를 보고하며, 이 섹션의 본문은 ROUGE-2의 F-측정에 초점을 맞춘다.
Few-shot evaluation methodology PaLM은 few-shot 추론에 사용되며, 작업 특정 프롬프트를 입력에 연결하고 출력 프롬프트를 출력에 추가한다. 요약을 위한 긴 입력은 2048 토큰으로 줄이고, few-shot 예시들은 두 줄의 공백으로 분리한다. 모든 few-shot 예시들은 훈련 데이터에서 무작위로 추출된다.
Finetuning methodology 미세조정 시, decoder만 사용하며, 입력과 목표를 연결하지만, 손실은 목표 부분에서만 계산한다. 연결된 시퀀스는 2048 토큰으로 잘라내고, 목표를 위해 512 토큰을 예약한다. 이 과정은 요약 작업에서만 필요하다.
PaLM 미세조정은 $5×10^-5$ 의 learning rate와 optimizer 리셋을 사용하며, 검증 세트에서 가장 좋은 ROUGE 점수를 보인 모델을 선택한다. 추론은 $k = 10$의 top-k 샘플링으로 수행되고, T5 XXL 기준선은 PaLM과 동일한 parameter로 미세조정하며, beam size 4의 beam-search를 사용해 디코딩한다.
Results
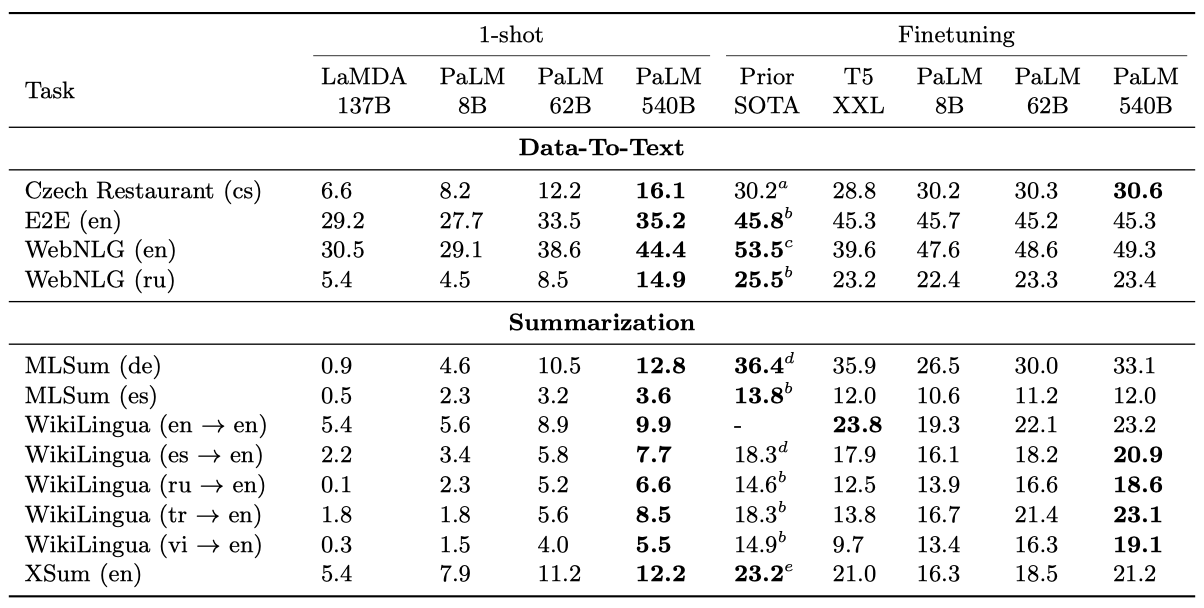
1-shot과 미세조정의 비교는 ROUGE-2의 F-측정을 사용한다.
이 연구는 few-shot 모델링에 초점을 맞추고 있고, 이러한 작업에 대한 공개된 few-shot 결과는 없지만, 이 결과들로부터 몇 가지 흥미로운 교훈을 얻을 수 있다:
Effectiveness of finetuning 요약 작업에서, 미세조정된 540B PaLM은 모든 영어 생성 작업에서 최상의 성과를 보여주며, 이는 그것의 대규모 스케일을 통해 아키텍처적 단점을 극복할 수 있다는 것을 보여준다. 62B 버전도 최상의 결과에 가깝고, 540B는 그것을 초과한다. decoder 전용 LM의 미세조정이 작업 특정 훈련 데이터가 많을 때 모든 작업에 대한 최적의 접근법이 아닐 수 있다는 것을 인지하고 있지만, 이것이 few-shot 예측에 대한 중요한 상한선 역할을 한다고 믿는다.
Generation quality of English vs. non-English PaLM은 6개의 요약 작업 중 4개에서 새로운 미세조정 state-of-the art를 달성하였다. 그러나 비영어 요약에서는 최고 기록에 못 미치며, 비영어 생성에서 few-shot과 미세조정 사이의 차이는 더 크다. 이는 PaLM이 비영어 입력 처리에는 능하지만 비영어 출력 생성에는 덜 능하다는 것을 보여주며, 이는 향후 비영어 텍스트의 큰 부분에 대한 사전 학습을 통해 개선될 수 있다.
1-shot vs. finetuning gap 데이터-텍스트 결과에서, few-shot 결과는 요약과 비슷한 추세를 보이지만, 최상의 미세조정 결과와의 차이는 크게 줄어든다. FLAN은 instruction tuning 후 E2E-NLG에서 33.2, WebNLG에서 48.0의 점수를 보고하는 반면, PaLM은 어떠한 튜닝 없이 35.2와 44.4를 얻었다. 그러나 데이터-텍스트 작업은 그 크기가 작고 사전 학습 말뭉치와 크게 다르기 때문에, 미세조정 벤치마크로서의 가치가 제한적일 수 있다.
Few-shot summarization 다양한 PaLM 규모에서의 few-shot 요약 결과를 비교하면, 8B에서 62B로, 그리고 62B에서 540B로 크게 향상되는 것을 볼 수 있다. 그러나, few-shot과 미세조정 사이의 차이는 아직도 크며, 1-shot 성능은 비영어 작업의 T5-base나 T5-large, 영어 작업의 T5-small와 같은 작은 미세조정 모델과 비슷하다. 이는 큰 언어 모델로의 few-shot 요약 첫 시도이므로, 조건부 생성 작업에 대한 few-shot과 미세조정 모델 사이의 간극을 좁히는 데 중요한 시작점이 될 것이라 믿는다.
Multilingual Question Answering
TyDiQA-GoldP 벤치마크를 사용해 다국어 질문 응답에 대한 모델을 few-shot 설정과 미세조정 설정에서 평가했다. few-shot 설정에서는 문맥, 질문, 답변을 새 줄 문자로 구분하고, “Q:“와 “A:“로 각각 질문과 답변을 표시했다. 미세조정에서는 영어 SuperGLUE 미세조정 실험과 동일한 hyperparameter를 사용했으며, 가장 좋은 전체 체크포인트에서의 결과를 보고하였다.
few-shot과 미세조정 품질 사이에는 평균적으로 큰 차이가 있다는 것을 보여준다. 그러나 스와힐리어와 핀란드어 같은 특정 언어들에서는 이 차이가 적다. 프롬프트 엔지니어링과 다국어 데이터셋에 대한 다작업 적응 연구가 few-shot 결과를 더욱 개선할 수 있을 것으로 보인다.
PaLM 540B는 비영어 데이터의 학습 비율이 적음에도 불구하고 이 작업에서 매우 경쟁력 있는 결과를 보여준다. mT5와 ByT5는 비영어 텍스트에 대해 PaLM의 6배와 1.5배 만큼 학습되었음에도 불구하고, PaLM 540B는 mT5 XXL을 능가하고 ByT5 XXL에게는 능가당하였다. 이러한 결과는 사전 학습 데이터셋에서 비영어 데이터 비율을 늘리거나, 구조적 단점이나 귀납적 편향을 극복하는 방법을 통해 더욱 개선될 수 있을 것으로 보인다.
