Abstract
retrieval된 문서 조각들을 조건으로 사용하여 언어 모델을 향상시키는 새로운 방법을 제시하였다. 이 방법을 사용한 Retrieval-Enhanced Transformer (RETRO)는 적은 parameter로도 GPT-3와 Jurassic-1의 성능에 버금가는 성과를 보여주었다. 미세 조정 후에는 지식 집약적인 작업에도 뛰어난 성능을 보여주었다. 이 연구는 대규모 메모리를 통해 언어 모델을 향상시키는 새로운 방향을 제시한다.
Introduction
언어 모델링은 텍스트의 확률을 모델링하는 비지도 학습 작업이다. neural network이 강력한 언어 모델로 입증되었고, transformer의 형태로 발전하면서 큰 성능 향상을 보여주었다. 이러한 성능 향상은 데이터, 학습 컴퓨팅, 모델 parameter의 양을 늘림으로써 이루어졌다. 특히, transformer는 원래의 작업에서 100M 개의 parameter 모델로 시작해 지난 두 해 동안 수백 억 개의 parameter로 확장되면서 다양한 작업에서 뛰어난 성능을 보였다. parameter 수를 늘리는 것은 학습과 추론 시간에 더 많은 계산을 수행하고, 학습 데이터를 더 많이 기억하는 데 도움이 된다.
이 연구에서는, 계산량을 크게 늘리지 않으면서 대규모 메모리를 언어 모델에 효율적으로 적용하는 방법을 탐구하였다. 이를 위해 대규모 텍스트 데이터베이스에서 retrieval 하는 것을 제안하였고, 이를 통해 모델의 크기를 늘리고 더 많은 데이터에 대해 학습하는 대신, 모델이 큰 데이터베이스에 직접 접근하여 예측을 수행하는 능력을 부여하였다. 이 연구는 큰 parameter 언어 모델에 대해 retrieval 데이터베이스를 수조 개의 토큰으로 확장하는 이점을 처음으로 보여준다.
- retrieval-enhanced autoregressive 언어 모델, RETRO를 소개하였다. 이 모델은 retrieval된 텍스트를 포함시키는 데 청크화된 cross-attention 모듈을 사용하며, retrieval 된 데이터의 양에 비례하는 시간 복잡도를 가진다. 또한, 사전 학습된 고정된 Bert 모델을 기반으로 하는 retrieval 방법이 큰 규모에서도 작동함을 보여주었다. 이로 인해 retriever 네트워크를 별도로 학습하고 업데이트할 필요가 없어졌다.
- 이 논문의 방법은 모델 크기와 데이터베이스 크기에 따라 잘 확장되며, RETRO는 다양한 모델 크기에 대해 일정한 향상을 보여준다. 또한, 데이터베이스 크기와 retrieval 된 neighbour의 수를 늘림으로써 RETRO의 성능을 개선할 수 있다. 가장 큰 모델은 여러 평가 데이터셋에서 state-of-the-art릉 달성하였으며, RETRO는 질문 응답과 같은 다양한 작업에서 경쟁력 있는 성능을 보여주었다.
- 테스트 문서와 학습 세트 간의 근접성을 고려한 평가 방법을 제안하였다. 이는 테스트 세트 유출 문제를 해결하며, 모든 언어 모델, 특히 평가 중에 학습 데이터셋에 직접 접근하는 retrieval-enhanced 모델에 중요하다. 이 방법을 통해, RETRO의 성능이 neighbour 복사와 일반 지식 추출 두 가지 요소로부터 나온다는 것을 보여주었다.
Method
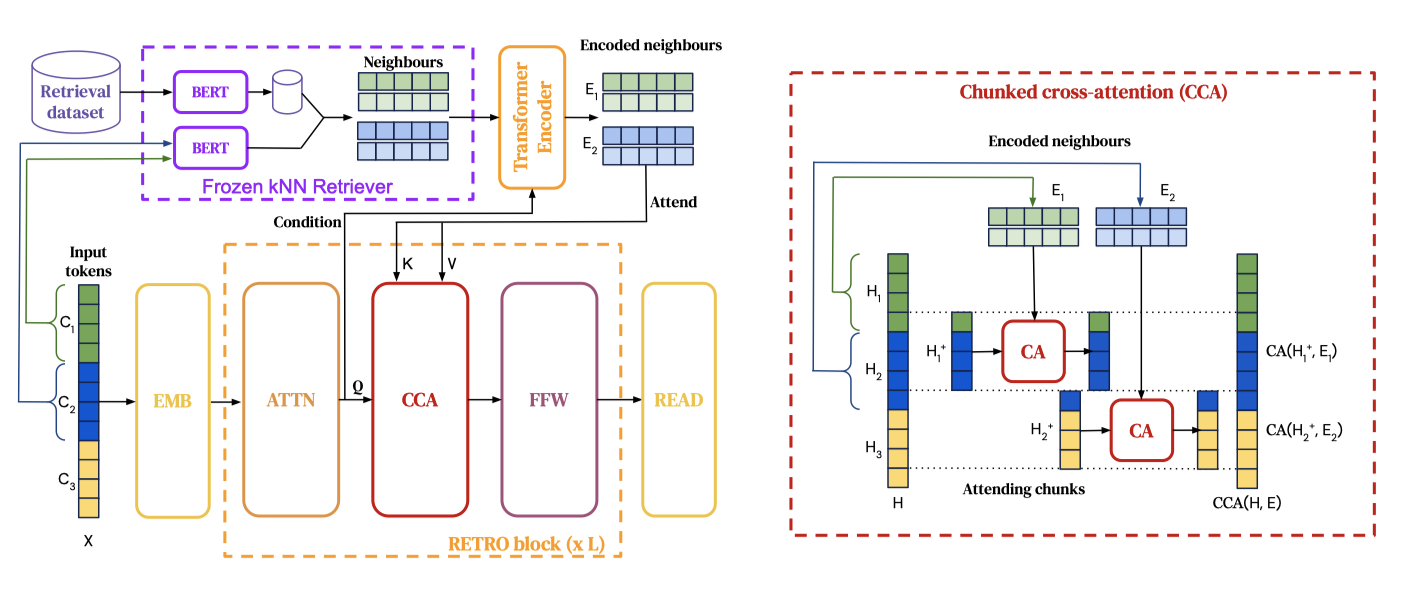
trillion 개의 토큰이 있는 데이터베이스에서 retrieval 할 수 있는 아키텍처를 설계하였다. 이를 위해 개별 토큰 대신 연속적인 토큰 청크를 retrieval 한다. key-value 데이터베이스를 구성하고, 고정된 Bert 임베딩을 키로 사용한다. 각 학습 시퀀스는 청크로 나누어지고, 데이터베이스에서 retrieval된 k-nearest neighbour로 확장된다. encoder-decoder 아키텍처는 retrieval 청크를 모델의 예측에 통합한다. 또한, 평가 세트가 학습 세트에 부분적으로 포함되어 있을 때 언어 모델을 평가하는 새로운 방법론을 소개한다.
