Abstract
웹 검색과 탐색 기능을 갖춘 GPT-3를 미세 조정하여 장문의 질문에 대답하도록 했다. 인간이 수행 가능한 작업 설정을 통해 모델을 학습시키고, 인간의 피드백으로 답변 품질을 최적화하였다. 사실 확인을 위해 모델은 브라우징 중 참조 정보를 수집한다. 이 방식은 Reddit의 질문 데이터셋 ELI5에서 효과적이었으며, 최적의 모델은 인간의 선호도를 예측하는 보상 모델을 통해 얻어졌다. 이 모델의 답변은 인간 평가자와 Reddit의 최고 투표 답변에 비해 각각 56%, 69%의 경우에 선호된다.
Introduction
자연어 처리(NLP) 분야에서는 개방형 질문에 대한 장문 답변을 생성하는 long-form question-answering(LFQA)이 주요 도전 과제로 떠오르고 있다. LFQA는 학습 도구로서의 잠재력이 있지만, 아직 인간의 수준에는 미치지 못하고 있다. 대부분의 연구는 정보 검색과 종합, 이 두 가지 핵심 요소에 집중하고 있다.
이 연구에서는 문서 검색을 Microsoft Bing Web Search API에 위임하고, GPT-3를 미세 조정하여 종합능력을 향상시킨다. 개별 요소의 개선보다는 이들을 신뢰성 있는 학습 목표로 결합하는 데 초점을 맞추었다. 인간의 피드백을 이용해 답변 품질을 직접 최적화하였고, 인간 수준의 성능을 달성하였다.
이 연구는 두 가지의 주요한 기여를 하였다:
- 미세 조정된 언어 모델이 상호작용할 수 있는 텍스트 기반 웹 브라우징 환경을 개발하였고, 이를 통해 imitation 학습과 강화 학습 등을 활용하여 정보 검색과 종합을 통합적으로 개선하였다.
- 모델은 웹 탐색 중 추출한 구문을 참조하여 답변을 생성한다. 이는 라벨러들이 복잡하고 주관적인 독립 연구 과정 없이도 답변의 사실 정확성을 판단하는데 중요하였다.
모델은 주로 “Explain Like I’m Five” subreddit의 질문을 대답하는 ELI5 데이터셋으로 학습되었다. 추가로 인간의 웹 브라우징 환경 사용 시연과 모델이 생성한 두 가지 답변의 비교를 수집하였다. 답변들은 사실 정확성, 일관성, 전반적인 유용성에 대해 판단하였다.
이 데이터는 행동 복제, reward 모델링, 강화 학습, rejection 샘플링 등 네 가지 주요 방법으로 사용되었다. 최적의 모델은 행동 복제와 rejection 샘플링을 결합하였고, 추론 시간이 제한적일 때는 강화 학습이 일부 이점을 제공하는 것을 확인하였다.
이 연구의 최고 모델은 세 가지 방법으로 평가되었다. 첫째로, 인간 시연자의 답변에 대해 모델의 답변이 56%의 경우 선호되어 텍스트 기반 브라우저의 인간 수준 사용을 입증하였다. 둘째로, ELI5 데이터셋의 최고 투표 답변에 대해 모델의 답변이 69% 선호되었다. 마지막으로, 짧은 형태의 질문 데이터셋인 TruthfulQA에서 모델의 답변이 75% 참이었으며, 참이면서 유익한 경우는 54%었다. 이는 기본 모델(GPT-3)를 능가하지만 인간의 성능에는 미치지 못하였다.
Environment design
이전 연구들은 주어진 쿼리에 대한 문서 검색 개선에 초점을 두었지만, 이 연구에서는 검색 엔진인 Bing을 사용하여 대량의 최신 문서를 인덱싱하며, 검색 엔진을 사용해 질문에 답하는 고수준 작업에 집중할 수 있게 해주는 두 가지 주요 이점을 제공한다. 이는 인간이 잘 수행하고 언어 모델이 모방할 수 있는 작업이다.

텍스트 기반 웹 브라우징 환경을 설계하였다. 언어 모델은 환경의 현재 상태, 질문, 현재 페이지의 텍스트 등에 대한 요약을 받아서, Bing 검색 실행, 링크 클릭, 스크롤 등의 명령을 수행한다. 이 과정은 새로운 컨텍스트로 반복되며, 이전 단계의 정보는 요약에 기록된 내용만 기억한다.