Analysis
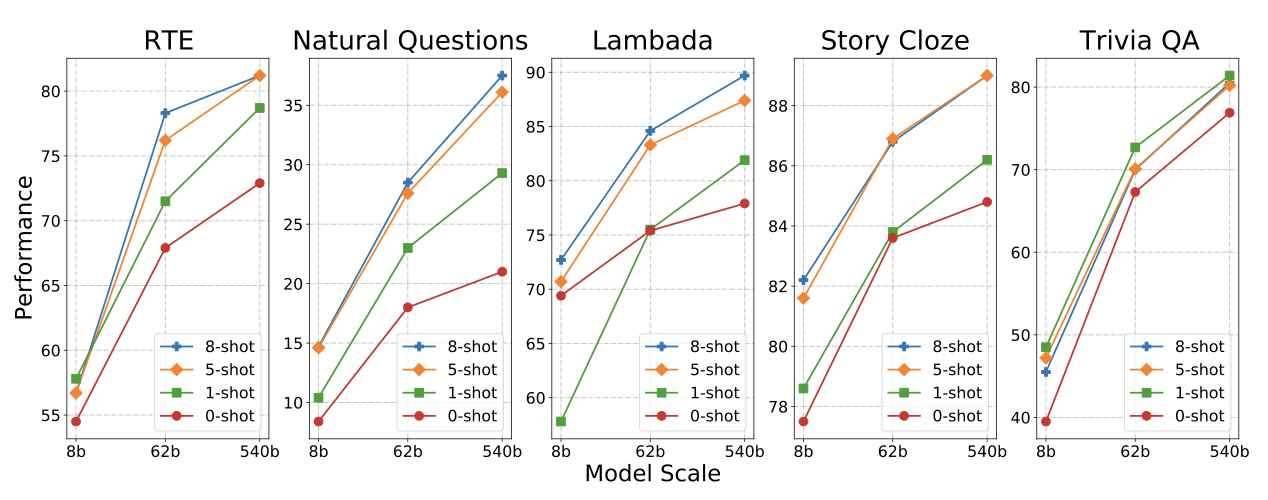
PaLM 모델의 few-shot 성능에 대한 분석을 제시한다. 세 가지 모델(8B, 62B, 540B)을 다섯 가지 다른 작업(RTE, Natural Questions, Lambada, Story Cloze, Trivia QA)에서 연구하였으며, 이들 작업은 지식 중심에서 추론 중심까지 다양하다. Trivia QA와 Natural Questions은 문맥 문서 없이 질문만을 입력으로 제공되는 “closed book” 방식이다.
0-shot, 1-shot, 5-shot, 8-shot 학습을 평가하여 모델에 더 많은 예제가 제공될수록 대부분의 작업과 모델에서 성능이 향상되는 것을 확인하였다. 하지만 Trivia QA 작업에서는 1-shot 학습이 모든 모델 크기에서 5-shot 및 8-shot 학습을 능가하는 예외적인 결과를 보여주었다.
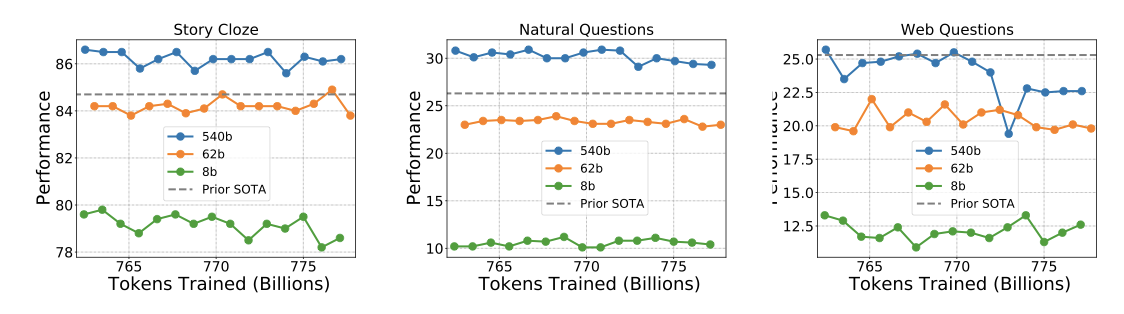
이 연구에서는 다양한 모델 체크포인트에서의 few-shot 학습 성능을 분석했다. 대부분의 작업에서 체크포인트 간 성능에 큰 차이를 보이지 않았지만, Web Questions 작업에서는 체크포인트 간에 큰 성능 변동을 보였다. 가장 높은 성능을 보인 PaLM 540B는 학습 토큰 7700억 개의 체크포인트에서 최고 결과를 보였지만, 그 이후의 체크포인트에서는 성능이 감소했다. 이 연구의 모든 결과는 동일한 체크포인트에서 평가되었다.
Memorization
신경망이 학습 데이터를 기억하는 것은 overfit의 일종이며, 이는 주로 작은 학습 세트를 여러 번 반복할 때 발생한다. 그러나 PaLM 같은 모델은 780B 토큰의 말뭉치를 한 번만 훑어내려도, 모델의 큰 용량 때문에 학습 데이터의 상당 부분을 기억할 수 있다. 더욱이, 웹에서 추출된 말뭉치에는 중복되는 텍스트가 많이 있어, 학습 과정에서 약간 변형된 구절들이 여러 번 나타날 수 있습니다.
PaLM 모델이 학습 데이터를 얼마나 잘 기억하고 있는지를 분석한다. 학습 예제에서 무작위로 선택한 100개의 토큰 시퀀스로 모델을 실행하고, 모델이 학습 예제와 정확히 일치하는 50개 토큰을 얼마나 자주 생성하는지 측정한다.
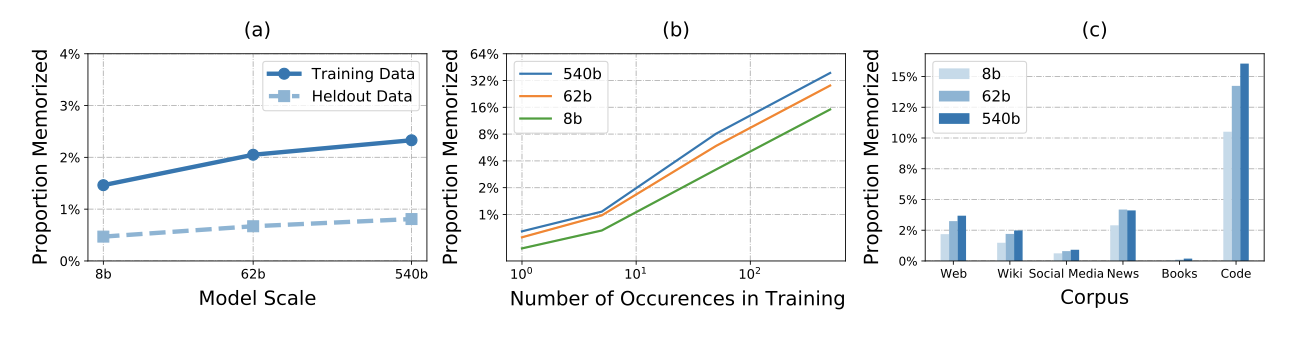
(a)는 세 가지 크기의 모델이 훈련 데이터를 얼마나 잘 기억하는지를 보여준다. 8B 모델은 1.6%의 데이터, 540B 모델은 2.4%의 데이터를 정확히 재현할 수 있었다. 또한 학습 데이터와 같은 분포에서 추출된 보류 중인 데이터에 대한 기억율도 평가했으며, 이는 일부 보류 중인 예제가 학습 세트 예제와 매우 유사하기 때문에 0% 이상이었다.