Training dataset
학습과 retrieval 데이터에 대해 다중 언어 MassiveText를 사용하며, 이 데이터셋은 5T 개 이상의 토큰을 포함한다. 데이터셋을 SentencePiece로 토큰화하고, 학습 중에는 학습 데이터에서 600B 개의 토큰을 retrieval 한다. 평가 시에는 데이터셋의 전체 합집합에서 retrieval 하며, 이 retrieval 데이터베이스는 1.75T 개의 토큰을 포함한다. 테스트 세트 유출을 제한하기 위해, 학습과 테스트 문서 사이의 유사성을 계산하고, 높은 유사성을 가진 학습 문서를 제거한다. 또한, 위키피디아 학습 데이터에서 Wikitext103의 검증 및 테스트 기사를 제거한다.
Retrieval-enhanced autoregressive token models
토큰의 작은 청크 단위로 입력 예제를 확장하는 방법으로 retrieval을 사용한다. 텍스트 토크나이저를 이용해 얻은 정수 토큰 시퀀스를 고려하며, 각 예제를 청크로 나눈다. 이 청크는 데이터베이스에서 retrieval된 neighbour 집합으로 확장된다. 이전 토큰과 retrieval된 neighbour를 입력으로 받는 모델은 토큰의 가능성을 제공하며, 이는 retrieval이 향상된 시퀀스 log-likelihood를 정의한다:
$$ L(X|\theta, \mathbf{D}) \triangleq \sum_{u=1}^l \sum_{i=1}^m \mathsf{l}_{\theta} ( x_{(u-1)m+i} | (x_j)_{j<(u-1)m+i}, (\mathbf{RET}_{\mathbf{D}}(C_{u’}))_{u’<u} ) $$
첫 번째 청크의 토큰 가능성은 어떤 retrieval 데이터에도 의존하지 않게 설정한다. 이는 autoregressivity를 보존하며, 특정 청크의 토큰 확률은 이전에 본 토큰과 이전 청크에서 retrieval된 데이터에만 의존한다. logprobability로 직접 샘플링하며, 이는 retrieval-enhanced 모델을 샘플링을 통해 평가되는 가장 큰 언어 모델과 직접 비교할 수 있게 한다.
Nearest neighbour retrieval
Retrieval neighbours. 데이터베이스는 key-value 메모리로 구성되어 있다. 각 값은 연속적인 두 개의 토큰 청크로 이루어져 있으며, 이는 neighbour 청크와 그것의 연속성을 나타낸다. 키는 Bert 임베딩의 평균을 통해 계산되며, 각 청크에서는 BERT 임베딩의 $L2$ 거리를 사용하여 approximate k-nearest neighbour를 retrieval 한다. 모델은 이를 통해 의미있는 개선을 제공하며, 학습 중 인과성을 깨뜨리는 청크를 retrieval 하는 것을 피한다.
$T$ 요소의 데이터베이스에서는 $O(log T)$ 시간 안에 approximate nearest neighbour을 찾을 수 있다. 이를 위해 SCaNN 라이브러리를 사용하며, 이를 통해 2T 토큰의 데이터베이스를 10ms 안에 쿼리할 수 있다. 실시간 retrieval은 학습 계산의 속도를 따라가기 어렵기 때문에, 모든 approximate nearest neighbour을 미리 계산하고 데이터의 일부로 결과를 저장한다. 위키피디아 내에서만 neighbour를 retrieval한 결과, neighbour는 주로 주어진 기사에서 2-3 링크 떨어져 있는 반면, 랜덤한 기사는 5개 이상의 링크가 떨어져 있음을 발견하였다.
RETRO model architecture
이 모델은 encoder-decoder transformer 아키텍처를 사용하며, cross-attention 메커니즘을 통해 retrieval된 데이터를 통합한다. retrieval된 토큰은 encoder transformer에 입력되어 neighbour 집합을 인코딩하고, 이를 통해 intermediate activation을 계산한다. 그 다음, transformer decoder는 Retro-blocks와 standard Transformer block을 교차하여 사용한다. 이 block들은 fully-connected layer, standard sequence-level self-attention layer, 그리고 retrieval encoder에서 정보를 통합하는 청크화된 cross-attention layer로 구성된다.
$$ RETRO(H, E) \triangleq FFW(CCA(ATTN(H), E)), \ and \ \ LM(H) \triangleq FFW(ATTN(H)) $$

Ffw, Attn 및 Cca는 모두 특정 위치에서의 출력이 해당 위치 이전의 입력에만 의존하는 autoregressive 연산자이다. 이들을 통해 Retro 및 lm 계층의 연속성과 토큰 분류 헤드는autoregressive log-likelihood를 정의한다.
Encoding retrieval neighbours. 각 청크 $C_u$에 대한 $k$개의 retrieval neighbour는 bi-directional transformer encoder를 통해 인코딩되며, 이를 통해 출력 $E_u^j$가 생성된다. retrieval encoder는 non-causal transformer로, cross-attention layer를 통해 청크 $C_u$의 활성화에 조건화된다. 이는 retrieval encoder의 표현이 retrieval 청크에 의해 미분 가능한 방식으로 조절될 수 있음을 의미한다. 모든 청크에 대한 모든 neighbour는 병렬로 인코딩되어, 전체 인코딩 집합 $E$를 생성한다.