모델이 웹 브라우징 중에는 현재 페이지에서 발췌문을 인용하는 행동을 할 수 있다. 이 때, 페이지 제목, 도메인 이름, 발췌문이 참조로 기록된다. 브라우징은 모델이 종료 명령을 내리거나, 최대 행동 수 또는 참조의 최대 길이에 도달할 때까지 계속된다. 최소한 하나의 참조가 있을 경우, 모델은 질문과 참조를 받아 최종 답변을 작성한다.
Methods
Data collection
이 연구의 접근법은 인간의 지도를 중심으로 한다. 자연 언어에 대해 사전 학습된 언어 모델은 유효한 명령의 형식을 모르므로, 텍스트 기반 브라우저를 사용할 수 없다. 그래서 인간이 브라우저를 사용하여 질문에 답하는 예제를 수집하였다. 그러나 이런 예제만으로 학습하는 것은 답변 품질을 직접 최적화하지 못하며, 인간의 성능을 크게 넘어서지 못한다. 그래서 같은 질문에 대한 모델 생성 답변 쌍을 수집하고, 어느 것이 더 선호되는지 인간에게 피드백을 받았다.
시연과 비교 작업에서 대부분의 질문은 장문형 질문 데이터셋인 ELI5에서 가져왔다. 다양성을 위해 TriviaQA와 같은 다른 출처의 질문도 일부 섞었다. 총 6,000개의 시연을 수집했으며, 이 중 92%는 ELI5의 질문이었고, 21,500개의 비교를 수집했는데, 이 중 98%는 ELI5의 질문이었다.
인간이 시연을 제공하기 쉽도록, 환경에 대한 그래픽 사용자 인터페이스를 설계했다. 이 인터페이스는 텍스트 기반 인터페이스와 같은 정보를 제공하고 모든 유효한 동작을 수행할 수 있다. 비교를 위해 유사한 인터페이스를 설계했으며, 보조 주석과 비교 등급을 제공할 수 있지만, 학습에서는 최종 비교 등급만 사용되었다.
시연과 비교에서는 답변이 관련성이 있고, 일관성이 있으며, 신뢰할 수 있는 참조에 의해 지지되어야 한다는 것을 강조하였다.
Training
사전 학습된 모델의 사용은 우리 방법론의 핵심이다. 질문에 답하기 위해 환경을 성공적으로 활용하는데 필요한 능력들은 언어 모델의 zero-shot 능력으로부터 파생되며, 이에는 읽기 이해력과 답변 합성 능력이 포함된다. 따라서, 760M, 13B, 175B 크기의 GPT-3 모델 계열을 미세 조정하였다.
이 모델들을 시작으로, 주로 네 가지 학습 방법을 사용하였다:
- Behavior cloning (BC). 인간 시연자가 내린 명령을 레이블로 사용하여, 지도 학습을 통해 시연에 대해 미세 조정하였다.
- Reward modeling (RM). BC 모델에서 시작하여, 질문과 참조가 있는 답변을 입력으로 받고 스칼라 보상을 출력하는 모델을 학습시켰다. 이 reward는 Elo 점수를 나타내며, 두 점수 간 차이는 인간 레이블러에 의한 선호도 확률의 로짓을 표현한다. reward 모델은 비교를 레이블로 사용하여 cross-entropy 손실로 학습되며, 동점은 50%의 소프트 레이블로 처리된다.
- Reinforcement learning (RL). Stiennon et al. (2020)을 따라, PPO를 사용하여 환경에서 BC 모델을 미세 조정하였다. environment reward는 각 에피소드의 끝에서 reward 모델 점수를 받고, reward 모델의 과도한 최적화를 완화하기 위해 각 토큰에서 BC 모델의 KL penalty를 추가하였다.
- Rejection sampling (best-of-n). BC 모델이나 RL 모델에서 고정된 수의 답변을 샘플링하고, 그 중 reward 모델이 가장 높게 평가한 답변을 선택하였다. 이 방법은 추가 학습 없이 reward 모델을 최적화하는 대안 방법으로, 더 많은 추론 시간 계산을 사용한다.
BC, RM, RL 각각에 대해 상호 배타적인 질문 집합을 사용하였다. BC의 경우, 검증 세트로 사용하기 위해 시연 중 약 4%를 보류하였다.