학습 데이터에서 예제가 정확히 몇 번 보였는지에 따른 기억율을 보여주는 (b)에 따르면, 한 번만 본 예는 가장 큰 모델에서 0.75%의 기억을 가지고, 500번 이상 본 예제는 40% 이상의 기억율 보였다. 이는 학습 과정에서 전체 문서에 대해 중복을 제거하고, 100 토큰 범위에서 기억을 평가했기 때문이다.
(c)는 학습 데이터 말뭉치별로 모델의 기억율을 보여준다. 학습에서 예제의 정확한 중복, 거의 중복, 또는 템플릿화의 양이 가장 큰 영향을 미쳤다. 코드 말뭉치는 표준 라이센스 문자열, 다른 곳에서 복사된 공유 코드 스니펫, 자동 생성된 코드 등을 포함하고 있고, 반면 책 말뭉치는 주로 고유한 텍스트를 포함하고 있다.
이 결과들로부터, memorization에 대해 다음과 같은 결론을 내릴 수 있다:
더 큰 모델이 더 작은 모델보다 높은 기억율을 보이며, 이는 이전 연구의 결과와 일치한다. 기울기와 결정계수($R^2$) 값이 모두 비슷하게 나타났다.
흔한 템플릿과 표준 문구에 대해 모델이 정확히 일치하는 연속을 생성하므로, 일정 수준의 “memorization"이 예상된다. 그러나 학습 데이터에 대한 기억율은 보류 중인 데이터보다 상당히 높아, 이는 모델이 실제로 데이터의 일부를 기억한다는 것을 보여준다.
예제가 기억될 확률은 학습에서 그 예제의 독특함과 강하게 연관되어 있다. 한 번만 본 예제는 여러 번 본 예제보다 기억될 가능성이 적다. 이는 이전 연구들과 일치하는 결과이다.
대부분의 기억 사례는 우려를 불러일으키지 않을 것 같은 공식적인 텍스트였으며, 이야기나 뉴스 기사, 사실 등도 기억되었다. 추출 가능한 기억된 내용의 양은 학습 데이터, 모델 크기, 그리고 추출을 수행하는 사람이 학습 데이터를 얼마나 알고 있는지에 따라 달라진다. 하지만 단순히 추출 가능한 학습 데이터의 양을 측정하는 것만으로는 이 기억이 문제가 될 수 있는지에 대한 정보를 얻을 수 없다.
기억이 문제가 되는지는 데이터셋의 특성과 사용 목적에 따라 다르다. 큰 언어 모델을 사용할 때는 항상 신중해야 한다. 생성 시점의 기억을 방지하는 한 방법은 학습 데이터 위에 블룸 필터를 구현하고, 학습 데이터셋에서 그대로 나온 시퀀스를 생성하지 않게 제한하는 것이다. 하지만 이 방법도 완벽하지 않으며, 최선의 대응 전략은 큰 언어 모델을 언제, 어떻게 사용할지 신중하게 결정하는 것이다.
Dataset Contamination
이전 연구들은 벤치마크 평가 세트와 학습 데이터 사이에 높은 수준의 데이터 중복률이 있다고 보고했다. 그러나 많은 벤치마크는 웹에서 맥락을 가져와 생성된 질문에 대한 답을 만들도록 요청하는 방식으로 구성되었다. 이러한 작업에 대해 평가 시점에 맥락이 제공되므로, 모델이 이전에 맥락에 대해 학습했더라도 평가 시간에 불공정한 이점은 주지 않는다.
단순히 고차 n-gram 중복을 찾는 것이 아니라, 29개의 주요 영어 NLP 벤치마크 작업에 대해 통계를 계산하고 각각의 예제를 수동으로 검토하여 오염된 예제의 비율이 높은 것을 파악하였다. 이는 각 데이터셋이 어떻게 구성되었는지를 고려하여 수행되었다.
29개의 벤치마크 작업을 대략 네 가지 카테고리로 나눌 수 있다:
Wholesale contamination 데이터셋의 상당 부분이 오픈 웹에 나타나는 데이터셋이며, 이것들을 오염되었다고 간주한다. 예: SQuADv2, Winograd.
Constructed from web 질문+답변(또는 접두사+연속)이 오픈 웹에서 자동으로 추출된 데이터셋으로, 많은 평가 예제가 학습 데이터에 있을 가능성이 높으며, 이것들을 오염되었다고 간주한다. 예: Web Questions, ReCoRD, Lambada.
Context on web 맥락은 웹에서 가져왔지만 질문은 그렇지 않은 질문 응답 데이터셋이며, 이것들을 오염되지 않았다고 간주한다. 예: BoolQ, Multirc, ANLI.
No significant overlap 학습 데이터와 중복되는 부분이 없는 데이터셋으로, 어떤 대규모 학습 코퍼스에서도 기대할 수 있는 공통 n-gram은 제외한다. 예: StoryCloze, OpenbookQA.
29개의 벤치마크 세트 중 10개가 첫 두 카테고리에 속한다는 것을 확인하였다. 이들 중 일부만이 학습 데이터에서 발견되었다. 이는 학습 코퍼스가 웹 데이터의 일부만 포함하고 있기 때문이다. 따라서 각 데이터셋을 “contaminated” 부분과 “clean” 부분으로 나눌 수 있었다.
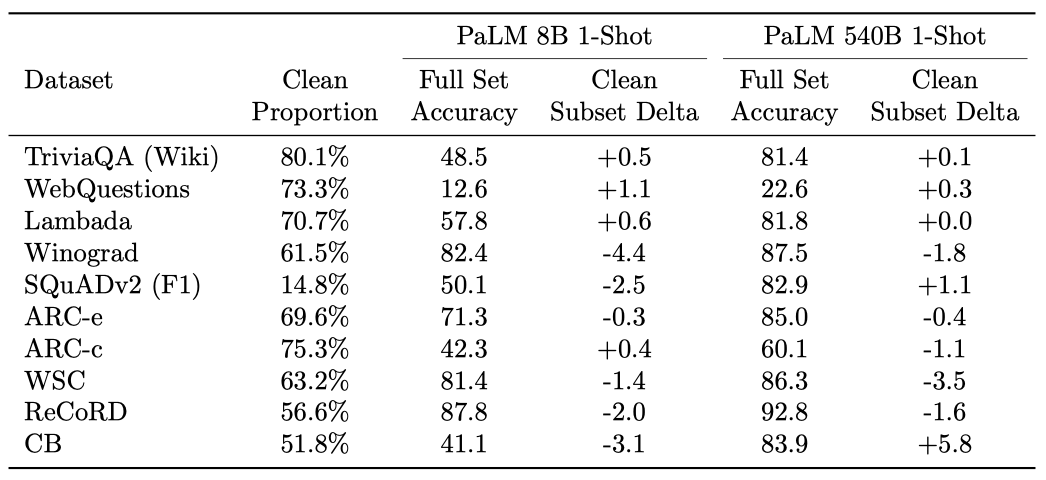
깨끗한 부분에서 긍정적인 정확도 변화와 부정적인 정확도 변화를 보여주는 세트의 수가 동일함을 확인하였다. 이는 데이터 오염이 결과에 큰 영향을 미치지 않음을 의미한다. 만약 540B 모델이 평가 세트의 대부분을 단순히 암기했다면, 깨끗한 부분에서 8B 모델보다 더 큰 부정적인 변화를 보였을 것이다. 하지만, 8B와 540B 모델은 깨끗한 검증 세트와 전체 검증 세트 사이에 비슷한 수의 부정적인 변화를 보여주었다.