Chunked cross-attention. CCA 연산을 수행하기 위해, 주어진 중간 활성화 $H$를 $l-1$개의 청크 $H_u^+$로 분할한다. $H_u^+$는 청크 $C_u$의 마지막 토큰과 $C_{u+1}$의 첫번째 $m - 1$ 토큰의 중간 임베딩을 가지고 있다. 이는 청크 $C_u$에서 가져온 인코딩된 retrieval 세트인 $E_u$와의 cross-attention을 계산한다. 이때, time과 neighbour를 동시에 고려하며, 이는 cross-attention 적용 전에 $E_u$의 neighbour와 time dimension을 병합하기 때문이다. 데이터 청크와 retrieval neighbour 사이의 정렬 개념이 있기 때문에, relative positional encoding을 사용한다.
시간에 따라 cross-attention의 출력들을 연결하여 출력 활성화 $CCA(H, E)$를 만든다. 이는 각 청크와 토큰에 대해 설정된다. 이 과정은 결과를 적절히 패딩하여 진행된다.
$$ CCA(H, E)_{u \ m+i-1} \triangleq C_A(h_{u \ m+i-1}, E_u) $$
$C_A$는 시간에 따라 인코딩된 neighbour를 대상으로 하는 cross-attention residual 연산자이다. 이 연산자는 세 개의 매개 변수 행렬 $K$, $Q$, $V$로 정의되며, 이는 모든 $h$와 $Y$에 대해 적용된다.
$$ C_A(h, Y) \triangleq softmax(YKQ^Th)YV $$
두 번째 차원에서 softmax를 적용하고, 모든 연산은 행렐 곱셈을 사용한다. multi-head cross-attention을 사용하며, positional encoding을 softmax에 추가한다.
첫 번째 $m − 1$ 토큰들은 이전 청크의 neighbour를 참조할 수 없다. 이 위치에서는 CCA를 항등 함수로 정의하며, 마지막 토큰은 마지막 retrieval 세트를 참조한다. CCA의 간략한 구현이 제공되며, 청크화된 cross-attention은 autoregressive하다. 즉, CCA의 출력은 CCA에 입력된 토큰 시퀀스에 의존한다.
RETRO 모델에서, 각 CCA cross-attention은 이전 청크의 neighbour만을 참조하지만, 이전 neighbour에 대한 의존성은 self-attention 연산을 통해 전달된다. 따라서, $u$ 번째 청크의 $i$ 번째 토큰의 활성화는 모든 이전 neighbour에 의존할 수 있지만, 그 집합에 대한 cross-attention의 제곱 비용은 발생하지 않는다.
Sampling. 샘플링 과정에서, 청크 $C_u$의 끝에서 SCaNN을 사용해 neighbour를 retrieval하고, 이를 인코딩하여 다음 청크 $C_{u+1}$의 생성을 조절한다. 샘플링의 총 비용은 샘플링된 시퀀스의 크기에 비례하며, retrieval의 추가 비용은 청크 수에 선형적이지만, 실제로는 토큰 샘플링 비용에 비해 무시할 수 있다.
Baseline Transformer architecture

일반적인 transformer에 몇 가지 최소한의 변경을 가한 모델을 사용하다. 이는 LayerNorm을 RMSNorm으로 대체하고 relative position encoding을 사용하는 등의 변경을 포함한다. 베이스라인으로는 parameter 수가 다양한 retrieval없는 transformer를 학습시켰다. 모든 retrieval 모델은 같은 크기의 encoder를 사용하며, 추가적인 parameter가 있는데, 이는 retrieval 데이터에 대한 인코딩 때문입니다. 모든 모델은 JAX와 Haiku를 사용하여 구현되었다.
Quantifying dataset leakage exploitation
RETRO 모델은 학습 세트에 포함된 데이터로 평가를 통해 이점을 얻을 수 있다. 그래서, 학습과 평가 데이터셋의 중복에 따른 성능 변화를 정량화하여, retrieval이 언어 모델링 성능에 어떤 영향을 미치는지 이해하려고 한다.
평가 시퀀스를 청크로 나누고, 각 청크에 대해 학습 데이터에서 가장 가까운 neighbour를 찾는다. 이후 평가 청크와 neighbour 사이의 가장 긴 토큰 부분 문자열을 계산하여, 평가 청크와 학습 데이터 사이의 중복 정도를 측정한다. 이를 통해 각 청크의 log-likelihood와 인코딩하는 바이트 수를 얻어, 모델의 필터링된 bits-per-bytes를 계산한다.
$$ ∀\alpha \in [0, 1], \ C_{\alpha} \triangleq \lbrace C \in C, r(C) \leq \alpha \rbrace, \ bpb(\alpha) \triangleq {{\sum_{C \in C_{\alpha}} l(C)}\over{\sum_{C \in C_{\alpha}} N(C)}} $$
이는 학습 청크와 $\alpha %$ 미만으로 중복되는 청크 집합에 대한 bits-per-bytes를 나타낸다. $bpb(·)$ 함수는 평가 유출이 예측 성능에 어떤 영향을 미치는지 평가하는데 사용되며, $\alpha$가 낮은 경우 모델이 완전히 새로운 청크에서 어떻게 작동하는지를, $bpb(·)$의 기울기는 모델이 평가 유출을 얼마나 활용하는지를 나타낸다.
Related Work
기존의 언어 모델링을 위한 retrieval 사용에 대한 연구를 검토하고, 이와 Retro를 비교한다. 인터넷의 큰 부분을 포함하는 대규모 데이터셋에서 RETRO 모델을 학습함에 따라, 작업은 개인정보, 안전, 공정성과 관련된 문제를 제기하게 된다.