RM에 대해, 다양한 크기의 모델을 사용하여 답변을 샘플링하고, 이들을 하나의 데이터셋으로 결합하였다. 이는 데이터 효율성을 위한 것으로, hyperparameter 조정 등의 평가 목적으로 많은 비교를 수집하고 이 데이터를 활용하기 위한 것이었다. 최종 reward 모델은 약 16,000개의 비교에 대해 학습되었고, 나머지 5,500개는 평가용으로만 사용되었다.
RL 학습은 ELI5의 질문 90%와 TriviaQA의 질문 10%를 사용하였다. 샘플 효율성을 높이기 위해, 각 에피소드 끝에 동일한 참조를 사용하는 15개의 추가 답변 에피소드를 삽입하였다. 이 방법은 샘플 효율성을 약 2배 향상시켰다. 또한, 20~100 사이에서 균등하게 샘플링하는 방식으로 브라우징 동작의 최대 수를 무작위로 설정하였다.
Evaluation
behavior cloning과 reward 모델에 대한 rejection 샘플링을 통해 학습된 세 가지 “WebGPT” 모델(760M, 13B, 175B)을 사용하여 접근법을 평가하였다. 이 모델들은 각기 다른 추론 시간 컴퓨터 예산에 맞춰져 있습니다. RL은 rejection 샘플링과 결합했을 때 큰 이익을 보이지 않아 제외하였다.
인간의 평가를 통해 조정된 샘플링 temperature 0.8을 사용하여 모든 WebGPT 모델을 평가했고, 최대 브라우징 액션 횟수는 100으로 설정하였다.
ELI5
두 가지 다른 방식으로 ELI5 테스트 세트에서 WebGPT를 평가하였다:
- 웹 브라우징 환경을 이용한 시연자의 답변과 모델이 생성한 답변을 비교하였다. 이 비교는 reward 모델 학습 때 사용한 방식과 동일하며, 공정한 비교라고 판단하였다. 왜냐하면 시연과 비교를 위한 지침들이 매우 유사한 기준을 강조하고 있기 때문이다.
- 모델이 생성한 답변을 Reddit의 ELI5 데이터셋의 참조 답변과 비교하였다. 실제 사용자의 기준과 비교 기준의 차이, 그리고 Reddit 답변이 보통 인용을 포함하지 않는 점 때문에 우려가 있었다. 이를 해결하기 위해, 모델 생성 답변에서 인용과 참조를 제거하고, 지침을 모르는 새 계약자를 고용하여 간단한 지침을 제공하였다.
두 경우 모두, 동점을 50%의 선호도 평가로 처리하였다.
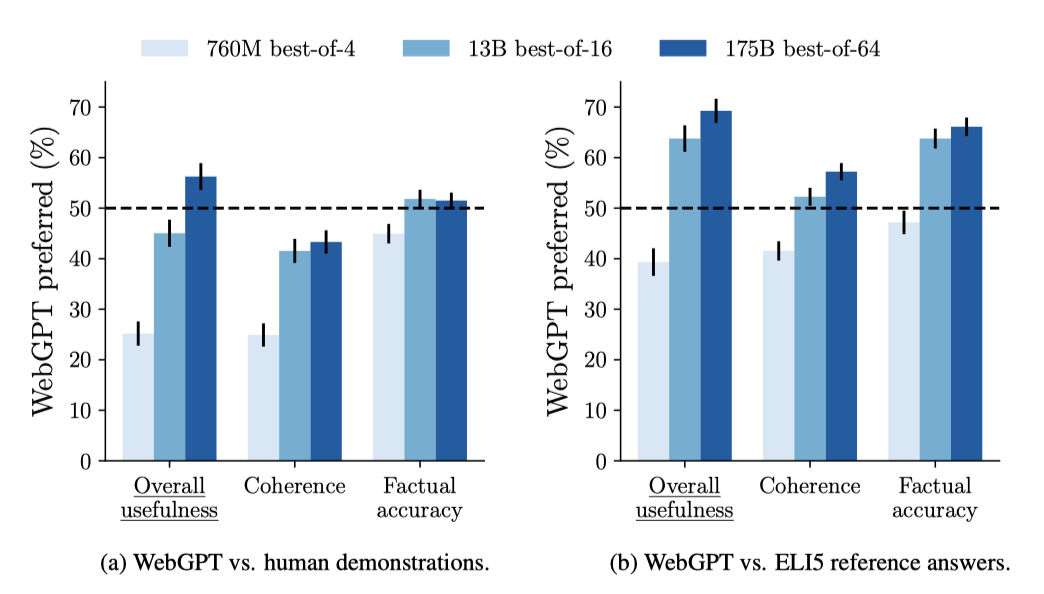
최적 모델인 175B best-of-64 모델은 56%의 비율로 인간 시연자의 답변보다 선호된다. 이는 인간의 피드백이 필수적임을 보여준다. 또한, 이 모델은 69%의 비율로 ELI5 데이터셋의 참조 답변보다 선호되며, 이는 Krishna et al. 의 연구보다 상당한 개선을 보여주는 결과이다. 그들의 모델은 참조 답변에 대해 23%의 선호도만을 보였고, 그들이 사용한 컴퓨팅은 가장 작은 모델보다도 적었다.