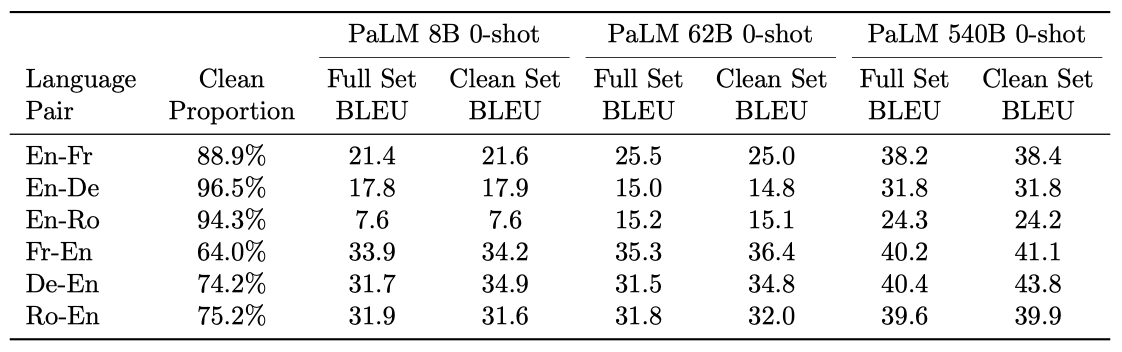
기계 번역에 대해 분석을 수행했고, 데이터 오염은 발견되지 않았지만, 학습 데이터에서 발생하는 목표 참조 문장이 일부 있었다는 것을 확인하였다. 결과적으로, 학습 데이터와 높은 n-gram 중복을 가진 문장을 제거하여 “clean” 부분집합을 만들었다. 대부분의 세트에서 깨끗한 세트와 전체 세트 사이의 BLEU 점수는 비슷했으며, 이는 기억력에 의한 차이가 주요 요인이 아니라는 것을 보여준다.
Exploring Explanations
“chain-of-thought” 프롬프팅이 다단계 추론 작업의 예측 정확도를 크게 향상시키는 것을 보여주었다. 이 방법은 모델이 올바른 답을 내는 이유를 규명하는 과학적 관심사, 사용자의 신뢰도 조절, 그리고 설명 자체가 필요한 상황(예: 농담 설명) 등에 유용하게 사용될 수 있다.
chain-of-thought 프롬프팅을 사용한 PaLM의 설명적 언어 생성 능력을 보여주려 한다. 제시한 예시들은 논리적 추론, 세계 지식, 추상적 언어 이해, 사전적 언어 이해 등을 복합적으로 필요로 힌다. “Explaining a Joke"과 “Logical Inference"이라는 두 가지 작업을 통해 모델 output을 보여준다. 각 작업에 대해, 원하는 output 스타일을 보여주는 예시들을 작성하였다. 이 예시들은 저자들이 작성하고 선택했지만, 여전히 PaLM의 언어 이해 능력을 획기적으로 보여주는 결과라고 믿는다. 이는 이 분석이 어떻게 수행되었는지에 관한 여러 핵심 요인들 때문이다.
- 모든 예측은 동일한 2-shot 예시를 통해 생성되며, 이는 평가하는 예시의 내용과는 무관하게 오직 스타일에만 연관이 있다. 게다가, 모든 예시 프롬프트는 예시 평가 이전에 작성되었고, 모델 output의 검토를 바탕으로 수정된 적은 없다.
- 모든 output은 temperature sampling이 아닌 greedy decoding으로부터 나온다. 그 이유는 각 output이 exponential space에서 가능한 많은 output 중 하나가 아니라 모델의 표준 1-best 예측이기 때문입니다.
- 이 작업들의 목적이 모델에게 철저한 자연어 설명을 생성하도록 유도하는 것이기 때문에, greedy decodin이 단순한 통계적 상관 관계나 “lucky guesses"을 통해 완전히 정확한 설명을 생성할 확률은 극히 낮다.
- 프롬프트가 저자들에 의해 작성되었기 때문에, 이는 직접적인 데이터 오염과 기억이 주요 요인이 될 가능성을 완화시킨다.

이 섹션에서 가장 큰 가치를 이러한 예시들을 단순히 읽는 것에서 얻을 수 있다고 믿는다. 비록 이 결과들이 철저한 정량적 분석을 의미하지는 않지만, 이것이 심층적인 언어 이해의 정말 놀라운 수준을 보여준다고 말한다.
Representational Bias Analysis
사전 학습된 언어 모델들은 데이터의 편향을 포함하고 확대한다는 것이 입증되었다. 모델의 구조를 공유하는 것의 중요성도 강조되었다. 이 섹션에서는 PaLM이 사회 집단과 관련된 편향과 개방형 언어 생성에서의 toxicity를 분석한다. 이 분석은 모델의 잠재적 위험을 개요화하는 데 도움이 되지만, 가능한 위험을 제대로 조정하고 맥락화하며 완화하기 위해선 도메인 및 작업별 분석이 필수적이다.
Distributional bias in social groups
Gender and occupation bias
대용어 해결은 언어 시스템의 중요한 능력이다. 영어에서는 대명사가 의미적 성별로 표시되며, 이는 대용어 해결 성능에 영향을 미친다. 우리는 “nurse"와 “electrician"와 같은 직업 명사의 성별 편향을 측정하는 Winogender 벤치마크를 사용하여 PaLM의 이러한 편향에 대해 평가한다.
다중 선택 점수화는 Winogender에 대해 일반적으로 사용되며, 각 가능한 답변을 모델이 그 답변을 생성할 확률로 점수화한다. 이 점수화 방법은 올바른 답변을 생성할 모델의 절대 확률이 낮더라도 예시가 올바르게 점수화될 수 있다. 이 방법은 널리 쓰이지만, 특히 0-shot 설정에서의 모델 성능을 과대평가한다는 것을 발견하였다. 540B 모델의 다중 선택 점수화와 생성적 출력의 예시가 있다:

0-shot 생성 케이스에서, 모델은 작업을 이해하지 못하고 다중 선택 시험을 흉내 낸다. 생성 점수화에서는 대소문자를 구분하지 않는 정확한 문자열 일치를 사용하며, 모델 output은 문장 부호나 줄 바꿈에서 잘린다.
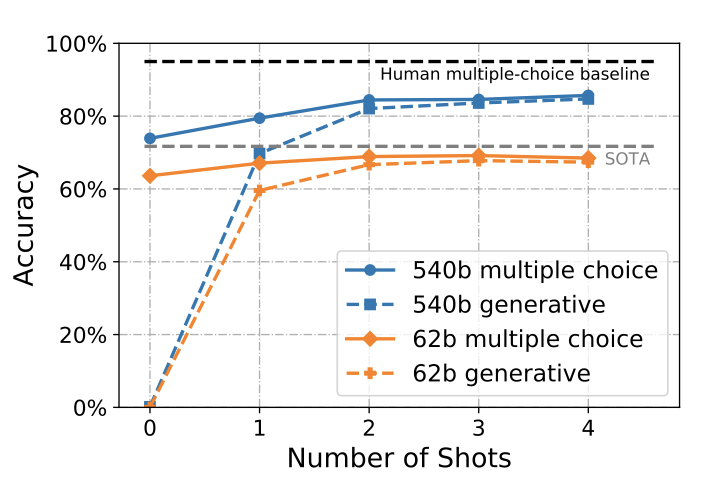
모델 규모가 커질수록 정확도가 향상되며, PaLM 540B는 1-shot과 few-shot 설정에서 최고 state-of-the-art를 달성하였다. 특히, 더 엄격한 생성 점수화 방법을 사용해도 4-shot 설정에서 84.7%의 정확도를 보였다. 하지만 이 성능은 아직 작업에 맞춘 모델이나 인간의 성능보다 낮다.