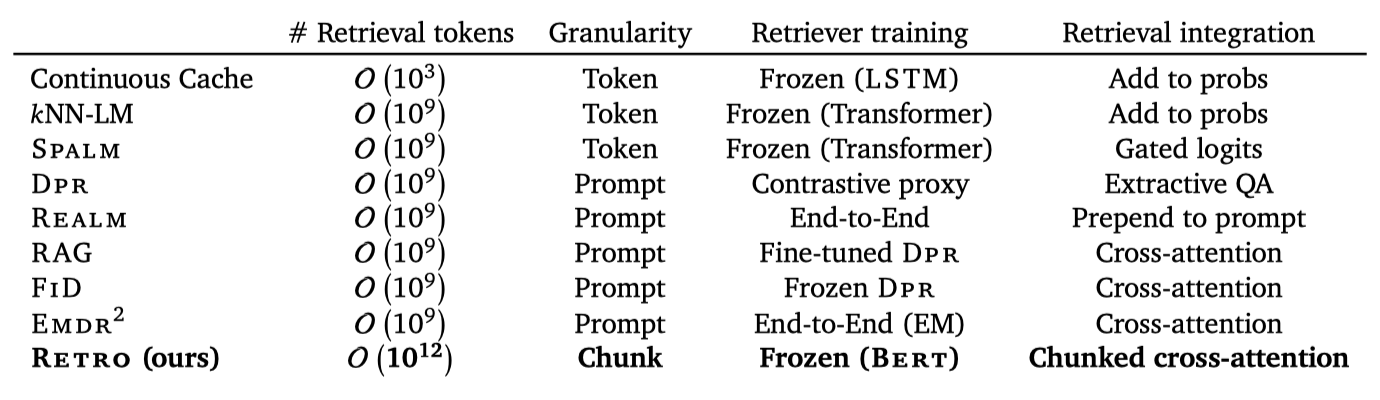
Retrieval for language modelling
Brants et al. (2007)은 학습 데이터를 trillion 개의 토큰으로 확장하면 기계 번역 성능이 상승한다고 밝혔다. 최근에는 GPT-2, GPT-3, 그리고 Jurassic-1이 언어 모델의 확장을 통해 다양한 작업에서 성능 향상을 보여주었다. 한편, Carlini et al. (2021)은 대규모 언어 모델이 학습 데이터의 일부를 완벽하게 기억하며, 이를 통해 모델의 성능을 더욱 향상시킬 수 있음을 제안하였다. 그러나 학습과 테스트 데이터 세트 간의 유출로 인해 대규모 데이터를 이용한 모델의 비교 및 평가가 어려운 상황이며, 이는 학습 데이터에 대한 retrieval 기능이 추가됨에 따라 더욱 복잡해진다.
텍스트 정보 retrieval은 전통적으로 TF-IDF나 BM25 같은 역색인 매칭을 사용했었다. 초기 연구에서는 LDA와 같은 latent topic 모델링을 사용해 relevant neighbour를 찾았다. 기계 번역 분야에서는 원문 문장 간의 편집 거리를 기반으로 번역 쌍을 retrieval 하고, 가장 가까운 대상 문장을 이용해 번역을 진행하였다. 또한, retrieved 데이터베이스는 구조화되어 있을 수 있으며, 예를 들어 Ahn et al. (2016)은 심볼릭 지식 그래프를 사용해 RNN 언어 모델을 향상시켰다.
딥러닝의 성공에 따라, retrieving 시스템은 neural network’s activation에 기반한 dense 학습 표현으로 부분적으로 전환되었다. continuous cache와 KNN-LM은 이전 활성화와 현재 활성화 벡터의 유사성을 이용하여 모델의 컨텍스트를 확장하고, 이를 통해 성능을 개선하였다. 이 방법들은 추가 학습 없이 모델에 적용할 수 있지만, retrieval된 텍스트에 대한 추론 능력을 제한하다. 이를 해결하기 위해 Spalm은 추가적인 게이팅 네트워크를 도입했지만, 대부분의 네트워크는 추론 과정에서 retrieval의 영향을 받지 않는다.
retrieval 표현은 사전 학습 모델에 의존하는 대신 직접 학습되며, 이는 주로 오픈 도메인 질문 응답에 사용된다. DPR은 두 개의 Bert 모델을 학습하여 질문과 답변의 표현을 맞추며, Lee et al. (2019)은 inverse cloze 작업을 이용해 retrieval을 위한 구절의 의미 표현을 찾았다. 이 방법들은 텍스트의 구절을 함께 임베딩하며, retrieval 네트워크는 독립적으로 학습된다. 이 문제를 해결하기 위해 REALM은 end-to-end 학습을 통해 최종 교차 엔트로피를 최대화하였으며, RAG와 FID는 encoder-decoder transformer 모델을 학습하여 질문 응답 벤치마크에서 state-of-the-art를 달성하였다. 최근에는 EMDR2가 이를 더욱 발전시켜 종단간으로 retriever를 학습시키고 최고 성능을 달성하였다.
오픈 도메인 대화에서 BlenderBot 2.0은 텍스트 기반 인터넷 쿼리를 학습하여 인간의 응답에 가까운 모델 응답을 측정하는 작업에서 dense retrieval 방법을 능가한다. 이 접근법의 확장성은 retrieval 쿼리와 연관된 인간 대화 데이터셋 수집에 제한된다. Hashemi et al. (2020)은 문서 retrieval과 명확한 질문 선택을 위한 가이드된 transformer를 소개했으나, 이 방법들은 RETRO와는 달리 임의의 텍스트 시퀀스를 모델링하기 위해 설계되지 않았다.
RETRO는 KNN-LM 및 DPR과 같이 frozen retrieval representation을 사용하며, QA 예시보다 긴 시퀀스를 모델링한다. 이는 시퀀스의 다른 부분에 대해 다른 문서를 retrieve 하는 것을 필요로 한다. encoder에서 retrieved neighbour을 개별적으로 처리하며, 이를 청크화된 cross-attention에서 조립한다. 청크를 사용하면 프롬프트만을 기반으로 한 번만 검색하는 것이 아니라, 시퀀스를 생성하는 동안 반복적으로 검색할 수 있다. 또한, RETRO는 전체 사전 학습 과정 동안 검색을 수행하며, 작은 모델과 3B 토큰 미만의 retrieval 데이터셋을 사용하는 dense 쿼리 벡터 기반의 이전 방법들과는 다르다.