ELI5 참조 답변에 대한 평가는 이전 작업과의 비교에 유용하지만, 몇 가지 이유로 인간 시연에 대한 평가가 더 의미있다고 믿는다:
- Fact-checking. 참조가 없는 상태에서 답변의 사실 정확성을 평가하는 것은 전문지식이 필요할 정도로 어렵다. 그러나 WebGPT와 인간 시연자는 참조가 포함된 답변을 제공한다.
- Objectivity. 최소한의 지침 사용은 어떤 답변이 다른 답변보다 우월한 이유를 파악하기 어렵다. 반면, 상세한 지침은 더욱 명확하고 일관된 비교를 가능하게 한다.
- Blinding. 인용과 참조를 제거한 후에도 WebGPT는 Reddit 답변과 다른 스타일로 답변을 작성한다. 이는 비교가 덜 가려지게 만든다. 반면, WebGPT와 인간 시연자는 비슷한 스타일로 답변을 작성한다. 또한, 일부 ELI5 답변에 포함된 링크를 라벨러들이 따르지 않도록 지시한 것이 라벨러들의 편향을 초래했을 수 있다.
- Answer intent. 사람들은 웹에서 찾을 수 있는 답변 대신, 독특하고 간단한 설명을 얻기 위해 ELI5에 질문한다. 이는 답변을 판단하려는 기준이 아니며, 많은 ELI5 질문들은 소수의 노력이 적은 답변만을 받는다. 인간의 시연을 활용하면, 원하는 의도와 노력 수준을 일관되게 유지하는 것이 더 쉽다.
TruthfulQA
WebGPT의 능력을 더 깊게 이해하기 위해, 짧은 형태의 질문들로 이루어진 적대적 데이터셋인 TruthfulQA에서 평가를 진행하였다. TruthfulQA의 질문은 거짓된 믿음이나 오해로 인해 잘못 대답할 수 있는 질문으로 구성되어 있다. 답변은 진실성과 정보성 두 가지에 대해 평가받으며, 이 둘은 서로 교환 관계에 있다.
TruthfulQA에서 WebGPT와 그 기반이 되는 GPT-3 모델을 모두 평가하였다. GPT-3는 “QA prompt"와 “helpful prompt"를 사용하며, 자동화된 측정 기준을 이용하였다. 반면, WebGPT는 인간 평가를 사용하였다. 그리고 짧은 형태의 데이터셋인 TruthfulQA에 맞추기 위해 WebGPT의 답변을 50 토큰으로 잘라내고, 뒤따르는 부분적인 3문장을 제거하였다.
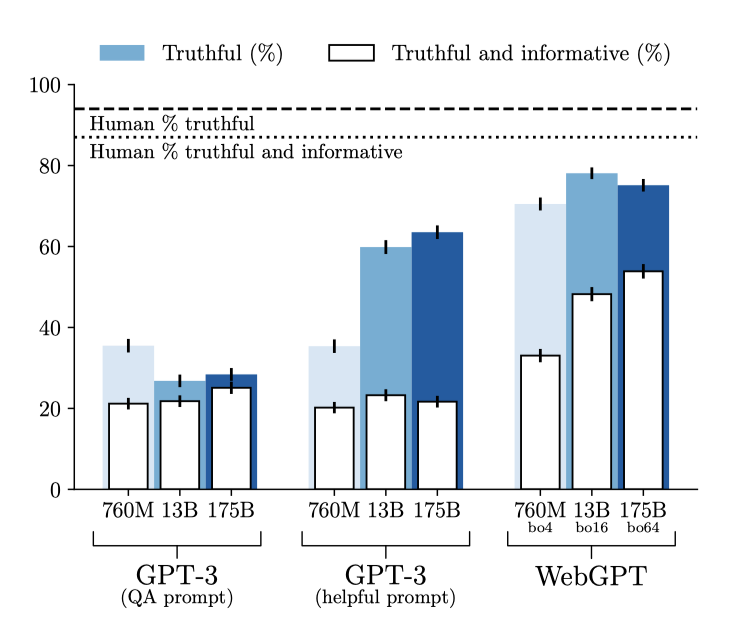
모든 WebGPT 모델은 진실성과 정보성 모두에서 모든 GPT-3 모델을 능가한다. 또한, WebGPT는 모델 크기가 커질수록 진실하고 정보적인 답변의 비율이 증가하지만, GPT-3는 그렇지 않다.