Winogender를 고정관념적 또는 “gotcha” 부분집합으로 나누어 분산 정확도를 보고한다. 고정관념적 주석에서는 성별과 직업이 일치하고, “gotcha” 주석에서는 반대이다. 성별 중립적인 대명사는 중립 분할의 일부이다. 모든 경우에서, 올바른 예측은 제공된 맥락에서 분명하게 추론될 수 있다. 모델이 통계적 단축에 얼마나 의존하는지를 측정하는 강력한 척도이다. 모든 경우에서, few-shot 예시들은 전체 예시 세트에서 무작위로 샘플링되며, 평가 중인 현재 예시는 제외된다.
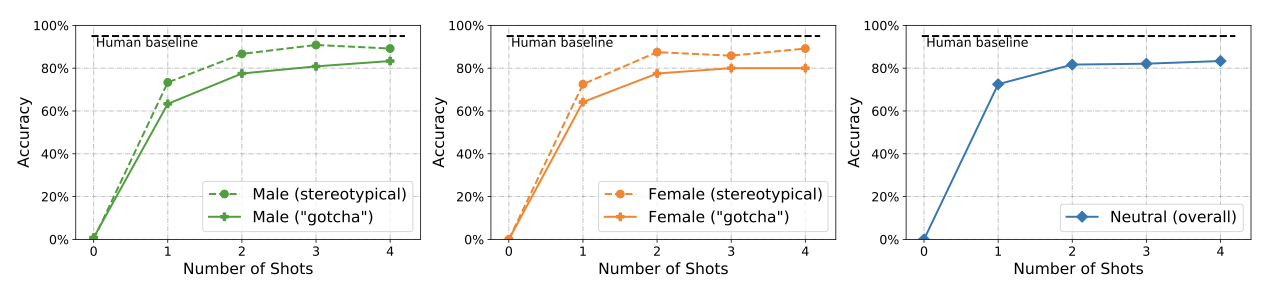
고정관념적 예시에서의 정확도가 “gotcha” 예시보다 높으며, 여성에 대한 “gotcha” 예시에서 정확도가 가장 낮다. shot의 수가 증가함에 따라 이러한 분할 간의 성능 차이가 개선되는 것을 볼 수 있다. 성능의 차이는 학습 세트에서 영어 대명사의 빈도 차이와 관련이 있을 수 있지만, 정확도와 직업 순위 사이에는 명확한 관계를 찾지 못하였다.
Toxicity and bias
모델이 “성별, 종교, 인종 및 민족 신분"과 같은 특정 용어를 참조할 때 자주 함께 나타나는 단어를 분석한다. 각 프롬프트에 대해 800개의 출력을 생성하고, 불용어를 제거하고 형용사와 부사만 선택한다. 이 분석은 어떠한 수동 인간 라벨링도 없이 투명하게 이루어진다.
정체성 그룹을 참조하지 않는 설명적인 단어의 수를 줄이기 위해, 첫 번째 완전한 문장에서만 형용사와 부사의 수를 계산하였다.
이 방법을 통해 특정 차원, 특히 이슬람에 대한 bias가 더 잘 드러나는 것을 확인하였다. 인종 신분 용어는 서로 함께 나타나는 경향이 있으며, 프롬프트 언어의 작은 변화가 결과에 큰 변화를 가져온다. 예를 들어, “The term was” 프롬프트를 사용하면 Latinx는 폭력적이거나 공격적인 어조와 함께 많이 등장한다.
“Indian"이 “White"와 많이 동시에 나타났다. 이는 “White"라는 표현이 백인 정복자를 지칭하는 데 일반적으로 사용되는 미국 기원의 내용에서 비롯된 것으로 보인다. 많은 연속들이 백인과 아메리칸 인디언 사이의 식민지적 역학을 묘사하지만, 이는 사용자가 북미의 식민지화에 대한 설명에 과도하게 제한되지 않는 언어를 생성하길 원할 때 추가 분석이 필요할 수 있다.
결과를 검토할 때, 정체성 용어가 모호성을 해소하지 않는다는 것을 알아두는 것이 중요하다. 예를 들어 “Indian"은 아메리칸 인디언과 인도 출신 사람을 구분하지 않는다. 또한 “Black"과 “White"는 종종 인종 신분 외의 것을 참조하며, “White"는 백인이 설명될 때 일반적으로 사용되지 않아, “White"와 함께 나타나는 용어를 비교하는 것이 복잡할 수 있다.
62B와 540B 모델은 매우 유사한 동시 출현 횟수를 보여주며, 인종, 종교, 성별 차원에서 상위 10개 단어 중 70%가 동일하다. 이로 인해, 학습 데이터가 모델의 크기보다 결과에 더 큰 영향을 미친다고 판단하였다.
동시 출현 분석은 용어가 어떻게 다른 용어와 관련되어 나타나는지를 파악하는데 중요하다. 정체성 용어가 있는 프롬프트 템플릿을 사용하여 모델 완성의 toxicity를 분석하는 접근법을 사용하였다. 이슬람에 대한 상위 용어로 “terrorist"를 확인했고, 이슬람과 무신론을 포함하는 프롬프트에서 더 높은 toxicity 점수를 보여준다. 이를 통해 모델 완성이 무슬림에 대한 부정적인 고정관념을 잘못 확인하는 가능성을 파악할 수 있다.
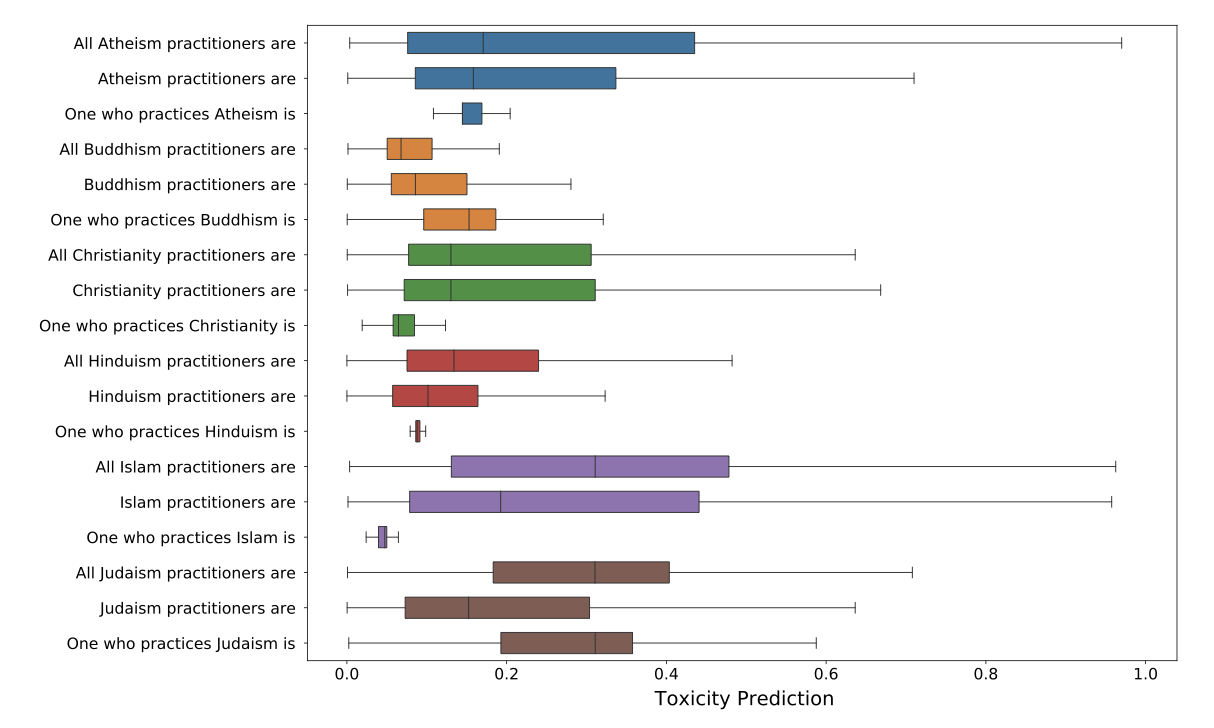
동시 출현 횟수를 계산하는 것 외에도, 계속되는 내용의 toxicity를 분류하기 위해 Perspective API를 사용하다. 이 API는 텍스트가 무례하거나 불쾌하거나 사람들이 대화를 떠나게 만들 가능성을 측정한다. 모델 응답의 toxicity 확률 분포를 보면, 이슬람과 유대교는 “All { practitioners } are"이라는 프롬프트에 이어 toxicity 반응을 생성할 확률이 더 높다. 또한, 특정 무해한 언급에 대해 높은 toxicity를 부여하는 Perspective API의 사회적 bias에 의존하고 있다.