Privacy, safety and fairness
Bender et al. (2021)과 Weidinger et al. (2021)은 대규모 언어 모델의 위험성을 지적한다. 이 위험성은 학습 데이터의 기억, 높은 학습 비용, 데이터의 정적 특성, 학습 데이터의 편향을 확대하는 경향, 그리고 유해한 언어 생성 능력에서 비롯된다. 이러한 위험성은 retrieval augmented 언어 모델이 악화시키거나 완화할 수 있다.
대규모 언어 모델은 학습 데이터를 완벽하게 기억하며, 이는 개인정보와 안전성 문제를 야기한다. 추론 시에 전체 학습 데이터에 접근할 수 있는 retrieval 모델은 이러한 문제를 악화시키지만, 검색 가능한 데이터를 추론 시간에 제거하는 방법으로 이를 완화할 수 있다. 또한, 차등 개인정보 보호 학습은 모델 가중치에 개인 정보가 저장되지 않도록 보장하며, 개인 데이터에 대한 개별화는 추론 시간에 retrieval 데이터베이스를 업데이트함으로써 이루어질 수 있다.
대규모 언어 모델의 높은 학습 비용 때문에 새로운 데이터, 언어, 규범을 포함시키기 위한 재학습은 매우 비싸다. retrieval 모델을 최신 상태로 유지하기 위해, retrieval 데이터베이스를 업데이트하는 것이 비용 효율적일 수 있다. 이는 대규모 언어 모델을 학습하는 데 상당한 에너지 비용이 들기 때문에 중요하며, retrieval 메커니즘은 언어 모델을 학습하고 업데이트하는 데 필요한 컴퓨팅 요구 사항을 줄이는 방법을 제공한다.
대규모 언어 모델은 유해한 출력을 생성하는 경향이 있으며, 이는 학습 데이터의 큐레이션과 문서화가 중요함을 강조한다. 학습 후에 편향된 또는 유해한 출력을 유발하는 데이터가 발견되면, 검색을 통해 이를 일부 수정할 수 있다. 하지만, 신중한 분석과 개입 없이는, retrieval 모델은 학습 데이터의 편향을 악화시키거나, 검색 문서의 선택 메커니즘을 통해 추가적인 편향을 생성할 수 있다. 이에 따라, 모델 출력의 편향성과 독성에 검색이 어떻게 영향을 미치는지 더 잘 이해하기 위한 추가 연구가 필요하다.
대규모 모델에서의 샘플은 해석하기 어려워, 이를 완화하는 것이 어렵다. 그러나, 검색은 모델의 출력에 대한 더 많은 통찰력을 제공하며, 사용되는 이웃을 직접 시각화하거나 수정할 수 있다. 특정 예시들은 검색이 언어 모델을 더 사실적이고 해석 가능하게 만들어, 더 투명한 출력을 제공하는 방법을 보여준다.
Results
언어 모델링 벤치마크 결과를 처음으로 보고하고, 사전 학습된 Transformer 언어 모델을 검색 모델로 변환하는 방법을 보여준다. 그 다음에는 질문 답변에 대한 RETRO 결과를 보고하고, 마지막으로 검색을 통한 이익의 원처를 더 잘 이해하기 위한 유출 필터링 평가를 보고한다.
Language modelling
Datasets. C4, Wikitext103, Curation Corpus, Lambada, 그리고 Pile에서 모델을 평가하며, 사전 학습과 검색 데이터셋 수집 이후에 추가되거나 크게 수정된 위키백과 기사 세트에서도 평가를 진행한다. 이를 위해 “future"의 기사로부터 데이터셋을 구성하고, 학습 데이터와 강하게 중복되는 새 기사를 제거하여 평가 문서가 학습 데이터에 유출되지 않도록 한다.
C4, Wikitext103, Pile, 그리고 위키백과 데이터셋에서는 전체 문서에 대한 언어 모델링 성능을 평가하며, 바이트당 비트를 측정한다. 토크나이저에 구애받지 않기 위해 이를 손실보다 선호한다. 2048 토큰의 시퀀스로 평가하되, boundary effect를 완화하기 위해 문서 내에서 1024의 스트라이드를 사용한다. Curation Corpus에서는 기사와 요약을 연결하여 평가하고, Lambada에서는 마지막 단어의 정확도를 평가한다.