TriviaQA
또한 TriviaQA에서 WebGPT 175B BC 모델을 평가하였다.
Experiments
Comparison of training methods
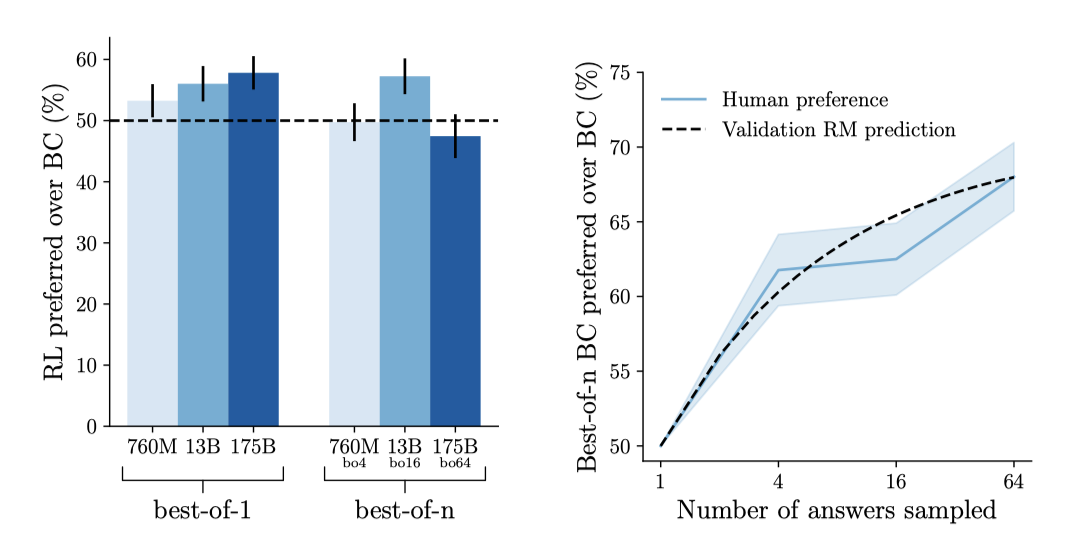
강화 학습(RL)과 rejection 샘플링(best-of-$n$)을 비교하고 behavior cloning(BC) 기준과 비교한 결과를 보준다. rejection 샘플링은 175B BC 모델에 비해 175B best-of-64 BC 모델이 68% 선호되는 큰 이점을 제공한다. 반면, RL은 175B BC 모델에 비해 175B RL 모델이 58% 선호되는 작은 이점을 제공한다.
rejection 샘플링과 RL이 동일한 reward 모델에 대해 최적화를 진행하지만, rejection 샘플링이 RL을 능가하는 몇 가지 가능한 이유가 있다:
- 단순히 더 많은 추론 시간 계산을 이용하기 위해 많은 답변 시도를 하는 것이 도움이 될 수 있다.
- 환경은 예측 불가능하므로, rejection 샘플링을 이용하면 모델은 더 많은 웹사이트를 방문하고, 그 후에 찾은 정보를 회고적으로 평가할 수 있다.
- reward 모델은 주로 BC와 rejection 샘플링 정책에서 수집된 데이터를 통해 학습되었으므로, 이로 인해 RL보다 rejection 샘플링에 의한 과도한 최적화에 더욱 강건할 수 있다.
- RL은 hyperparameter 튜닝이 필요하지만, rejection 샘플링은 그렇지 않다.