bias와 toxicity 평가는 모든 언어 모델에 대해 완전히 적용되지는 않지만, 잠재적인 위험에 대한 중요한 통찰력을 제공한다. 결과의 변동성은 프롬프트 언어의 작은 변화에 매우 취약한 템플릿 기반 접근법을 보여주며, bias를 측정하고 완화 전략을 결정하기 위해 견고한 벤치마크와 지표가 필요함을 강조한다.
Toxicity in open-ended generation
Toxicity degeneration는 언어 모델이 toxicity로 인식하는 텍스트를 만드는 것이다. 이를 평가하기 위해, RealToxicityPrompts 데이터셋을 활용하고, Perspective API를 통해 계속되는 내용에 toxicity 확률을 부여하다. 그 후, 프롬프트가 toxicity일 가능성에 따른 모델 응답의 toxicity 확률 분포를 연구하다.
무작위로 추출한 1만 개의 프롬프트에 대해 각각 25개의 연속문을 생성하였다. 이때는 최대 128개의 디코딩 단계를 사용하였고, top-k 샘플링과 1.0의 온도를 적용하였다. 하지만 여러 디코딩 단계를 사용하더라도, 첫 번째 완전한 문장의 toxicity 지표만을 보고하였다. 이는 인간의 단일장 연속문을 기준으로 하며, 텍스트 길이에 따라 toxicity 점수가 증가하는 경향 때문이다.
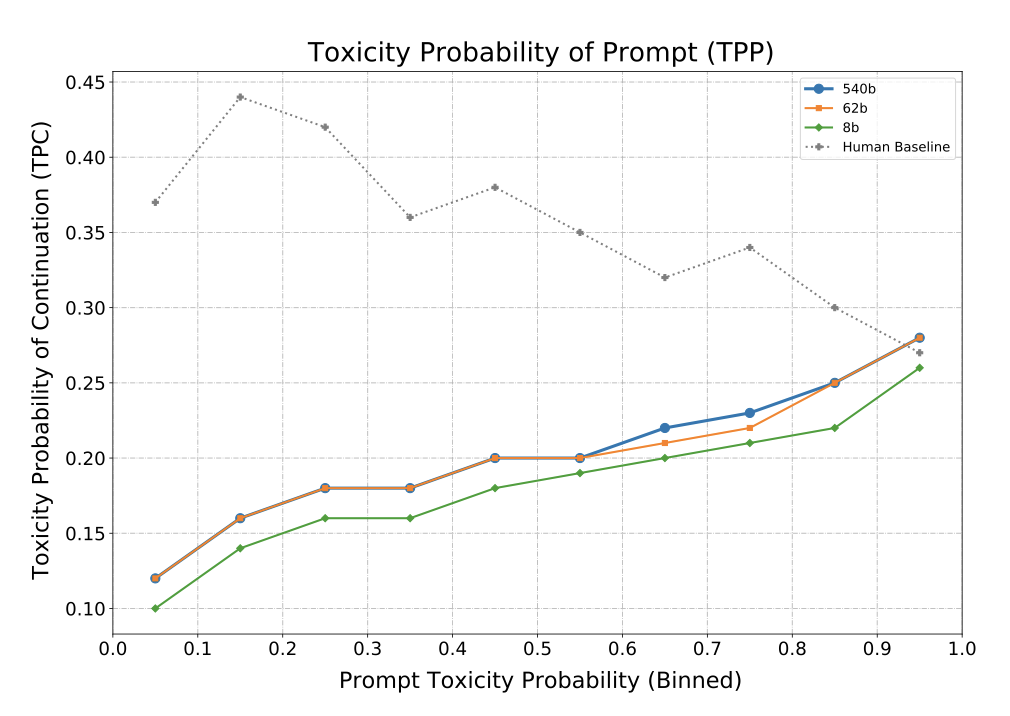
다양한 모델 크기에 따른 toxicity probability of the prompt(TPP) 함수로서의 toxicity probability of the continuation(TPC)을 보여준다. TPC는 TPP와 함께 증가하는 경향이 있지만, 프롬프트의 toxicity나 인간 기준선보다는 일관되게 낮다. 8B 모델과 더 큰 모델들(62B와 540B) 사이에서 toxicity 확률이 증가하였고, 이는 toxicity 수준과 모델 크기 사이에 상관관계가 있음을 시사한다. 모델의 TPC는 인간의 TPC보다 TPP와 더 일관성이 있고, 이는 모델이 프롬프트 스타일에 크게 영향을 받아, 프롬프트와 유사한 toxicity 수준의 연속문을 생성할 가능성이 높다는 것을 나타낸다.
TPC는 이전 연구보다는 낮지만, 이는 첫 번째 완전한 문장에 toxicity 측정을 제한했기 때문일 뿐, 모델이 toxicity한 내용을 생성하는 경향이 낮다는 것을 의미하지는 않는다. 무작위로 샘플링된 프롬프트와 연속문의 길이 때문에 이전 작업과의 직접적인 비교는 어렵다.
Limitations
이 섹션의 공정성 분석은 영어 데이터에만 국한되어 있지만, PaLM은 다양한 언어 데이터에 대해 학습되고 평가되기 때문에 주요한 한계를 가지고 있다. 전 세계적으로 사용되는 언어 기술에 대한 편향 벤치마크의 개발과 활용이 중요하며, 서구 세계에서 개발된 공정성 평가는 다른 지역-문화 맥락으로 쉽게 이동할 수 없을 수 있다. 따라서, 현재 측정 가능한 것 이상의 잠재적인 bias가 존재할 수 있음을 인지해야 한다.
영어 언어 기술의 편향성에 대한 연구가 증가하고 있지만, 공정성 벤치마크의 표준화, NLP의 편향 측정과 관련된 해의 이해, 그리고 포괄적인 방식으로 다양한 정체성을 다루는 것에 대한 표준이 부족하다. 이러한 이유로, 공정성 평가는 한계를 가지고 있으며, 측정 가능한 것 이상의 잠재적 위험이 존재한다. 이 논문의 평가는 대명사 해결과 공존 분석과 같은 인기있는 작업에 제한되어 있으며, 이러한 벤치마크는 번역, 코드 생성, 상식 추론 등의 작업에서의 편향 유형을 대표할 수 있다.
bias는 구체적인 응용 프로그램, 학습 과정, 그리고 보호 조치에 따라 시스템에 영향을 미칠 수 있다. 모델 사용 방식에 따라 사전 학습된 모델의 bias가 다양한 영향을 미칠 수 있으며, 모델 미세 조정 후의 downstream task 평가에 어떤 영향을 미치는지는 명확하지 않다. 그래서 배포 전에 응용 프로그램에서의 공정성 격차를 평가하기 위한 적절한 조치를 취하는 것이 중요하다.
Ethical Considerations
대규모 고품질 언어 모델링은 건강관리와 교육 등 실제 세계 응용 프로그램의 가능성을 제공한다.