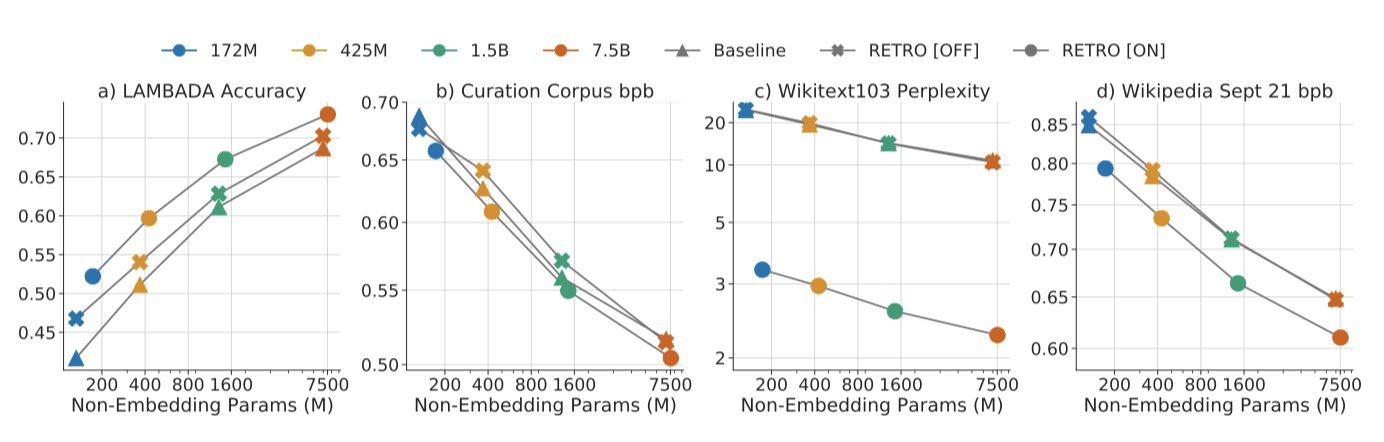
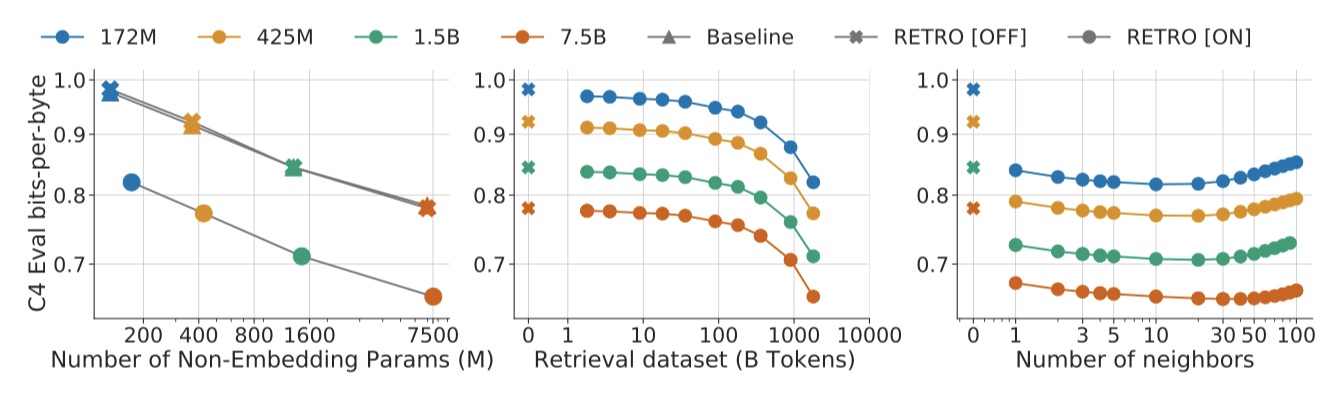
Model scaling. 모델을 확장하면서 언어 모델링 성능을 평가한 결과, 모든 데이터셋에서 RETRO가 모든 모델 크기에서 기준선을 초과하였다. 이는 모델을 확장해도 성능 개선이 줄어들지 않음을 보여준다. 성능은 데이터셋에 따라 다르며, Wikitext103와 C4에서 가장 큰 이익을 보였다. 반면, Curation Corpus에서는 RETRO가 기준선을 약간만 초과하였다. 이는 요약이 원문 기사에서만 정보를 포함하도록 설계되었기 때문이다. “future"의 위키백과 2021년 9월 데이터셋에서도 모든 모델 크기에 대해 일관된 이익을 관찰하였다.
Data scaling. 평가 시 retrieval 데이터베이스를 확장하면 언어 모델링 성능이 향상되는 것을 확인할 수 있다. 위키백과에서 Massive text로 검색 데이터를 확장하면 큰 이익이 있다. 또한, 검색된 청크의 수를 증가할 때 모든 모델의 성능이 일관되게 개선되며, 더 큰 모델은 더 많은 이웃을 더 잘 활용할 수 있음을 확인할 수 있다.
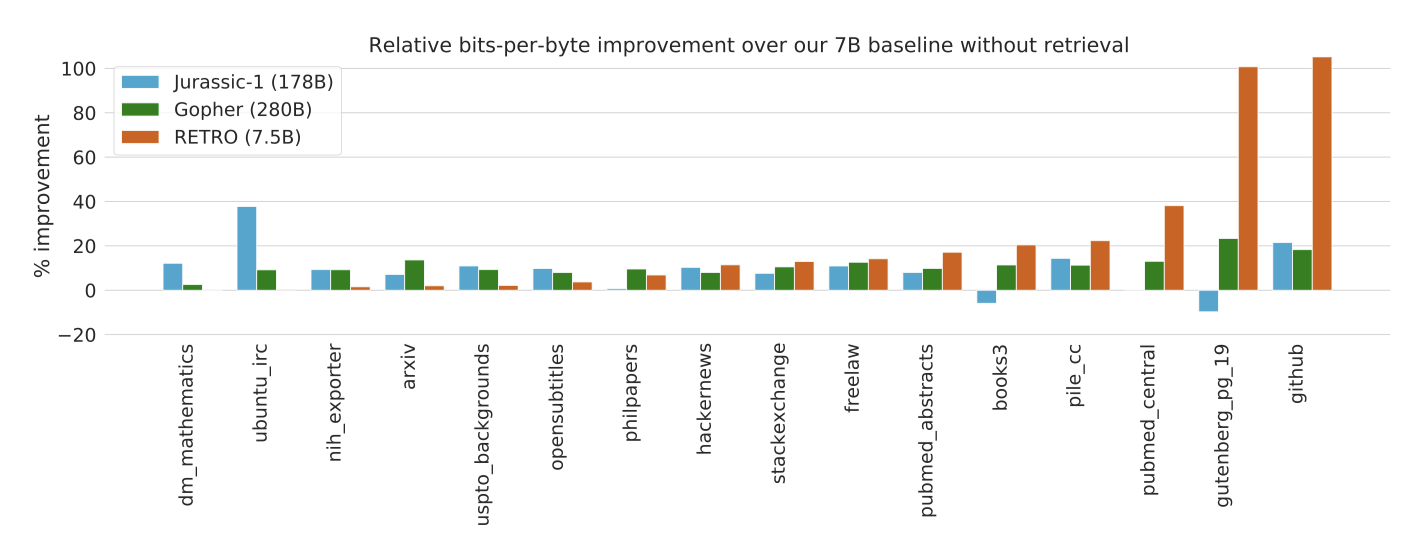
The Pile. 7B 모델을 Pile 테스트 세트에서 평가하고, 178B parameter의 Jurrasic-1 모델과 280B parameter의 Gopher 모델과 비교한다. RETRO 7.5B 모델은 대부분의 테스트 세트에서 Jurassic-1과 Gopher를 능가하는 것으로 나타났다. 하지만, dm_mathematics와 ubuntu_irc 부분집합에서는 RETRO 모델이 기준선을 능가하지 못하고 Jurassic-1을 미치지 못하였다. 이는 retrieved neighbour가 도움이 되지 않아서라고 가정한다.