RL과 rejection 샘플링의 결합은 rejection 샘플링 단독보다 큰 이점을 제공하지 않는다. 이는 둘 다 같은 보상 모델에 대해 최적화를 시도하고, 특히 RL에서 쉽게 과도하게 최적화될 수 있기 때문이다. 또한, RL은 정책의 다양성을 줄이며, 이는 탐색에 악영향을 준다. rejection 샘플링 성능 최적화를 위해 RL 목표를 조정하는 것은 미래 연구의 흥미로운 주제이다.
BC 기준선을 조정함으로써 모델의 성능을 향상시키는 것의 중요성을 강조한다. 이를 위해 인간의 평가와 reward 모델 점수를 결합하여 BC epoch의 수와 샘플링 temperature를 조정하였다. 이런 조정으로 BC와 RL 사이의 성능 차이를 크게 줄였다.
Scaling experiments
데이터셋 크기, 모델 parameter 수, rejection 샘플링을 위한 샘플 수에 따른 모델 성능 변화를 실험하였다. 비용이 많이 드는 인간의 평가 대신, 별도 데이터셋에서 학습된 175B “validation” reward 모델의 점수를 사용하였다. 이는 RL을 사용하지 않을 때 인간의 선호도를 잘 예측했다. reward는 Elo 점수로, 1점 차이는 약 73%의 선호도 차이를 의미한다.
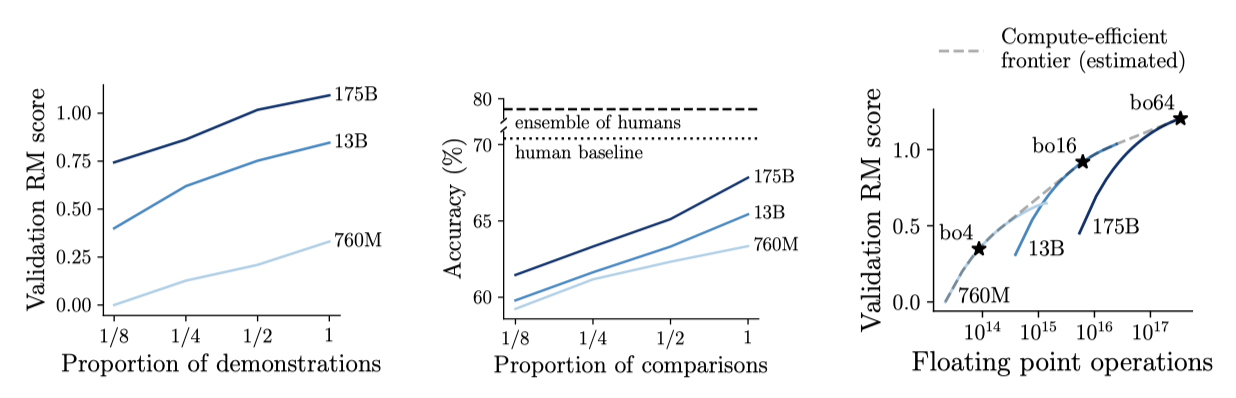
시연 수나 비교 수를 두 배로 늘리면 reward 모델의 점수와 정확도가 각각 약 0.13, 1.8% 증가하였다. 또한, parameter 수를 두 배로 늘렸을 때, reward 모델의 점수와 정확도는 대략 0.09, 0.4% 증가하는 추세를 보여주었다.
주어진 추론 시간 계산 예산에 따라 거부 샘플링을 위한 샘플 수와 모델 매개변수 수를 어떻게 균형있게 조절할지 분석하였다. 일정량의 rejection 샘플링 사용이 계산 효율적이라는 결과를 얻었다. 주요 모델들인 760M best-of-4 모델, 13B best-of-16 모델, 175B best-of-64 모델은 이런 균형의 최적점에서 선택되었다.
Discussion
Truthfulness of WebGPT
NLP 시스템이 발전하고 널리 사용됨에 따라, 거짓 정보를 줄이는 기술의 중요성이 증가하고 있다. WebGPT의 효과를 평가하기 위해, 모델이 생성하는 거짓 정보를 두 가지 유형으로 구분하는 것이 도움이 된다.
- Imitative falsehoods. 학습 목표에 의해 유도되는 거짓 정보는 무한한 데이터와 계산력이 있어도 발생한다. 이는 일반적인 오해를 재현하는 등의 경우를 포함한다.
- Non-imitative falsehoods. 모델이 학습 목표를 달성하지 못해 발생하는 거짓 정보에는 대부분 hallucination 현상이 포함된다. 이는 처음 보기에는 사실처럼 보이지만 실제로는 거짓인 주장을 말한다.