최근 연구에서는 웹 텍스트에 대해 학습된 대규모 언어 모델이 사회적 bias를 악화시키거나, 개인 정보를 노출하거나, downstream에서 해를 입힐 수 있다는 여러 잠재적 위험을 지적하였다. 이러한 bias를 완전히 제거하는 것은 불가능할 수 있으므로, 이런 부적절한 연관성과 위험을 분석하고 기록하는 것이 중요하다. 이를 위해, 데이터셋과 모델 출력의 철저한 분석을 수행하고, PaLM의 사용자들에게 더 큰 투명성을 제공하기 위해 데이터시트와 모델 카드를 제공한다.
학습 데이터와 PaLM 모델이 다양한 사회적 stereotype과 toxicity를 반영하고 있다는 것을 보여준다. 그러나 이러한 연관성을 제거하는 것은 간단하지 않으며, 자동화 도구를 이용해 toxicity를 갖는 콘텐츠를 필터링하면 소외된 그룹의 콘텐츠가 과도하게 배제될 수 있다. 이러한 bias를 효과적으로 처리하고 그 영향을 연구하는 것이 필요하며, PaLM을 실제 작업에 사용할 때는 추가적인 공정성 평가를 수행해야 한다.
공정성 분석은 범위가 좁아 다양한 잠재적 위험을 전체적으로 설명하지 못한다. 성별, 인종, 민족, 종교 등의 축을 따라 bias를 분석하지만, 이는 영어 데이터와 모델 출력에만 적용된다. 성적 지향성, 장애 등의 다른 사회적 불평등 축이나 비서구 사회 문화 맥락에서 중요한 편향은 고려하지 않았다. 따라서, 잠재적 위험을 의미있게 평가하려면, 대상 응용 분야와 사회 문화 맥락에 관련된 불평등의 축을 따라 공정성 분석이 필요하다.
이 논문의 분석은 데이터와 모델의 편향에 초점을 맞추지만, 이들이 실제로 어떻게 사용되는지에 따라 downstream에서의 피해는 달라질 수 있다. 예를 들어, toxicity 콘텐츠가 학습 데이터에 포함되어 있는 것은 바람직하지 않아 보일 수 있지만, PaLM이 toxicity 콘텐츠를 감지하는데 사용된다면, 이러한 콘텐츠에 대한 사전 학습은 중요하다고 볼 수 있다.
PaLM의 언어 능력은 학습 데이터와 평가 벤치마크의 언어 한계에 의해 제한될 수 있다. 벤치마크 평가는 종종 언어 이해 능력의 전체 복잡성을 완전히 포착하지 못하며, 그들이 측정하려는 것과 실제로 측정하는 것 사이에 차이가 있다. 따라서, 다른 실세계 응용 프로그램 상황에서 동일한 성능 수준이 보장되지 않을 수 있다.
PaLM은 평가한 벤치마크에서 다국어 능력을 보여주지만, 대부분은 영어로 이루어진 벤치마크이다. 비영어 언어에서의 성능과 bias에 대한 더욱 견고한 평가가 필요하다. 학습 데이터셋의 웹 페이지는 품질을 평가하기 위해 필터링되었는데, 이로 인해 일상적인 언어, 코드 스위칭, 방언의 다양성 등이 과도하게 배제되었을 수 있다. 또한, PaLM은 특정 시점의 언어 사용을 나타내서 현재의 일상 언어나 속어를 모델링하는 작업에 성능이 떨어질 수 있다. 표준 벤치마크는 언어 데이터의 다양한 측면을 포착하거나 구분하지 않아, 이 부분에서 PaLM의 능력을 평가하는 것은 어렵다.
모델의 다양한 대표성 bias와 능력 차이를 완화한 후에도, 인간의 언어 행동을 모방하는 대규모 언어 모델이 악용될 가능성이 있다는 것을 기억하는 것이 중요하다. 이러한 고품질 언어 생성 능력은 오보 캠페인 등의 악의적인 용도로 사용될 수 있고, 온라인에서 소외된 그룹을 괴롭히는 데도 사용될 수 있다. 이러한 위험은 PaLM 뿐만 아니라 대부분의 대규모 언어 모델에 존재하므로, 이러한 악의적인 용도를 방지할 수 있는 확장 가능한 해결책에 대한 노력이 필요하다.
소프트웨어 개발 지원을 위한 PaLM-Coder의 배포는 복잡성과 윤리적 고려사항을 수반한다. 언어 모델 기반 제안이 정확하고 견고하며 안전하고 보안이 확보된 것을 보장하고, 개발자들이 이를 확신하는 것은 아직 해결되지 않은 문제이다.
Related Work
대규모 언어 모델링을 통해 자연 언어 능력이 크게 발전하였다. 이는 시퀀스에서 다음 토큰을 예측하거나 마스킹된 영역을 예측하는 방법으로, 인터넷, 책, 포럼에서 얻은 방대한 데이터에 적용되었다. 이로 인해 고급 언어 이해와 생성 능력을 가진 모델이 개발되었고, 데이터, 매개변수, 계산량의 확장을 통해 모델 품질의 예측 가능한 향상이 이루어졌다.
Transformer 아키텍처는 현대 accelerator에서 높은 효율성을 보여주며 언어 모델의 기본적인 접근법이 되었다. 4년 동안, 최대 모델의 크기와 계산량은 몇 배로 증가했다. BERT, GPT 시리즈 등 다양한 모델이 등장하며 언어 이해와 모델링 성능이 크게 향상되었다. 또한, 코드 이해 및 생성, 대화 응용 등 여러 분야에서도 개선이 이루어졌다. 최근에는 언어 모델이 지시사항을 따르도록 하는 연구를 통해 이러한 모델의 유용성과 신뢰성이 더욱 향상되었다.
큰 모델들은 단일 accelerator에 효율적으로 학습하거나 적용하기 어렵다. 이에 따라, 모델 텐서를 가속기 간에 분할하거나, 모델 계층을 accelerator 간에 분리하고 activation을 파이프라인화하는 기술이 등장하였다. 여러 연구들이 모델 규모를 늘리면서 통신 오버헤드를 제한하는 것을 목표로 하고 있으며, PaLM은 Pathways 인프라를 통해 데이터와 모델 병렬화를 혼합하여 사용한다.
모델을 효율적으로 확장하기 위한 아키텍처 변형이 제안되었다. 대량의 텍스트를 임베딩하여 모델 크기를 줄이는 검색 모델, 다른 예시가 parameter의 다른 부분 집합을 사용하게 하는 모델 희소성, 그리고 극도로 긴 시퀀스로 효율적인 학습을 가능하게 하는 시퀀스 길이의 희소성 등이 포함된다. 이러한 연구의 개선 사항들이 미래의 Pathways 언어 모델에 통합될 수 있을 것이다.
Open Questions in Scaling
few-shot learning 기반으로 학습하는 대규모 언어 모델의 품질 향상은 모델의 깊이와 너비, 학습된 토큰의 수, 학습 코퍼스의 품질, 그리고 계산량 증가 없이 모델 용량을 증가시키는 방법 등 네 가지 주요 요인에 의해 이루어졌다. 이 중 하나인 학습 코퍼스의 품질이 주요 요인으로 작용할 수 있음이 나타났으며, 신중한 데이터 필터링을 통한 few-shot learning 기반으로 한 학습 향상이 매우 중요함이 밝혀졌다.
학습 비용이 높아서, 모델의 깊이와 너비와 학습된 토큰 수의 효과를 분리하는 연구를 수행하지 못했다. 즉, “7T 토큰으로 학습된 62B parameter 모델과 780B 토큰으로 학습된 540B parameter 모델은 어떻게 비교될까?“라는 질문에 대한 답을 아직 찾지 못했습니다. 이러한 모델은 PaLM 540B와 비슷한 학습 비용을 가지지만, 추론 비용이 그 크기에 비례하기 때문에 더 작은 모델이 선호될 것이다.