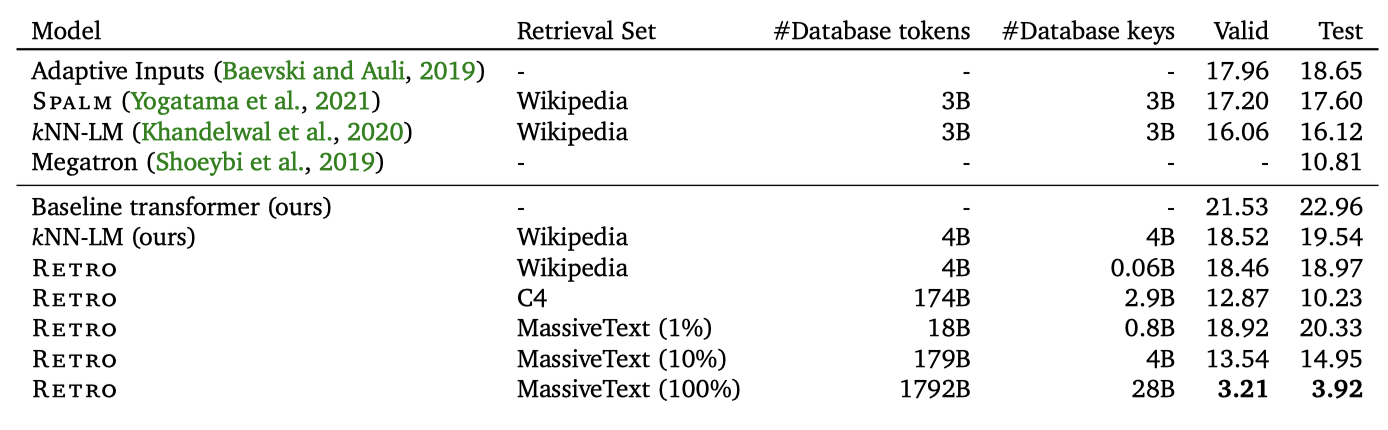
Wikitext103. Wikitext103 데이터셋에서 KNN-LM와 이 논문의 방법을 비교하여 접근법을 검증한다. baseline transformer는 24개의 layer, 1024개의 hidden units, 16개의 heads, 그리고 64의 key size를 가지고 있다. 기준선은 adaptive input을 가지고 있지 않고, 열린 어휘를 가진 토크나이저를 사용하기 때문에 perplexity가 조금 높다.
KNN-LM을 재구현하여 Wikitext103의 모든 토큰에 대해 1024 크기의 임베딩을 생성한다. KNN-LM의 확률은 $p_{KNN-LM} = \lambda p_{KNN} + (1 − \lambda) p_{L_M}과 $p_{KNN} (n_k) \propto exp (− \alpha d_k)$의 형태를 가진다. 검증 세트에서 $\lambda = 0.118$과 $\alpha = 0.00785$를 조정하고, 이 hyperparameter에 대한 성능을 검증 세트와 테스트 세트에서 보고한다.
baseline transformer를 RETRO 모델로 미세 조정하며, 이를 위해 Wikitext103 학습 데이터를 사용하고, 2개의 이웃이 있는 위키백과에서 검색한다. 새로운 가중치만 학습시키고, encoder와 주 경로 사이의 임베딩 가중치를 공유한다. 이는 Wikitext103의 작은 크기 때문에 필요하며, 아니면 RETRO 학습이 과적합을 초래할 수 있다.
다양한 retrieval 세트를 사용하여 미세 조정된 RETRO 모델을 평가한다. 위키백과에서 검색할 때 KNN-LM 구현과 비슷한 결과를 얻었다. retrieval 데이터베이스를 MassiveText로 확장하면 큰 개선을 보이지만, 이는 부분적으로 정보 유출 때문이다. 재현성을 위해 C4에서 검색한 결과도 포함되어 있으며, 이는 이전 state-of-the-art와 비슷하며 MassiveText의 10%를 사용한 결과와 비교할 수 있다.
KNN-LM은 retrieval 데이터셋의 모든 토큰에 대해 1024개의 실수 값을 요구하며, 이로 인해 위키백과의 40억 토큰에 대해 총 15Tb가 필요하다. 따라서 KNN-LM과 같은 토큰 레벨 검색 방법은 MassiveText처럼 trillion 개의 토큰을 가진 검색 데이터베이스에는 적용하기 어렵다. 반면, RETRO는 위키백과 데이터셋 인덱싱에 215Gb, MassiveText에는 93Tb가 필요하며, 이는 청크 레벨에서 검색이 trillion 개의 토큰을 가진 데이터셋으로 확장할 때 필요함을 보여준다.