TruthfulQA 결과는 신뢰할 수 있는 출처를 선호하는 경향이 있는 WebGPT가 GPT-3보다 더 적은 거짓 정보를 생성한다는 것을 보여준다. 그러나 WebGPT는 가끔 불신뢰할 수 있는 출처를 인용하기도 한다. 이런 현상은 학습 데이터의 분포 변화 때문이라고 추정하며, 적대적으로 선택된 질문에 대한 학습이 이를 개선하는 유망한 방법이라고 생각한다. 출처의 신뢰성을 평가하는 것이 중요하다는 점을 강조한다.
연구 결과, WebGPT는 GPT3보다 더 적은 비모방적인 거짓 정보를 만들었다. 이는 정보 검색 사용이 hallucination 생성률을 줄이는 것을 보여주는 이전 연구와 일치한다. 또한, WebGPT는 사실 정확성에서 인간의 성능과 비슷하게 나타났다. 그러나, 정보를 요약하거나 통합하는 과정에서 가끔 실수를 하는 경우도 있었다.
Perceived truthfulness of WebGPT
WebGPT의 장단점을 평가하려면, 거짓 정보를 얼마나 자주 만드는지와 사용자가 그 정보를 얼마나 신뢰하는지를 모두 고려해야 한다. WebGPT는 GPT-3보다 거짓 정보를 덜 만들지만, 인용문 사용 등으로 인해 그 답변이 더 권위적으로 보일 수 있다. 이로 인해 “automation bias” 문제가 발생하고, 사용자가 WebGPT의 답변에 과도하게 의존할 수 있다. 특히, WebGPT는 일부 문제에서 인간보다 더 많은 오류를 범할 수 있다. 이러한 한계를 알리고 이를 완화하는 방법을 연구하는 것이 필요하다.
Reinforcement of bias
WebGPT는 기존의 가정과 편향을 강화하고 재생산하는 여러 방법을 가지고 있다. 첫째, WebGPT는 미세 조정된 기반 모델인 GPT-3의 편향을 상속받아 정보 검색과 통합 방식에 영향을 미친다. 둘째, 기존 출처로부터 정보를 통합함으로써, 기존의 신념과 규범을 강화하고 고착화시킨다. 마지막으로, 질문의 내포된 가정을 받아들이고 질문의 입장에 영향을 받아, 사용자의 확인 편향을 악화시킬 수 있다.
WebGPT의 기본 모델과 학습 목표를 개선함으로써 문제점을 완화할 수 있다. 다음 부분에서는 대안적인 목표에 대해 논의할 예정이다. 또한, 접근 제한과 애플리케이션 디자인의 맞춤화를 통해 WebGPT의 사용 방식을 제어하는 것도 중요하다.
Using references to evaluate factual accuracy
이 접근법의 핵심은 모델이 수집한 참고 자료를 사용하여 사실 정확성의 인간 평가를 돕는 것이다. 이는 이전에 Metzler et al. (2021)에 의해 제안되었으며, 여러 가지 이점이 있다:
- More accurate feedback. 기술적이거나 주관적이거나 모호한 임의의 주장의 사실 정확성을 평가하는 것은 매우 어렵다. 반면에, 주장이 어떤 출처 집합에 의해 얼마나 잘 지지되는지 평가하는 것은 훨씬 쉽다.
- Less noisy feedback. 또한, 임의의 주장의 사실적 정확성을 평가하는 것에 비해, 주장이 어떤 출처 집합에 의해 얼마나 잘 지지되는지 평가하는 명확한 절차를 지정하는 것이 더 쉽다. 이는 라벨러들 간의 합의율을 향상시켜 데이터 효율성을 돕는다.
- Transparency. 전체 브라우징 과정을 검사할 수 있으므로, WebGPT가 어떻게 답변을 구성하는지 이해하는 것이 GPT-3에 비해 훨씬 쉽다. 또한, 최종 사용자가 출처를 추적하여 사실 정확성을 스스로 더 잘 판단하는 것도 간단하다.
참조는 많은 이점이 있지만, 모든 문제를 해결하는 완벽한 방법은 아니다. 현재의 절차는 모델이 설득력 있는 참조를 선택하도록 장려하며, 이는 공정한 증거 평가를 반영하지 않을 수 있다. 이 문제는 더 능력이 뛰어난 모델과 복잡한 질문에 의해 악화될 수 있다. 이를 완화하기 위해, 모델이 다양한 주장에 대해 찬성과 반대의 증거를 모두 찾도록 학습하는 토론 방법 등을 사용할 수 있다.