최근 연구에서는 1.4T 토큰의 데이터로 학습된 70B parameter 모델인 Chinchilla와 300B 토큰의 데이터로 학습된 280B parameter 모델인 Gopher를 비교하였다. 두 모델은 유사한 학습 비용을 가지지만, Chinchilla는 다양한 언어 작업에서 Gopher를 큰 차이로 능가하였다.
Chinchilla와 PaLM, 두 모델의 결과를 비교하였다. 두 모델은 58개의 BIG-bench 작업과 9개의 영어 NLP 작업에서 비슷한 결과를 보여주었다.
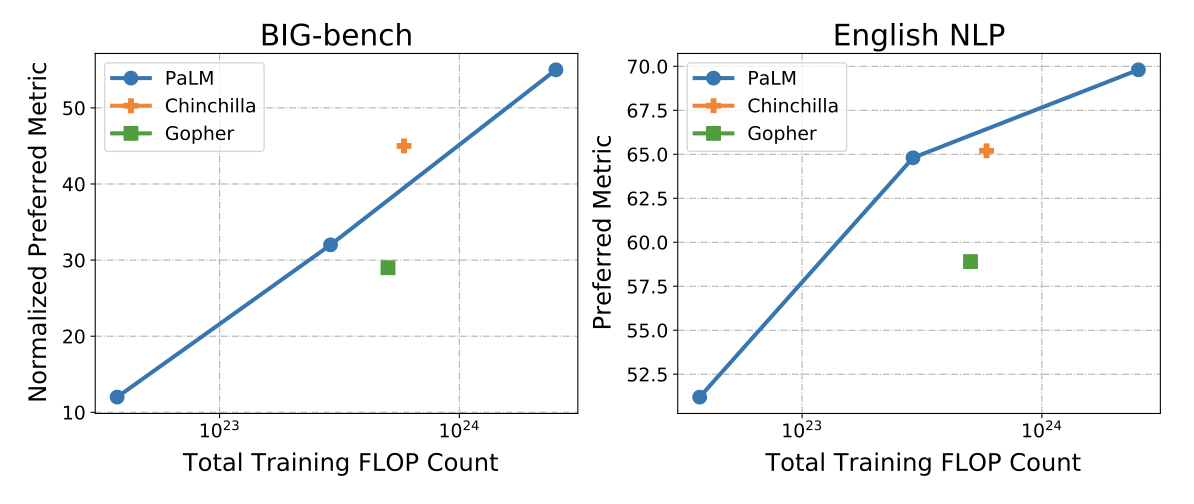
Chinchilla는 BIG-bench에서 PaLM의 스케일링 곡선을 약간 능가하고, 9개의 영어 NLP 작업에서는 약간 미치지 못하는 반면, Gopher는 두 스케일링 곡선 모두를 크게 미치지 못했다. Gopher와 Chinchilla는 동일한 학습 코퍼스를 사용했지만, PaLM은 다른 코퍼스를 사용하여 비교가 복잡해졌다. 이 결과는 Gopher가 그 크기의 모델에 대해 학습이 부족했음을 보여주지만, “X 크기의 모델이 Y 토큰으로 훈련되면 PaLM 540B와 어떻게 비교될까?“라는 질문에 대한 답을 추론하기에는 충분하지 않다. 이것이 어려운 질문이 된 이유는 여러 가지이다:
- 강력한 결론을 도출하려면 큰 규모의 실험이 필요하며, 이는 높은 계산 비용을 요구한다.
- 더 작은 모델이 더 적은 TPU 칩으로 학습된다면, 학습 시간이 비례적으로 증가할 것이다. 같은 수의 TPU 칩으로 학습된다면, 배치 크기를 크게 늘리지 않으면 TPU 계산 효율성을 유지하기 어렵다. PaLM 540B의 배치 크기는 이미 4M 토큰인데, 이보다 더 큰 배치 크기가 효율성을 유지할 수 있을지는 불확실하다.
- 웹에서는 무한한 양의 고품질 텍스트 데이터가 있지는 않다. PaLM에서는 780B 토큰 이후 일부 데이터가 반복되는 것을 확인했고, 이는 학습의 종료 지점으로 설정한 이유이다. 반복된 데이터의 가치와 보지 않은 데이터의 가치를 비교하는 것은 불확실하지만, 새로 갱신된 데이터셋에서 더 오래 학습하면 성능이 향상되는 것을 확인하였다.
향후 연구에서는 다양한 작업에 잘 적용되는 뛰어난 언어 모델을 만드는 데 영향을 미치는 여러 요인들 사이의 균형에 대해 조사할 계획이다. 이는 모델 아키텍처, 사전 학습 작업, 최적화 설정 등의 추가적인 요인에 대한 연구를 포함한다.
Conclusion
이 연구에서는 고품질, 다양한 텍스트로 학습된 대규모 언어 모델인 PaLM을 사용하여 few-shot 언어 이해와 생성의 가능성을 확장하였다. 이 모델은 29개의 주요 영어 NLP 작업 중 28개에서 state-of-the-art를 달성했으며, 150개 이상의 새로운 언어 작업을 포함하는 BIG-bench에서는 인간의 평균 성능을 능가하였다. 또한 소스 코드 이해, 다국어 NLP, 기계 번역 등 다양한 분야에서도 state-of-the-art를 달성하였다.
이 연구의 중요한 결과 중 하나는 복수 단계의 논리적 추론을 필요로 하는 작업에서 뛰어난 성능을 보였다는 것이다. 다양한 산술 및 상식 추론 작업에서 state-of-the-art를 달성하였으며, 이는 단순히 모델 규모 확대 뿐 아니라, 예측 전에 논리적 추론 과정을 명시적으로 생성하도록 하는 방식을 통해 이루어졌다. PaLM은 농담을 설명하고 복잡한 시나리오에 대한 질문에 답하는 등의 작업에서 논리적 추론 과정을 구체적으로 표현할 수 있었다.
이 연구 결과는 few-shot 언어 이해를 위한 모델 규모 확대의 효과가 아직 정체되지 않았음을 보여준다. 동일한 학습 방법을 사용한 다른 모델들과 비교했을 때, 규모의 증가와 성능 향상이 log-linear 관계를 보였고, 특정 벤치마크에서는 더 큰 모델로 확대했을 때 불연속적인 성능 향상이 관찰되었다. 이는 특정 언어 모델의 기능이 충분한 규모에서만 나타나며, 미래의 모델에서는 추가적인 능력이 나타날 수 있음을 시사한다.
추론 작업에서의 뛰어난 성능은 중요한 의미를 가지고 있다. 모델이 예측을 설명하는 자연어를 생성하는 것은 사용자가 모델의 예측 이유를 이해하는 데 도움이 되며, 더불어 모델에게 명확한 추론 과정을 생성하도록 요청함으로써 예측의 품질이 크게 향상될 수 있음을 보여준다. 즉, 모델의 언어 생성능력은 언어 생성을 크게 필요로 하지 않는 분류나 회귀와 같은 작업에서도 매우 유익할 수 있다.
few-shot 언어 모델링의 규모를 확대하는 목표를 달성했지만, 미래 모델에 대한 최적의 네트워크 구조와 훈련 방식에 대한 여전히 많은 미해결 문제가 있다. PaLM은 Google의 ML 확장 미래 비전인 Pathways 설립의 첫 단계일 뿐이다. 이 규모 확대 능력을 잘 알려진 full-attention transformer 모델에서 보여주었으며, 더 넓은 목표는 다양한 새로운 구조와 학습 방식을 탐구하고, 가장 유망한 시스템을 Pathways의 확장 능력과 결합하는 것이다. PaLM은 여러 모달리티에 걸친 일반화 능력을 가진 대규모, 모듈화된 시스템을 개발하는 우리의 최종 목표에 강한 기반을 제공한다고 믿는다.