RETRO-fitting baseline models
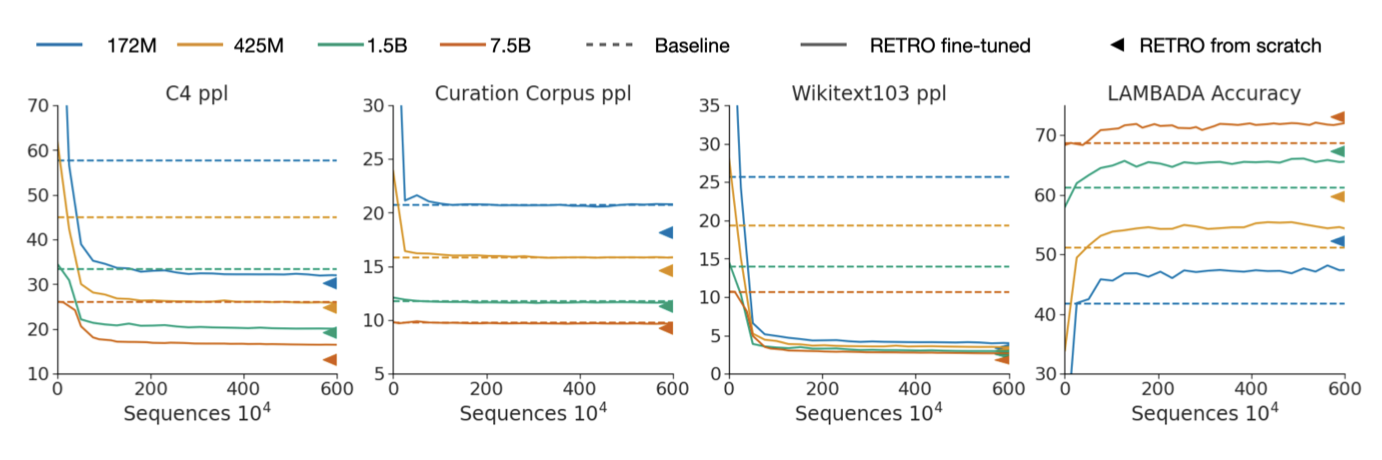
청크화된 cross-attention과 neighbour encoder parameter을 학습시키는 것으로 기본 모델을 RETRO 모델로 확장한다. 이 방법은 효율적인 retrieval-enhance 경로로, 사전 학습 시퀀스의 3%인 600만 개의 시퀀스만 필요로 한다. 새로운 가중치만 학습시키므로, 검색 없이 평가할 때 기존 모델 성능이 유지된다. Retrofitting 모델은 빠르게 기본 모델 성능을 넘어서고, 처음부터 학습된 RETRO 모델에 가까운 성능을 달성한다.
Question answering
Natural Questions 데이터셋을 이용해 사전 학습된 RETRO 모델을 미세조정하며, 임의의 데이터 소스로부터 정보를 주입하는 검색 경로를 활용함을 보여준다. 이 과정에서, DPR에서 검색된 문단들로 보강된 버전을 사용하고, 상위 20개의 검색된 문단을 이용해 모델을 25,000 단계로 미세조정한다. 데이터는 “question: {question} \n answer: {answer}” 형식으로 정리되며, 첫 검색 청크와 정렬하기 위해 왼 패딩된다. 이 모델은 이전 토큰을 통한 질문과 청크화된 cross-attention mechanism을 통한 위키백과 문단들에 접근할 수 있다.
REALM, RAG, DPR와 같은 이전 방법들과 경쟁력이 있지만, 최근의 FiD에는 미치지 못한다. neighbour의 수를 20개 이상으로 늘려도 RETRO의 성능은 향상되지 않는다. T5의 encoder-decoder 구조와 사전 학습 목표가 QA 환경에서 encoder 출력에 더 의존하는 모델을 만들어낸다고 가설을 세웠다. RETRO가 토큰을 생성할 때 retrieval encoder 출력에 더 의존하도록 하는 연구가 필요하다고 생각한다.
Relating retrieval performance to dataset leakage.
C4, Curation Corpus, Wikitext103에 대한 필터링된 평가 손실을 보고합니다. 학습 세트로 유출되는 C4와 Wikitext103에서, RETRO 모델은 기본 모델보다 유출을 더 강하게 활용한다. 이는 기존 학습 청크를 복사-붙여넣기하여 유출된 평가 청크를 예측하는 능력 때문이다. 반면, Curation Corpus에서는 검색이 일정한 오프셋을 제공하는데, 이는 Curation Corpus와 학습 데이터셋 사이에 설계상 유출이 없기 때문이다.
RETRO는 모든 유출 수준에서 기본 모델을 능가하며, 지역적 유출이 없다고 판단되는 수준인 $\alpha = 12.5%$에서의 성능도 보여준다. 검색은 학습 세트의 청크와 구문적으로 비슷하거나 다른 청크에 대한 예측을 향상시키는데, 이는 RETRO의 모델 parameter와 검색 데이터베이스를 기반으로 한 일반화 능력을 보여준다. 이와 비슷한 결과는 Pile 데이터셋에서도 확인되었다.
Using Retro for sampling
샘플링된 청크와 검색된 이웃 청크를 비교하고, 공통 접두사의 길이에 따라 색칠하여 지역적 겹침을 나타낸다. 샘플링된 토큰과 이웃 토큰 사이에 겹침이 있어, 검색된 청크가 샘플에 영향을 주는 것을 관찰할 수 있다. 검색은 환영을 줄이고 모델을 더 지식이 많게 만든다.
Conclusion
Retrieval-Enhanced Transformers (RETRO)를 소개한다. 이는 trillion 개의 토큰을 가진 데이터베이스에서 검색하며 임의의 텍스트 시퀀스를 모델링하는 방법으로, 학습 중에 소비되는 데이터에 비해 모델에서 사용할 수 있는 데이터의 규모를 수십 배로 확장한다. RETRO는 적어도 7B parameter까지 모델의 이점을 유지하며, 특정 데이터셋에서는 10배 더 많은 parameter를 가진 모델에 해당한다. 또한, RETRO는 대규모 데이터셋에서 학습된 이전 모델을 능가하며, 질문 응답과 같은 검색 중심의 작업에서 경쟁력이 있다.
RETRO 모델은 평가 시 검색 없이도 기본 모델과 비슷한 성능을 보이며, 기본 모델은 빠르게 RETRO 모델로 미세 조정하여 처음부터 학습한 것과 유사한 성능을 얻을 수 있다. 심도 있는 분석에 따르면, RETRO 모델이 얻는 이익 중 일부만이 테스트 세트 유출로 인한 것이다. 따라서, 대규모 언어 데이터셋에서의 유출에 대해 주의하고, 이 유출이 대규모 언어 모델 성능에 어떤 역할을 하는지 더욱 이해하는 데 추가 연구가 필요하다는 것을 제안한다.
이 연구는 전례 없는 규모에서 semi-parametric 접근법이 더 강력한 언어 모델을 구축하는데 있어 raw parameter 스케일링보다 orthogonal 하고 효율적인 방법을 제공할 수 있음을 보여준다.