AI 시스템 학습의 사실적 정확성 평가는 중요한 이슈이다. Evans et al. 의 제안과 현재의 AI 학습 기준은 차이가 있으며, 출처의 신뢰성 평가와 같은 복잡한 판단이 필요하다. WebGPT는 이런 부분을 크게 반영하지 않았지만, AI 발전에 따라 이 결정들은 중요해질 것이다. 따라서 실용적이고 타당한 기준 개발을 위한 다학문적 연구가 필요하다.
Risks of live web access
WebGPT는 학습과 추론 시간에 웹에 실시간으로 접근하여 최신 정보를 제공할 수 있다. 하지만, 이는 사용자와 타인에게 위험을 초래할 수 있다. 예를 들어, 모델이 양식을 다룰 수 있다면, 신뢰성 있는 참고 자료를 만들기 위해 위키피디아를 편집할 수 있다. 심지어 인간 시연자가 그러한 행동을 하지 않더라도, 모델이 우연히 이를 발견하면 강화학습에 의해 강화될 수 있다.
WebGPT가 그 행동의 실세계 부작용을 악용하는 위험성은 매우 낮다. 이는 모델이 할 수 있는 외부 세계와의 상호작용이 Bing API에 쿼리를 보내고 웹에 있는 링크를 따르는 것으로 제한되기 때문이다. 능력이 충분한 시스템은 이러한 권한을 확대할 수 있지만, WebGPT의 능력은 이를 달성하기에는 부족해 보인다.
능력이 뛰어난 모델은 더 큰 위험을 초래할 수 있어, 모델의 능력이 증가함에 따라 웹 접근에 대한 안전성 증명이 중요해진다. 이를 위해, 트립와이어 테스트 등의 방법으로 모델의 악용적인 행동을 조기에 감지할 수 있어야 한다.
Related work
질문-답변 작업을 위해 외부 지식과 머신러닝을 결합하는 것은 사전 학습된 언어 모델 출현 이전부터 있었다. 이런 시스템의 대표적인 예는 Jeopardy에서 인간을 이긴 IBM Watson이다. 최근의 연구들은 문서 검색을 통해 언어 모델로 질문에 답하는 방식을 취하며, 이는 DeepQA보다 더 일반적이고 단순하다. 한 방법으로는 관련 문서를 검색하고 이를 통해 답변을 생성하는 내적 검색을 사용한다.
$$ p(passage∣query) \propto exp(embed(passage) \cdot embed(query))$$
각 질문에 대한 관련 구절을 제공하는 훈련 데이터셋을 사용해, Dense Passage Retrieval(DPR), Retrieval Augmented Language Modeling(REALM), Retrieval Augmented Generation(RAG) 등의 방법들은 검색기를 직접 학습한다. 이들은 짧은 답변에 초점을 맞추는 반면, Krishna et al.은 장문형 질문에 대해 다루기 위해 비슷한 시스템을 사용한다. 그러나 자동화된 지표로는 충분하지 않아, 인간의 비교를 주요 지표로 사용한다. 이들 방법들은 검색을 미분 가능한 과정으로 보는데, 이는 빠른 최적화의 장점이 있지만, 검색 엔진 사용과 같은 비미분 과정을 다루기 어렵고, 해석이 덜 가능하다는 단점이 있다.
최근 연구들은 문서 검색이나 웹 브라우징을 강화학습 문제로 다루고 있다. 이런 연구 중에는 웹 수준의 질문-답변 시스템 개발이나, 읽기 이해 벤치마크에 강화학습을 적용하는 것 등이 포함되어 있다. 또한, 행동 복제나 강화학습을 이용해 웹 브라우저를 제어하는 연구도 진행되고 있다. 이런 연구들은 질문-답변 이외의 다른 작업들을 자동화하는 데에도 활용될 수 있다.
Conclusion
언어 모델을 텍스트 기반 웹 브라우징 환경에 미세조정하여 장문형 질문-답변에 대한 새로운 접근법을 보여주었다. 이 방법은 imitation 학습이나 강화 학습 같은 기법을 사용하여 답변의 질을 직접 최적화할 수 있다. 이 모델은 ELI5에서 인간을 능가하지만, 분포 외 질문에는 여전히 어려움을 겪고 있다.